







一、介绍
Prometheus 是当下最流行的监控平台之一,它的主要职责是
- 从各个目标节点中采集监控数据
- 将数据持久化到本地的时序数据库中
- 向外部提供便捷的查询接口
- 将告警消息推送到AlertManager
Prometheus 目前是监控领域比较成熟的一站式方案。Prometheus与其他监控方案的不同之处在于它是定时地从监控目标(Exporters)暴露的API中拉取指标,如果是监控目标是动态的,可以借助服务发现的机制动态地添加这些监控目标,另外它还会暴露执行PromQL(用来操纵时序数据的语言)的API,其他组件,例如Prometheus Web,Grafana可以通过这个API查询对应的时序数据。虽然 Exporters 在采集端做了预聚合,这样损失了精确度,但大大减少数据量以及提升查询速度。
当前使用的prometheus版本是:2.37.0
promethus为什么那么火?和zhangyu沟通主要有几个原因:
- promQL语言:这个应该是很火的主要原因,确实很好用
- promethus支持云原生环境下容器随时启停场景:promethus没有节点概念,所有都是tag,因此节点启停是没有影响的
- 历史原因:promethus是和K8S强绑定的监控系统,K8S火了,所以promethus也火了
二、特点
1、多维数据模型:由度量名称和键值对标识的时间序列数据
2、PromSQL:一种灵活的查询语言,可以利用多维数据完成复杂的查询
3、不依赖分布式存储,单个服务器节点可直接工作
4、基于HTTP的pull方式采集时间序列数据
- 相较于push模式,pull模式让监控和应用服务解耦
- 相较于push模式,pull模式更容易发现应用是否健康
5、推送时间序列数据通过PushGateway组件支持
6、通过服务发现或静态配置发现目标
7、多种图形模式及仪表盘支持(grafana)
8、适用于以机器为中心的监控以及高度动态面向服务架构的监控
三、架构与组件
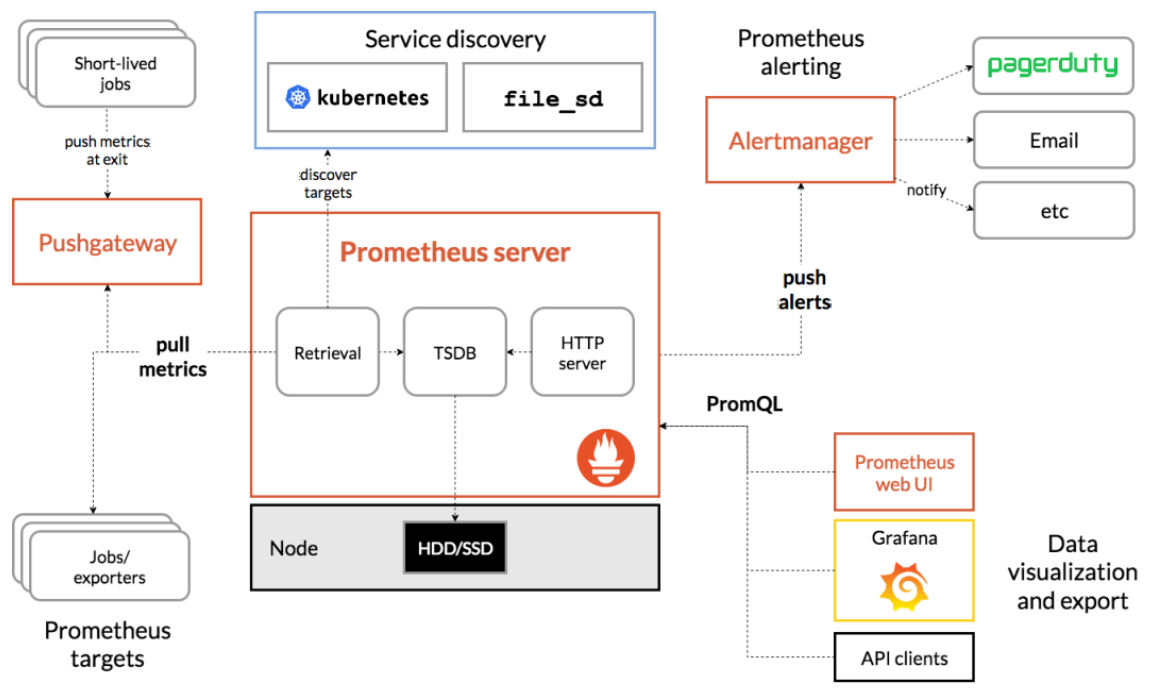
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。
目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
从上图可以看出,Prometheus 的主要模块包括:Prometheus server, exporters, Pushgateway, PromQL, Alertmanager 以及图形界面。
最左边这块就是采集的,主要包括exporters和Pushgateway。
- Exporters:采集已有的第三方服务监控指标并暴露metrics,相当于一个采集端的agent,说白了就是我们自己的服务或应用,比如hubble-biz-cm就是一个Exporter,其暴露了metrics接口。之后Prometheus server也会此接口拉取数据。
- Pushgateway:客户端将监控数据主动推送到Pushgateway,之后Prometheus server也会从Pushgateway拉取数据。主要用于临时性的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。对此Jobs定时将指标push到pushgateway,再由Prometheus Server从Pushgateway上pull。
中间这块就是Prometheus它本身:内部是有一个TSDB的数据库的,从内部的采集和展示Prometheus它都可以完成,展示这块自己的这块UI比较lou,所以借助于这个开源的Grafana来展示,所有的被监控端暴露完指标之后,Prometheus会主动的抓取这些指标,存储到自己TSDB数据库里面,提供给Web UI,或者Grafana,或者API clients通过PromQL来调用这些数据,PromQL相当于Mysql的SQL,主要是查询这些数据的。
中间上面这块是做服务发现的,也就是你有很多的被监控端时,手动的去写这些被监控端是不现实的,所以需要自动的去发现新加入的节点,或者以批量的节点,加入到这个监控中,K8S内置了服务发现机制,也就是Promethus会连接k8s的API,去发现你部署的哪些应用,哪些pod,通通的都给你暴露出去,监控出来,也就是为什么K8S对prometheus特别友好的地方,也就是它内置了做这种相关的支持了。
右上角是Prometheus的告警,即Alertmanager,:从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。hubble的实现是将Alertmanager的告警发给adapter,然后转发给Alarm组件。
小结:
• Prometheus Server:收集指标和存储时间序列数据,并提供查询接口
• ClientLibrary:客户端库,这些可以集成一些很多的语言中,比如使用JAVA开发的一个Web网站,那么可以集成JAVA的客户端,去暴露相关的指标,暴露自身的指标,但很多的业务指标需要开发去写的,
• Web UI:Prometheus内置一个简单的Web控制台,可以查询指标,查看配置信息或者Service Discovery等,实际工作中,查看指标或者创建仪表盘通常使用Grafana,Prometheus作为Grafana的数据源;
四、Pushgateway工作原理
Prometheus Pushgateway 是 Prometheus 生态系统中的一个组件,它允许短期运行的工作 (jobs) 推送(push)其指标到一个中间服务,该服务随后会被 Prometheus 服务器拉取(scrape)。这主要解决了 Prometheus 原生的拉取(pull)模式在处理短期任务、批处理作业或不容易被动态发现的指标时的不足。
工作原理
-
接收指标: Pushgateway 作为一个中间服务,它提供了一个 HTTP API,允许不同的服务和工作(job)通过 POST 请求推送 Metrics 至 Pushgateway。此时,推送的 Metric 数据会在 Pushgateway 中暂存。
-
存储指标: Pushgateway 将接收到的指标暂存于内存中,并且会保持这些指标,直到它们被推送(覆盖)更新或是手动删除,确保即使原始工作(job)已经终止,其指标数据仍然可用。
-
暴露指标: 存储在 Pushgateway 中的指标数据会通过一个端点
/metrics暴露出来,该端点类似于 Prometheus 用于从其他服务拉取数据时所访问的端点。 -
拉取指标: Prometheus 服务器通过配置中的抓取(scrape)配置定期地向 Pushgateway 发起 HTTP GET 请求到
/metrics端点,从而拉取这些已经推送并暂存的指标。 -
存储于 Prometheus: Prometheus 服务器拉取下来的指标会被存储起来并按照正常的方式进行处理。从这一刻起,这些指标数据就和从其他任何正常抓取目标得到的数据一样了。
组件角色
在这个过程中,每个组件的角色如下:
- 短期运行的工作或批处理作业负责在执行过程中计算它们的指标,并在执行完成之前推送这些指标到 Pushgateway。
- Pushgateway 起到临时存储的作用站,它暂时保存短期工作推送的指标数据,并使它们能被 Prometheus 服务器定期拉取。
- Prometheus 服务器 会定期从 Pushgateway 彩下标数据,就像它从其他抓取目标做的那样,区别仅仅是数据的来源变成了 Pushgateway 提供的端点。
适用场景和限制
推送指标到 Pushgateway 非常适合于批处理作业或一些临时的工作,这些任务一旦完成他们就不再存在,因此无法通过 Prometheus 常规的拉取模式进行抓取。然而,使用 Pushgateway 并不适合作为长期运行工作的常规指标推送手段,并且 Pushgateway 也不支持删除已推送指标的自动过期和清理,这需要用户自己管理。
不过,建议尽量避免过度依赖 Pushgateway,因为过多地使用它可能会增加系统的复杂性并对 Pushgateway 产生较大压力,从而影响 Prometheus 执行监控的性能。只有当 Prometheus 的主动拉取模式不适用时,才考虑使用 Pushgateway。
四、Prometheus工作流程
- Prometheus server 定期从配置好的 jobs 或者 exporters 中拉取 metrics,或者从Pushgateway 拉取metrics,或者从其他的 Prometheus server 中拉 metrics。
- Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,通过一定规则进行清理和整理数据,并把得到的结果存储到新的时间序列中。记录新的时间序列或者向 Alertmanager 推送警报。
- Prometheus通过PromQL和其他API可视化地展示收集的数据。Prometheus支持很多方式的图表可视化,例如Grafana、自带的Promdash以及自身提供的模版引擎等等。Prometheus还提供HTTP API的查询方式,自定义所需要的输出。
五、服务发现
单独整理文章:https://my.oschina.net/weiweiblog/blog/5354796
六、业务对接
当前我们对外提供服务的方式是为每个业务部署一个Promethus集群。
当前每个业务会部署一个或多个Prometheus服务,但是不同业务一定是不同的Prometheus服务,所以最终产生的数据中一般不需要加业务信息
当前超过200个Prometheus server
七、Prometheus 数据模型
时序数据库是 Promtheus 监控平台的一部分,有着非常高效的时间序列数据存储方法,每个采样数据仅仅占用3.5byte左右空间
在早期有一个单独的项目叫做 TSDB,但是,在2.1.x的某个版本,已经不单独维护这个项目了,直接将这个项目合并到了prometheus的主干上了
Prometheus将所有数据存储为时间序列;具有相同度量名称以及标签属于同一个指标。
每个时间序列都由度量标准名称和一组键值对(也成为标签)唯一标识。
时间序列格式:
<metric name>{<label name>=<label value>, ...}
示例:
api_http_requests_total{method="POST", handler="/messages"}
八、Prometheus 指标类型
• Counter:递增的计数器
适合:API 接口请求次数,重试次数。
• Gauge:可以任意变化的数值
适合:cpu变化,类似波浪线不均匀。
• Histogram:对一段时间范围内数据进行采样,并对所有数值求和与统计数量、柱状图
适合:将web 一段时间进行分组,根据标签度量名称,统计这段时间这个度量名称有多少条。
适合:某个时间对某个度量值,分组,一段时间http相应大小,请求耗时的时间。
• Summary:与Histogram类似
九、PromQL
1、介绍
PromQL(Prometheus Query Language)是 Prometheus 自己开发的表达式语言,语言表现力很丰富,内置函数也很多。使用它可以对时序数据进行筛选和聚合。在日常数据可视化以及rule 告警中都会使用到它。
2、查询结果类型
PromQL 查询结果主要有 3 种类型:
- 瞬时数据 (Instant vector): 包含一组时序,每个时序只有一个点,例如:
http_requests_total - 区间数据 (Range vector): 包含一组时序,每个时序有多个点,例如:
http_requests_total[5m] - 纯量数据 (Scalar): 纯量只有一个数字,没有时序,例如:
count(http_requests_total)
3、正则支持
查询条件支持正则匹配,例如:
http_requests_total{code!="200"} // 表示查询 code 不为 "200" 的数据
http_requests_total{code=~"2.."} // 表示查询 code 为 "2xx" 的数据
http_requests_total{code!~"2.."} // 表示查询 code 不为 "2xx" 的数据4、操作符
Prometheus 查询语句中,支持常见的各种表达式操作符,例如
算术运算符:支持的算术运算符有 +,-,*,/,%,^, 例如 http_requests_total * 2 表示将 http_requests_total 所有数据 double 一倍。
比较运算符:支持的比较运算符有 ==,!=,>,<,>=,<=, 例如 http_requests_total > 100 表示 http_requests_total 结果中大于 100 的数据。
逻辑运算符:支持的逻辑运算符有 and,or,unless(排除), 例如 http_requests_total == 5 or http_requests_total == 2 表示 http_requests_total 结果中等于 5 或者 2 的数据。
聚合运算符:支持的聚合运算符有 sum,min,max,avg,stddev,stdvar,count,count_values,bottomk,topk,quantile,, 例如 max(http_requests_total) 表示 http_requests_total 结果中最大的数据。
注意,和四则运算类型,Prometheus 的运算符也有优先级,它们遵从(^)> (*, /, %) > (+, -) > (==, !=, <=, <, >=, >) > (and, unless) > (or) 的原则。
5、内置函数
参考单独整理的文章
https://my.oschina.net/weiweiblog/blog/5350330
十、up指标
Promethus有个很重要的up指标,我们经常会用这个指标去监控实例有没有挂
如果实例挂了,up指标对应的值为0,如果实例正常,up指标对应的值为1
十一、配置文件
参考单独整理的文章:包含配置文件模板,告警规则配置,数据聚合规则配置等
https://my.oschina.net/weiweiblog/blog/5348840
十二、WebUI介绍
功能:
1、数据查询
包含瞬时数据和graph
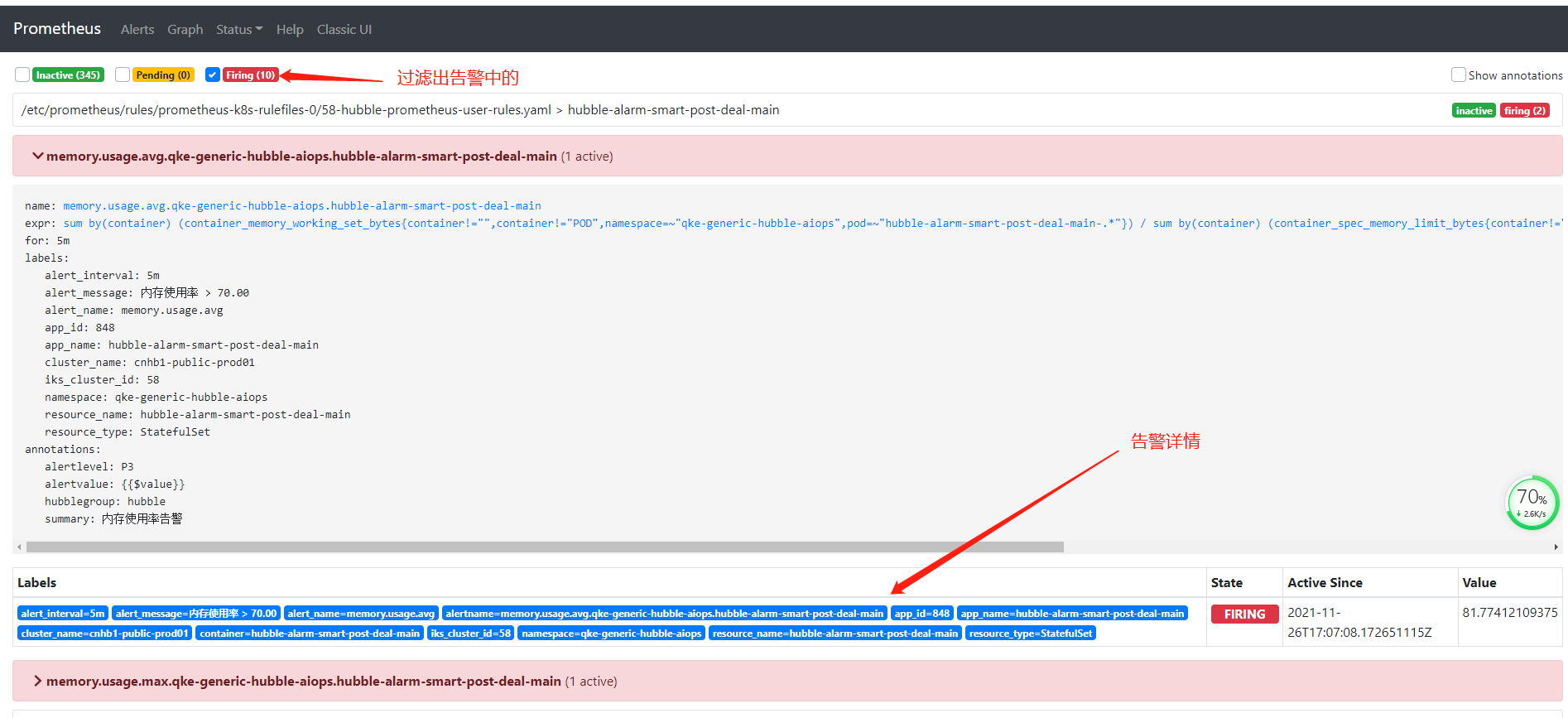
2、告警信息查询
3、status
基础环境
配置文件
告警规则配置
命令行日志
targets:抓取的所有目标
十三、哪里创建或修改配置文件?
1、通过在rancher上修改;
通过Rancher进入k8s管理界面,选择正确的业务项目,然后点击 “资源 -> 配置映射” 进入ConfigMap管理界面,找到prometheus-config-tmpl,并点击 “升级”
点击升级后会进入ConfigMap修改界面,可以直接修改下图右侧文本框中内容,修改完成后点击 “保存”,后台会自动进行更新
2、通过接口修改
通过API直接添加/修改/删除某个Prometheus服务的scrape_config配置。
文档中提供了修改的URL。
十四、prometheus部署
我们是申请了16台物理机,三台虚拟机部署了一个K8S集群。
然后有业务申请prometheus服务的时候,将服务部署在我们申请的K8S集群上。
背景
尽管监控平台目前已经覆盖了公司内部大部分基础监控和业务服务监控,但它是基于open-falcon进行的二次开发,比较适合物理机和虚机环境上的监控,在容器方面的监控暂时还不能很好支持,尤其在kubernets集群中对容器资源、业务服务等需要动态发现的监控。
部署
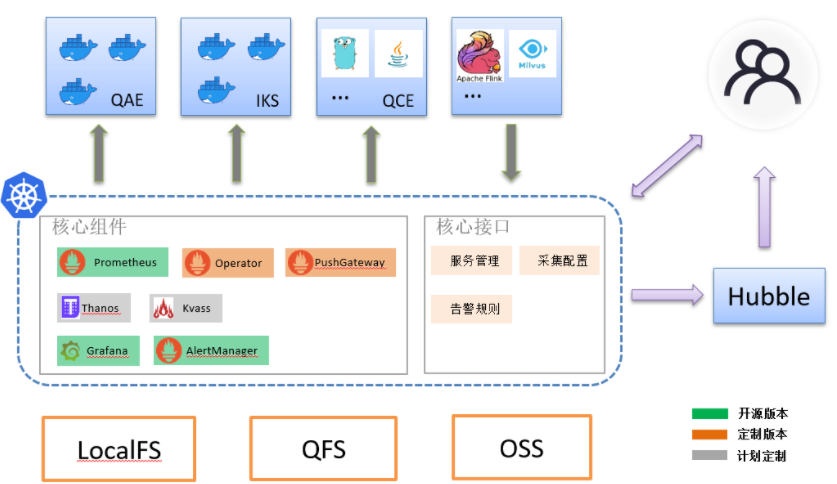
当前qke的部署是每个业务不是一个promethus实例服务,一个promethus operater,如下:
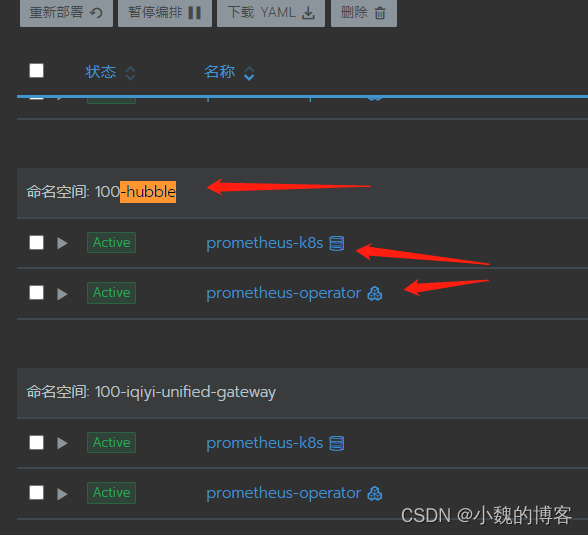
另外,每个qke集群,对应一个promethus集群。所以,如果qke新增一个K8S集群的话,我们也要新增一个promethus集群与之对应。
qke的pod和容器指标默认采集:我们会默认给每个项目的每个QKE集群创建prometheus集群,创建集群的时候,我们会默认创建三个ServiceMonitor,如下图所示:
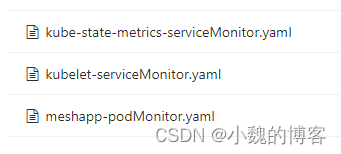
指标说明:
- 容器指标:这是由k8s的kubelet组件采集保留给prometheus,然后我们创建prometheus集群的时候,默认配置上次job
- pod指标:
容器指标配置:
- job_name: qke-generic-hubble-platform/kubelet/0
honor_labels: true
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 30s
metrics_path: /metrics/cadvisor
scheme: https
bearer_token_file: /var/k8s-auth/tokenPOD指标配置:
- job_name: qke-generic-hubble-platform/kube-state-metrics/0
honor_labels: true
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 30s
metrics_path: /metrics
scheme: https
bearer_token_file: /var/k8s-auth/token十五、Prometheus Operator
由于 Prometheus 本身没有提供管理配置的 API 接口(尤其是管理监控目标和管理警报规则),也没有提供好用的多实例管理手段,因此这一块往往要自己写一些代码或脚本。
什么是 Operator?Operator = Controller + CRD。假如你不了解什么是 Controller 和 CRD,可以看一个 Kubernetes 本身的例子:我们提交一个 Deployment 对象来声明期望状态,比如 3 个副本;而 Kubernetes 的 Controller 会不断地干活(跑控制循环)来达成期望状态,比如看到只有 2 个副本就创建一个,看到有 4 个副本了就删除一个。在这里,Deployment 是 Kubernetes 本身的 API 对象。那假如我们想自己设计一些 API 对象来完成需求呢?Kubernetes 本身提供了 CRD(Custom Resource Definition),允许我们定义新的 API 对象。但在定义完之后,Kubernetes 本身当然不可能知道这些 API 对象的期望状态该如何到达。这时,我们就要写对应的 Controller 去实现这个逻辑。而这种自定义 API 对象 + 自己写 Controller 去解决问题的模式,就是 Operator Pattern。
十六、NAN问题解决
一般我们写prometheus函数的时候,经常会遇到NAN情况,如分母为0就会导致。
那么如何解决呢?
有一种方式为在结果后面加上 " > 0 ",这样就会剔除NAN的数据
十七、Prometheus的集群部署
promethus集群部署主要有几种方式:
1、联邦集群方式
这是promethus官方自带的fan
【URL】 Federation | Prometheus
【原理】 基于prometheus联邦集群方式,部署多个prometheus实例抓取不同分片的监控数据,最后通过全局的prometheus从各分片prometheus上抓取监控数据汇总起来。
promethus自身其实也是个exporter,其它promethus实例可以通过这个exporter进行采集数据。
注意:联邦的方式一般要求只采集自己需要的数据,要不然所有promethus实例的数据汇总到一个promethus实例上,会导致顶部promethus实例性能问题。
【优缺点】
优点:
- prometheus原生支持,无第三方依赖,部署简单
- 可根据业务需求自由分片,配置灵活度高
缺点:
- 需要单独维护各分片prometheus配置
- 需要人工设计和配置进行各分片Prometheus负载均衡
- 全局prometheus不能包含全量数据,只能抓取业务需要汇总的部分数据
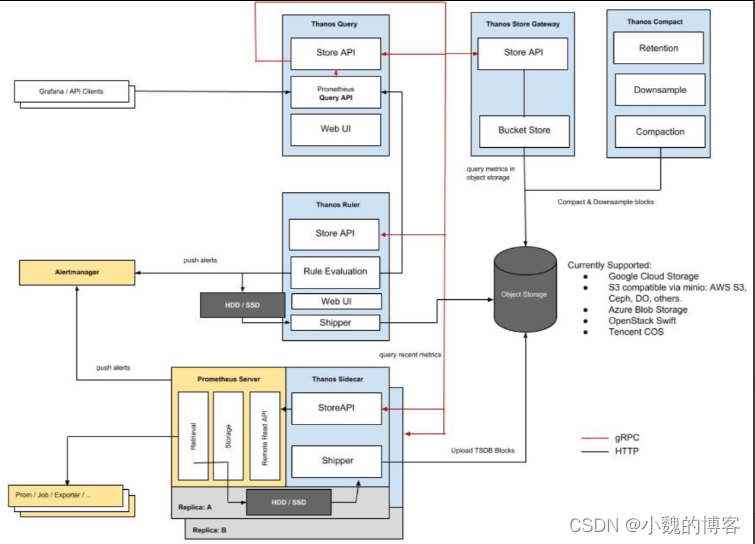
2、Thanos
【URL】https://github.com/thanos-io/thanos
【原理】Thanos更多关注的是prometheus多副本HA 和 超长期数据存储,但是我们也可以通过它实现横向扩展的prometheus集群,只是将prometheus多副本的配置进行差异化管理(类似联邦方式中的分片prometheus)。
每个promethus实例部署一个sidecar,将promethus数据存储到云存储。
这种使用方式,我们一般不需要在promethus实例上存很久,否则就冗余了。
数据查询的时候,业务其实是查多个thanos的sidecar,然后将数据进行汇总。
【优缺点】
优点:
- 超长期数据存储
- 支持全局查询和全局告警
- 支持下采样
缺点:
- 需要单独维护各分片prometheus配置
- 需要人工设计和配置进行各分片Prometheus负载均衡
- 依赖对象存储
【架构图】
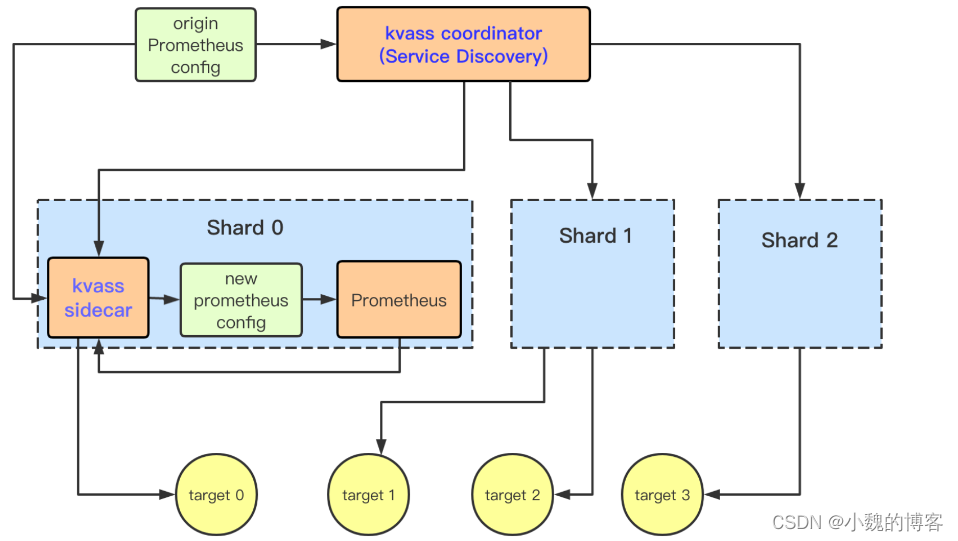
3、Kvass
kvass为腾讯开源
【URL】https://github.com/tkestack/kvass/blob/master/README_CN.md
【原理】Kvass主要由coordinator和sidecar两个组件组成,coordinator根据prometheus的配置文件进行服务发现,然后将发现到的targets进行分析和评估,计算需要prometheus分片数量并启动对应的prometheus实例,将targets的抓取任务分组下发到不同分片里的sidecar组件,由sidecar负载生成对应分片内的prometheus配置文件。
说白了,初始promethus配置的job很多,kvass会将这些job经过计算平均的拆开,然后部署不同的promethus配置不同的job。
【优缺点】
优点:
- 只需维护一套全局prometheus配置
- 根据target实际数据规模来进行分片负载均衡
- 自动横向扩容
缺点:
- 暂不支持缩容
- 全局存储和查询依赖第三方
- target与分片关系不透明
- 仅支持static和k8s服务发现
【架构图】
参考:















 412
412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









