一、什么是Lambda表达式?
可以把Lambda表达式理解为简洁地表示可传递的匿名函数的一种方式:它没有名称,但它有参数列表、函数主体、返回类型,可能还有一个可以抛出的异常列表。
-
-
函数——和方法一样,Lambda有参数列表、函数主体、返回类型,还可能有可以抛出的异常列表
-
传递——Lambda表达式可以作为参数传递给方法或存储在变量中
-
二、为什么要用Lambda表达式?
想要回答这个问题,应该先了解一下什么是函数式编程。下面是摘自知乎工程师的回答:
编程范式
函数式编程是一种编程范式,我们常见的编程范式有命令式编程(Imperative programming),函数式编程,逻辑式编程,常见的面向对象
编程也是一种命令式编程。
命令式编程是面向计算机硬件的抽象,有变量(对应着存储单元),赋值语句(获取,存储指令),表达式(内存引用和算术运算)和控制语
句(跳转指令),一句话,命令式程序就是一个冯诺依曼机的指令序列。而函数式编程是面向数学的抽象,将计算描述为一种表达式求值,一句话,
函数式程序就是一个表达式。
函数式编程的本质
函数式编程中的函数这个术语不是指计算机中的函数(实际上是Subroutine),而是指数学中的函数,即自变量的映射。也就是说一个函数的
值仅决定于函数参数的值,不依赖其他状态。比如sqrt(x)函数计算x的平方根,只要x不变,不论什么时候调用,调用几次,值都是不变的。
在函数式语言中,函数作为一等公民,可以在任何地方定义,在函数内或函数外,可以作为函数的参数和返回值,可以对函数进行组合。
纯函数式编程语言中的变量也不是命令式编程语言中的变量,即存储状态的单元,而是代数中的变量,即一个值的名称。变量的值是不可变的
(immutable),也就是说不允许像命令式编程语言中那样多次给一个变量赋值。比如说在命令式编程语言我们写“x = x + 1”,这依赖可变状态的
事实,拿给程序员看说是对的,但拿给数学家看,却被认为这个等式为假。
函数式语言的如条件语句,循环语句也不是命令式编程语言中的控制语句,而是函数的语法糖,比如在Scala语言中,if else不是语句而是
三元运算符,是有返回值的。
严格意义上的函数式编程意味着不使用可变的变量,赋值,循环和其他命令式控制结构进行编程。
从理论上说,函数式语言也不是通过冯诺伊曼体系结构的机器上运行的,而是通过λ演算来运行的,就是通过变量替换的方式进行,变量替换为
其值或表达式,函数也替换为其表达式,并根据运算符进行计算。λ演算是图灵完全(Turing completeness)的,但是大多数情况,函数式程序
还是被编译成(冯诺依曼机的)机器语言的指令执行的。
可以参考下面两个链接:
https://www.zhihu.com/question/28292740
http://janfan.cn/chinese/2015/05/18/functional-programming.html
大致了解了函数式编程后,就能理解Lambda表达式的优势。
-
函数式编程是技术的发展方向,而Lambda是函数式编程最基础的内容,所以,Java 8中加入Lambda表达式本身是符合技术发展方向的。
-
通过引入Lambda,最直观的一个改进是,不用再写大量的匿名内部类。事实上,还有更多由于函数式编程本身特性带来的提升。比如:代码的可读性会更好、高阶函数引入了函数组合的概念。
-
此外,因为Lambda的引入,集合操作也得到了极大的改善。比如,引入stream API,把map、reduce、filter这样的基本函数式编程的概念与Java集合结合起来。在大多数情况下,处理集合时,Java程序员可以告别for、while、if这些语句。
-
随之而来的是,map、reduce、filter等操作都可以并行化,在一些条件下,可以提升性能。
三、lambda表达式的结构
-
-
-
-
-
-
表达式主体有一条以上语句时,表达式的返回类型与代码块的返回类型一致
-
表达式只有一条语句时,表达式的返回类型与该语句的返回类型一致
//零个
()-> System.out.println("no argument");
//一个
x->x+1
//两个
(x,y)->x+y
//返回类型是表达式主体语句的返回类型int
(int x)->x+1
//表达式中有多条语句
(Apple appple) -> {
System.out.println(apple.getWeight());
System.out.println(apple.getColor());
}
四、哪里使用及如何使用Lambda表达式
对于java 8,应该在函数式接口上使用Lambda表达式。
4.1、什么是函数式接口?
函数式接口就是只定义一个抽象方法的接口。(PS: java 8中接口有一点变化,就是接口中可以有除了抽象方法之外的默认方法,用default修饰)
public interface Comparator<T> {
int compare(T o1, T o2);
}
public interface Runnable{
void run();
}
函数式接口可以干什么?
Lambda表达式允许直接以内联的形式为函数式接口的抽象方法提供实现,并把整个表达式作为函数式接口的实例(具体说来,是函数式接口一个具体实现的实例。用匿名内部类也可以完成同样的事情,只不过比较笨拙:需要提供一个实现,然后再直接内联将它实例化。
看个例子:
//使用Lambda表达式
Runnable r1 = () -> System.out.println("Hello World 1");
//使用内部类
Runnable r2 = new Runnable(){
public void run(){
System.out.println("Hello World 2");
}
};
4.2、函数描述符
如何从函数式接口到Lambda表达式,这需要引入函数描述符的概念。
函数式接口的抽象方法的签名基本上就是Lambda表达式的签名。我们将这种抽象方法叫作函数描述符。
具体分析一下:
Runnable只有一个run()方法,具体形式是 void run(),代表不接受参数也不返回值,将这个函数描述符和Lambda表达式的结构对应起来,()代表没有参数,System.out.println("Hello World 1")表示不返回值,所以可以得到:
Runnable r1 = () -> System.out.println("Hello World 1");
Comparator有一个compare()方法,具体形式是int compare(T o1, T o2),代表接受两个参数,返回一个整形,将这个函数描述符和Lambda表达式的结构对应起来,(T o1, T o2)代表参数列表,{if (o1.value > o2.value){ retrun 1} else{return -1} },可以得到:
Comparator comp = (T o1, T o2) -> { if (o1.value > o2.value){ retrun 1} else{return -1} }
4.3、java 8新引入的函数式接口
4.3.1、Predicate
java.util.function.Predicate<T>接口定义了一个名叫test的抽象方法,它接受泛型T对象,并返回一个boolean。
//Predicate接口
public interface Predicate<T>{
boolean test(T t);
}
public static <T> List<T> filter(List<T> list, Predicate<T> p) {
List<T> results = new ArrayList<>();
for(T s: list){
if(p.test(s)){
results.add(s);
}
}
return results;
}
Predicate<String> nonEmptyStringPredicate = (String s) -> !s.isEmpty();
List<String> nonEmpty = filter(listOfStrings, nonEmptyStringPredicate);
4.3.2、Consumer
java.util.function.Consumer<T>定义了一个名叫accept的抽象方法,它接受泛型T的对象,没有返回(void)。
如果需要访问类型T的对象,并对其执行某些操作,就可以使用这个接口。比如,可以用它来创建一个forEach方法,接受一个Integers的列表,并对其中每个元素执行操作。
// Consumer接口
public interface Consumer<T>{
void accept(T t);
}
public static <T> void forEach(List<T> list, Consumer<T> c){
for(T i: list){
c.accept(i);
}
}
forEach(Arrays.asList(1,2,3,4,5),(Integer i) -> System.out.println(i));
4.3.3、Function
java.util.function.Function<T, R>接口定义了一个叫作apply的方法,它接受一个泛型T的对象,并返回一个泛型R的对象。如果需要定义一个Lambda,将输入对象的信息映射到输出,就可以使用这个接口(比如提取苹果的重量,或把字符串映射为它的长度)。
//Function接口
public interface Function<T, R>{
R apply(T t);
}
public static <T, R> List<R> map(List<T> list,Function<T, R> f) {
List<R> result = new ArrayList<>();
for(T s: list){
result.add(f.apply(s));
}
return result;
}
// [7, 2, 6]
List<Integer> l = map(Arrays.asList("lambdas","in","action"),(String s) -> s.length());
上面的函数式接口只适用于引用对象,对于基本数据类型,java 8引入了IntPredicat、DoublePredicat、IntConsume、IntFunctio等函数式接口,可以避免进行装箱拆箱的操作。
PS:请注意,任何函数式接口都不允许抛出受检异常(checked exception)。如果需要Lambda表达式来抛出异常,有两种办法:定义一个自己的函数式接口,并声明受检异常,或者把Lambda包在一个try/catch块中。
五、类型检查、类型推断以及限制
5.1、类型检查和类型推断
Lambda表达式可以为函数式接口生成一个实例。然而,Lambda表达式本身并不包含它在实现哪个函数式接口的信息,也就是说同一个Lambda表达式可以是多个函数式接口的实例,这里面就涉及到了类型检查和类型推断。
编译器负责推导 lambda 表达式类型。它利用 lambda 表达式所在上下文所期待的类型进行推导,这个被期待的类型被称为目标类型。通过一个例子看看。
public class Test1 {
public static void main(String[] args) {
List<String> strs = new ArrayList<String>();
strs.add("aaa");
strs.add("bbbb");
strs.add("ccccc");
strs.add("dddddd");
//长度小于5的str
List<String> shortStr = filter(strs, (String str) -> str.length() < 5);
// [aaa, bbbb]
System.out.println(shortStr);
}
public static List<String> filter(List<String> strs, Predicate<String> p){
List<String> filterStr = new ArrayList<>();
for (String str : strs){
if (p.test(str)){
filterStr.add(str);
}
}
return filterStr;
}
}
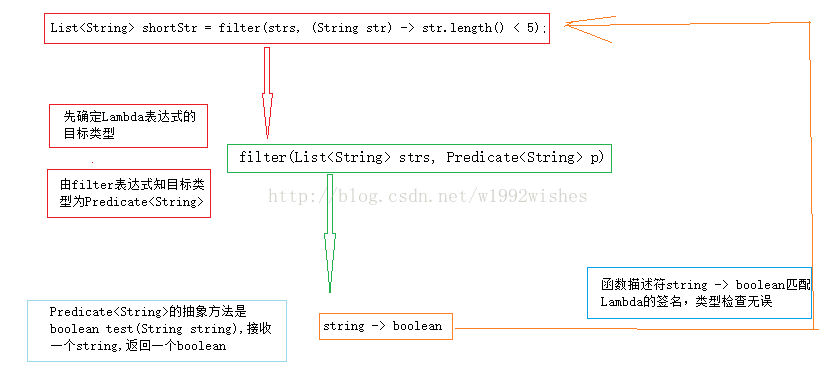
5.2、同样的Lambda,不同的函数式接口
有了目标类型的概念,同一个Lambda表达式就可以与不同的函数式接口联系起来,因为同一个Lambda表达式可以推导出不同的类型,只要类型检查通过,它们的抽象方法签名能够兼容。
比如,Callable和PrivilegedAction,这两个接口都代表着什么也不接受且返回一个泛型T的函数。 因此,下面两个赋值是有效的:
Callable<Integer> c = () -> 42;
PrivilegedAction<Integer> p = () -> 42;
第一个赋值的目标类型是Callable<Integer> , 第二个赋值的目标类型是PrivilegedAction<Integer>。
5.3、Lambda表达式参数类型推断
Java编译器不仅可以从上下文(目标类型)推断出用什么函数式接口来配合Lambda表达式,它也可以推断出适合Lambda的签名。
这样做的好处在于,编译器可以了解Lambda表达式的参数类型,这样就可以在Lambda语法中省去标注参数类型。换句话说,Java编译器可以推断Lambda的参数类型。
List<String> shortStr = filter(strs, (str) -> str.length() < 5);
Comparator<String> c = (str1, str2) -> str1.length().compareTo(str2.length());
但并不是说省略参数类型就是好的,有时候显式写出类型更易读,有时候去掉它们更易读。这需要判断。
六 、Lambda表达式作用域
先看一段代码:
package com.wan.test
public class Test2 {
Runnable r1 = () -> System.out.println(this);
Runnable r2 = () -> System.out.println(toString());
Runnable r3 = new Runnable() {
@Override
public void run() {
System.out.println(this);
}
};
Runnable r4 = new Runnable() {
@Override
public void run() {
System.out.println(toString());
}
};
public String toString() { return "Hello, world"; }
public static void main(String... args) {
new Test2().r1.run();
new Test2().r2.run();
new Test2().r3.run();
new Test2().r4.run();
}
}
结果是:
Hello, world
Hello, world
com.wan.test.Test2$1@41629346
com.wan.test.Test2$2@404b9385
在Lambda表达式中访问外层作用域和匿名对象中的方式类似,可以直接访问标记了final的外层局部变量,或者实例的字段以及静态变量,但上面的代码Lambda表达式和内部类呈现出不同的结果,是因为:
-
内部类中通过继承得到的成员(包括来自Object的方法)可能会把外部类的成员掩盖(shadow),此外未限定(unqualified)的this引用会指向内部类自己而非外部类。
-
相对于内部类,lambda 表达式的语义就十分简单:它不会从超类(supertype)中继承任何变量名,也不会引入一个新的作用域。也就是说 lambda 表达式函数体里面的变量和它外部环境的变量具有相同的语义(也包括 lambda 表达式的形式参数)。此外,’this’ 关键字及其引用在 lambda 表达式内部和外部也拥有相同的语义。
lambda 表达式不可以掩盖任何其所在上下文中的局部变量,它的行为和那些拥有参数的控制流结构(例如for循环和catch从句)一致。
int i = 0;
//for循环中i应被声明,会编译报错
for (int i=0; i<10; i++){}
6.1、捕获变量
Callable<String> helloCallable1(String name){
String hello = "hello";
return () -> (hello + "," + name);
}
//这段代码在JAVA 7中编译报错, JAVA 8则正确
Callable<String> helloCallable2(String name){
String hello = "hello";
return new Callable<String>() {
@Override
public String call() throws Exception {
return hello + name;
}
};
}
在 Java SE 7 中,编译器对内部类中引用的外部变量(即捕获的变量)要求非常严格:如果捕获的变量没有被声明为final就会产生一个编译错误。现在放宽了这个限制——对于 lambda 表达式和内部类,允许在其中捕获那些符合有效只读(Effectively final)的局部变量。
简单的说,如果一个局部变量在初始化后从未被修改过,那么它就符合有效只读的要求,换句话说,加上final后也不会导致编译错误的局部变量就是有效只读变量。
对this的引用,以及通过this对未限定字段的引用和未限定方法的调用在本质上都属于使用final局部变量。包含此类引用的 lambda 表达式相当于捕获了this实例。在其它情况下,lambda 对象不会保留任何对this的引用。
这个特性对内存管理是一件好事:内部类实例会一直保留一个对其外部类实例的强引用,而那些没有捕获外部类成员的 lambda 表达式则不会保留对外部类实例的引用。要知道内部类的这个特性往往会造成内存泄露。
尽管放宽了对捕获变量的语法限制,但试图修改捕获变量的行为仍然会被禁止,比如下面这个例子就是非法的:
Callable<String> helloCallable1(String name){
String hello = "hello";
//试图修改捕获变量
hello = "hi";
return () -> (hello + "," + name);
}
6.2、Lambda表达式变量使用总结
-
Lambda可以没有限制地捕获(也就是在其主体中引用)实例变量和静态变量。
-
Lambda表达式不会从超类中继承任何变量名,也不会引入一个新的作用域。 lambda 表达式函数体里面的变量和它外部环境的变量具有相同的语义。
-
局部变量必须显式声明为final,或事实上是final。换句话说,Lambda表达式只能捕获指派给它们的局部变量一次。
七、方法引用
lambda 表达式允许定义一个匿名方法,并允许以函数式接口的方式使用它,方法引用则能够在已有的方法上实现同样的特性。
方法引用和 lambda 表达式拥有相同的特性(例如,它们都需要一个目标类型,并需要被转化为函数式接口的实例),不过并不需要为方法引用提供方法体,可以直接通过方法名称引用已有方法。
需要使用方法引用时,目标引用放在分隔符::前,方法的名称放在后面。
public class Test3 {
public static void main(String[] args) {
Person p1 = new Person("a", 11);
Person p2 = new Person("b", 21);
Person p3 = new Person("c", 31);
Person p4 = new Person("d", 41);
Person p5 = new Person("e", 51);
Person p6 = new Person("f", 42);
Person p7 = new Person("g", 32);
Person p8 = new Person("h", 22);
Person p9 = new Person("i", 12);
Person[] people = { p1, p2, p3, p4, p5, p6, p7, p8, p9 };
System.out.println(people[3]);
Comparator<Person> byAge = Comparator.comparing(p -> p.getAge());
Arrays.sort(people, byAge);
System.out.println(people[3]);
}
}
class Person{
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String toString(){
return this.name + " : " + this.age;
}
}
这里可以用方法引用代替Lambda表达式:
//lambda方式
Comparator<Person> byAge = Comparator.comparing(p -> p.getAge());
//方法引用
Comparator<Person> byAge = Comparator.comparing(Person::getAge);
Person::getAge可以被看作为 lambda 表达式的简写形式。尽管方法引用不一定会把语法变的更紧凑,但它拥有更明确的语义——如果一个Lambda代表的只是“直接调用这个方法”,那最好还是用名称来调用它,而不是去描述如何调用它。
7.1、如何构建方法引用
主要有四类:
-
指向静态方法的方法引用(例如Integer的parseInt方法,写作Integer::parseInt)。
-
指向任意类型实例方法的方法引用( 例如String 的length 方法, 写作String::length)。
-
指向现有对象的实例方法的方法引用(假设局部变量expensiveTransaction用于存放Transaction类型的对象,它支持实例方法getValue,那么可以写expensiveTransaction::getValue)。
-
对于一个现有构造函数,可以利用它的名称和关键字new来创建它的一个引用:
ClassName::new。
八、Lambda表达式演化实例
现有很多苹果,要对这些苹果按照重量进行排序。(这里用到了JAVA 8中List接口中新增的默认方法sort()):
default void sort(Comparator<? super E> c)
默认方法:
lambda 表达式和方法引用大大提升了 Java 的表达能力(expressiveness),不过为了使把代码即数据(code-as-data)变的更加容易,需要把这些特性融入到已有的库之中,以便开发者使用。
Java SE 7 时代为一个已有的类库增加功能是非常困难的。具体的说,接口在发布之后就已经被定型,除非能够一次性更新所有该接口的实现,否则向接口添加方法就会破坏现有的接口实现,这显然是不现实的。默认方法(之前被称为虚拟扩展方法或守护方法)的目标即是解决这个问题,使得接口在发布之后仍能被逐步演化。
默认方法利用面向对象的方式向接口增加新的行为。它是一种新的方法:接口方法可以是抽象的或是默认的。默认方法拥有其默认实现,实现接口的类型通过继承得到该默认实现(如果类型没有覆盖该默认实现)。此外,默认方法不是抽象方法,所以可以放心的向函数式接口里增加默认方法,而不用担心函数式接口的单抽象方法限制。
Apple类:
public class Apple{
private Double weight;
public Apple(Double weight){
this.weight = weight;
}
public Double getWeight() {
return weight;
}
public void setWeight(Double weight) {
this.weight = weight;
}
public String toString(){
return this.weight + "";
}
}
8.1、第一种策略:实现接口
public class Test4 {
public static void main(String[] args) {
List<Apple> inventory = new ArrayList<>();
inventory.add(new Apple(0.2));
inventory.add(new Apple(0.33));
inventory.add(new Apple(0.25));
inventory.add(new Apple(0.19));
inventory.add(new Apple(0.3));
System.out.println(inventory);
//排序
inventory.sort(new AppleComparaor());
//排序后
System.out.println(inventory);
}
}
class AppleComparaor implements Comparator<Apple>{
@Override
public int compare(Apple a1, Apple a2) {
return a1.getWeight().compareTo(a2.getWeight());
}
}
8.2、第二种策略:使用匿名内部类
public class Test5 {
public static void main(String[] args) {
List<Apple> inventory = new ArrayList<>();
inventory.add(new Apple(0.2));
inventory.add(new Apple(0.33));
inventory.add(new Apple(0.25));
inventory.add(new Apple(0.19));
inventory.add(new Apple(0.3));
System.out.println(inventory);
//排序
inventory.sort(new Comparator<Apple>() {
@Override
public int compare(Apple a1, Apple a2) {
return a1.getWeight().compareTo(a2.getWeight());
}
});
//排序后
System.out.println(inventory);
}
}
8.3、第三种策略:使用Lambda表达式
public class Test6 {
public static void main(String[] args) {
List<Apple> inventory = new ArrayList<>();
inventory.add(new Apple(0.2));
inventory.add(new Apple(0.33));
inventory.add(new Apple(0.25));
inventory.add(new Apple(0.19));
inventory.add(new Apple(0.3));
System.out.println(inventory);
//排序
inventory.sort( (a1, a2) -> a1.getWeight().compareTo(a2.getWeight()));
//排序后
System.out.println(inventory);
}
}
这里java编译器能够根据Lambda表达式上下文推导出参数类型。
Comparator中有一个静态方法comparing(),可以用来进一步简化Lambda表达式(PS: java 8之前是不支持接口中包含静态方法的,java中为了支持Lambda表达式,接口中已经支持静态方法)
static <T, U> Comparator<T> comparing(...)
//排序
Comparator<Apple> c = Comparator.comparing( a -> a.getWeight() );
inventory.sort( c );
所以变为:
public class Test7 {
public static void main(String[] args) {
List<Apple> inventory = new ArrayList<>();
inventory.add(new Apple(0.2));
inventory.add(new Apple(0.33));
inventory.add(new Apple(0.25));
inventory.add(new Apple(0.19));
inventory.add(new Apple(0.3));
System.out.println(inventory);
//排序 import static java.util.Comparator.comparing
inventory.sort(comparing(apple -> apple.getWeight()));
//排序后
System.out.println(inventory);
}
}
8.4、第四种策略:方法引用
public class Test8 {
public static void main(String[] args) {
List<Apple> inventory = new ArrayList<>();
inventory.add(new Apple(0.2));
inventory.add(new Apple(0.33));
inventory.add(new Apple(0.25));
inventory.add(new Apple(0.19));
inventory.add(new Apple(0.3));
System.out.println(inventory);
//排序
inventory.sort(comparing(Apple::getWeight));
//排序后
System.out.println(inventory);
}
}
九、复合Lambda表达式
可以把多个简单的Lambda复合成复杂的表达式。比如,可以让两个谓词之间做一个or操作,组合成一个更大的谓词。而且,还可以让一个函数的结果成为另一个函数的输入。
9.1、比较器复合
inventory.sort(comparing(Apple::getWeight)).reversed();//按重量逆序排列
// 在Apple中新增加shape属性,实现重量相同时按shape排序
inventory.sort(comparing(Apple::getWeight)).reversed().thenComparing(Apple::getShape);
9.2、谓词复合
谓词接口包括三个方法:negate、and和or,可以重用已有的Predicate来创建更复 杂的谓词。
Predicate<Apple> redApple = a -> a.getColor().equals("red");
Predicate<Apple> redAndHeavyAppleOrGreen =
redApple
.and(a -> a.getWeight() > 0.4)
.or(a -> "green".equals(a.getColor()));
9.3、函数复合
Function<Integer, Integer> f1 = x -> x+1;
Function<Integer, Integer> f2 = x -> x*2;
Function<Integer, Integer> h = f1.andThen(f2);
int result = h.apply(1);
一个具体一点的例子:
public class Test9 {
public static void main(String[] args) {
Function<String, String> addHeader = Letter::addHeader;
//加抬头、落款并检查
Function<String, String> transformationPipeline1 =
addHeader.andThen(Letter::addFooter)
.andThen(Letter::checkSpelling);
//加抬头、落款不做检查
Function<String, String> transformationPipeline2 =
addHeader.andThen(Letter::addFooter);
}
}
class Letter{
public static String addHeader(String text){
return "From Wan" + text;
}
public static String addFooter(String text){
return "Kind regards" + text;
}
public static String checkSpelling(String text){
return text.replaceAll("lamdba", "lambda");
}
}






















 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









