







 本文介绍了Kubernetes监控中PrometheusOperator的角色和工作原理,如何通过ServiceMonitor进行服务发现,并阐述了PrometheusOperator与Prometheus服务发现的区别与联系。此外,还提及了kube-state-metrics和node-exporter在监控中的作用,以及Kubernetes核心组件的/metrics端点。文章强调了PrometheusOperator简化了Prometheus在Kubernetes环境中的部署和管理,通过CRD资源自动化配置监控系统。
本文介绍了Kubernetes监控中PrometheusOperator的角色和工作原理,如何通过ServiceMonitor进行服务发现,并阐述了PrometheusOperator与Prometheus服务发现的区别与联系。此外,还提及了kube-state-metrics和node-exporter在监控中的作用,以及Kubernetes核心组件的/metrics端点。文章强调了PrometheusOperator简化了Prometheus在Kubernetes环境中的部署和管理,通过CRD资源自动化配置监控系统。
一、背景
随着云原生概念盛行,对于容器、服务、节点以及集群的监控变得越来越重要。Prometheus作为Kubernetes监控的事实标准,有着强大的功能和良好的生态。但是它不支持分布式,不支持数据导入、导出,不支持通过API修改监控目标和报警规则,所以在使用它时,通常需要写脚本和代码来简化操作。
二、Operator介绍
Operator是由CoreOS公司开发的用来扩展Kubernetes API的特定应用程序控制器,用来创建、配置和管理复杂的有状态应用,例如数据库、缓存和监控系统。Operator基于kubernetes的资源和控制器概念上构建,但同时又包含了应用程序特定的领域知识。创建Operator的关键是CRD(自定义资源)的设计。
Operator是将运维人员对软件操作的知识代码化,同时利用Kubernetes强大的抽象来管理大规模的软件应用。目前CoreOS官方提供了几种Operator的实现,其中就包括了Prometheus Operator。
Operator的核心实现是基于Kubernetes的以下两个概念:
- 资源:对象的状态定义
- 控制器:观测、分析和行动,以调节资源的分布
当前CoreOS提供了四种Operator:
- etcd:创建etcd集群
- Rook:云原生环境下的文件、块、对象存储服务
- Prometheus:创建Prometheus监控实例
- Tectonic:部署Kubernetes集群
三、Prometheus Operator介绍
Prometheus Operator为监控Kubernetes Service、Deployment和Prometheus实例的管理提供了简单的定义,简化在Kubernetes上部署、管理和运行Prometheus和Alertmanager集群。
Prometheus Operator作为一个控制器,他会去创建Prometheus、PodMonitor、ServiceMonitor、AlertManager以及PrometheusRule这5个CRD资源对象,然后会一直监控并维持这5个资源对象的状态。
- Prometheus资源对象是作为Prometheus Service存在的
- ServiceMonitor和PodMonitor资源对象是专门的提供metrics数据接口的exporter的抽象,Prometheus就是通过PodMonitor和ServiceMonitor提供的metrics数据接口去pull数据的
- AlertManager资源对象对应的是alertmanager组件
- PrometheusRule资源对象是被Prometheus实例使用的告警规则文件
ServiceMonitor和PodMonitor都是K8S集群的资源对象了,这样我们要在集群中监控什么数据,就变成了直接去操作 Kubernetes 集群的资源对象了,非常方便。
以下是PrometheusRule案例(Prometheus Operator):
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: mimir-record-rule
namespace: cnhb4-public-prod04-hubble
spec:
groups:
- name: mimir_api_1
rules:
- expr: histogram_quantile(0.99, sum(rate(cortex_request_duration_seconds_bucket[1m]))
by (le, cluster, job))
record: cluster_job:cortex_request_duration_seconds:99quantile
- expr: histogram_quantile(0.50, sum(rate(cortex_request_duration_seconds_bucket[1m]))
by (le, cluster, job))
record: cluster_job:cortex_request_duration_seconds:50quantile
- name: mimir_api_2
rules:
- expr: histogram_quantile(0.99, sum(rate(cortex_request_duration_seconds_bucket[1m]))
by (le, cluster, job, route))
record: cluster_job_route:cortex_request_duration_seconds:99quantile以下是ServiceMonitor案例(Prometheus Operator):
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
cloud.xxx.domain/project-enName: hubble
cloud.xxx.domain/project-id: "109772"
name: mimir-alertmanager-sm
namespace: iks-ns-hubble-mimir
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
path: /metrics
port: http-metrics
relabelings:
- targetLabel: cluster
replacement: cnhb4-public-prod04
- targetLabel: job
replacement: iks-ns-hubble-mimir/alertmanager
namespaceSelector:
matchNames:
- iks-ns-hubble-mimir
selector:
matchLabels:
storage: hubble-mimir
app: alertmanager四、Prometheus Operator架构图
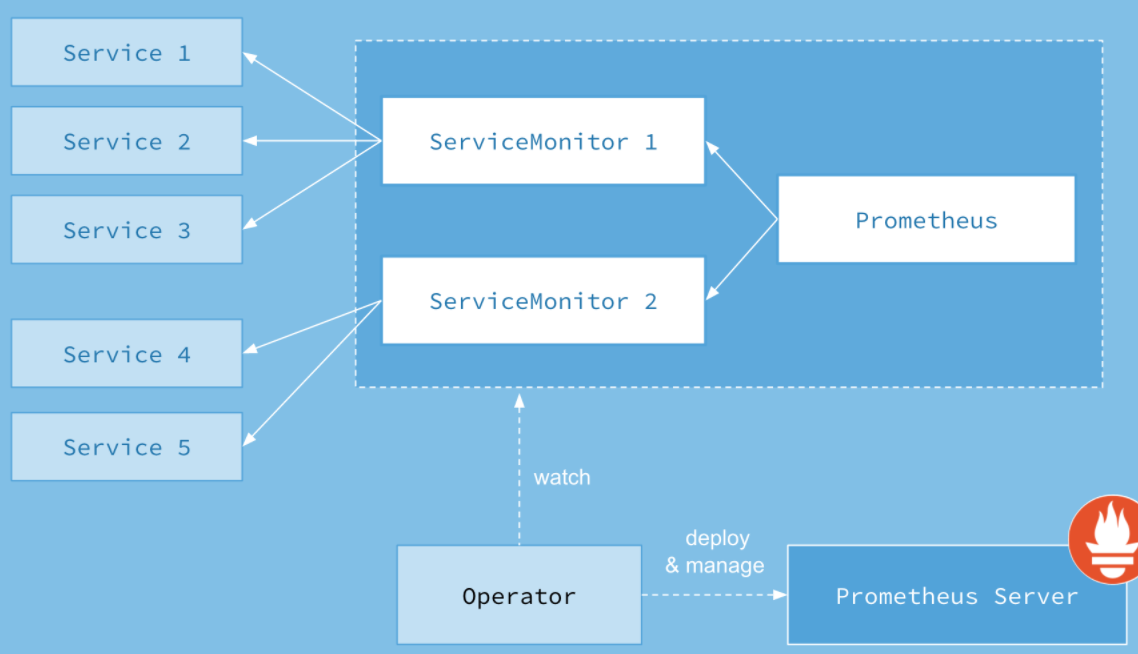
上面架构图中,各组件以不同的方式运行在Kubernetes集群中:
- Operator:根据自定义资源(Custom Resource Definition,CRD)来部署和管理Prometheus Server,同时监控这些自定义资源事件的变化来做相应的处理,是整个系统的控制中心。
- Prometheus:Prometheus资源是声明性地描述Prometheus部署的期望状态。
- Prometheus Server:Operator根据自定义资源Prometheus类型中定义的内容而部署的Prometheus Server集群,这些自定义资源可以看作用来管理Prometheus Server 集群的StatefulSets资源。
- ServiceMonitor:声明指定监控的服务,描述了一组被Prometheus监控的目标列表。该资源通过标签来选取对应的Service Endpoint,让Prometheus Server通过选取的Service来获取Metrics信息。
- Service:简单的说就是Prometheus监控的对象。提供给ServiceMonitor选取,让Prometheus Server来获取信息。
- Alertmanager:Alertmanager也是一个自定义资源类型,由Operator根据资源描述内容来部署Alertmanager集群。
参考:https://github.com/prometheus-operator/kube-prometheus
hub基于Kube-Prometheus实现,对prometheus-operator做了二次开发,支持跨集群部署监控服务。
目前已支持:
- api接口 创建/更新/删除 IKS集群监控及Grafana
- api接口 创建/更新/删除 Prometheus告警规则
- 默认对集群核心组件进行监控:apiserver,pod,container, node等
- 通过在业务集群内定义ServiceMonitor/PodMonitor等,自动添加监控目标
五、prometheus operater进程要管理prometheus的话,是不是需要告知prometheus operater需要管理的prometheus 的地址?是需要在prometheus operater上进行什么配置吗
当使用 Prometheus Operator 管理 Prometheus 实例时,实际上并不需要手动告知 Operator Prometheus 的地址。Prometheus Operator 设计的目的之一就是简化这一流程。
Prometheus Operator 使用 Kubernetes 自定义资源定义(CRD)来控制 Prometheus 实例的生命周期。这些 CRD 包括 Prometheus、ServiceMonitor 以及 PrometheusRule 等。当你在 Kubernetes 集群中创建这些资源时,Operator 会自动创建和管理相应的 Prometheus 实例以及相应的配置。
以下是通过 Prometheus Operator 管理 Prometheus 实例的基本步骤:
-
部署 Prometheus Operator: 首先,在 Kubernetes 集群中部署 Prometheus Operator。这通常通过 Helm chart 或者 Operator Lifecycle Manager(OLM)实现。
-
创建 Prometheus CRD 实例: 然后,需要创建一个或多个
Prometheus类型的 CRD 实例。这是通过创建一个简单的 YAML 文件完成的,里面描述了 Prometheus 实例的期望状态,比如版本、资源需求、持久化存储、以及监控配置等。
例如:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: example-prometheus
namespace: monitoring
spec:
replicas: 2
version: v2.11.0这个资源声明将通知 Prometheus Operator 创建一个新的 Prometheus 实例。
3、ServiceMonitor 和 PrometheusRule: 接着,为了监控特定的服务,你需要定义 ServiceMonitor 和 PrometheusRule。ServiceMonitor 定义了 Prometheus 如何发现和抓取目标服务的指标,而 PrometheusRule 定义了告警规则。
例如,你可能定义一个 ServiceMonitor:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: example-service
namespace: monitoring
spec:
selector:
matchLabels:
app: example-app
endpoints:
- port: web4、关联 Prometheus 和 ServiceMonitor: 在 Prometheus CRD 中,你可以指定使用特定的 ServiceMonitor。这通常通过在 Prometheus 定义中添加 serviceMonitorSelector 来完成,它会选择所有带有特定标签的 ServiceMonitor。
最终,Prometheus Operator 将基于这些 CRD 资源自动生成 Prometheus 配置,并部署一个具有相应配置的 Prometheus StatefulSet。你不需要手动干预来告诉 Operator Prometheus 的具体地址,一切都是通过声明式API管理实现的自动化。这是 Kubernetes Operator 模式的一个优点,它极大地简化了传统的应用部署和管理过程。
五、CRD简介
全称CustomResourceDefinition,在Kubernetes中一切都可视为资源,在Kubernetes1.7之后增加对CRD自定义资源二次开发能力扩展Kubernetes API,当我们创建一个新的CRD时,Kubernetes API服务将为你制定的每个版本创建一个新的RESTful资源路径,我们可以根据该API路径来创建一些我们自己定义的类型资源。CRD可以是命名空间,也可以是集群范围。由CRD的作用于scpoe字段中所制定的,与现有的内置对象一样,删除命名空间将删除该命名空间下的所有自定义对象。
六、prometheus部署
参考下面这篇文章,对比了传统部署方式和基于prometheus-operator的部署方式
用Prometheus监控K8S,目前最实用的部署方式都说全了_hzbooks的博客-CSDN博客
七、业务部署
当前qke的部署是每个业务不是一个promethus实例服务,一个promethus operater,如下:

另外,每个qke集群,对应一个promethus集群。
所以,如果qke新增一个K8S集群的话,我们也要新增一个promethus集群与之对应。

八、关于QPaaS对接的一些问题
1、创建或修改告警策略是调用我们接口?
- 是的。直接调用的我们封装的接口。我们的接口去调用k8s的API操作PrometheusRule.
- QPaaS每次调用是提供的完整的规则文件内容作为入参。
2、Pod的dashboard是我们创建的吗?
- 是的。直接调用的Grafana的API创建的dashboard。
- 但是模板是QPaaS管理员先配置好的,我们就刷变量
3、Promlite中Operator是怎么工作的?
现在Operator已经被集成到Promlite中,因此他们是一个进程了,Operator不再管理Promlite实例,主要的作用就是服务发现,实例发现,即从命名空间下找新增了哪些pod
九、prometheus-operator和prometheus的服务发现有什么区别于联系
Prometheus 是一个开源的监控和警报工具,它使用一种配置文件来设定如何发现目标(服务发现),然后收集(抓取)这些目标暴露的指标。而 Prometheus Operator 是 Kubernetes 的一个操作器(Operator),它简化了在 Kubernetes 环境中部署和管理 Prometheus 监控实例的过程。
Prometheus服务发现:
Prometheus 支持多种服务发现机制,例如静态配置、文件服务发现、服务注册与发现系统(如 Consul)、云提供商服务(如 EC2、Azure、GCP)以及 Kubernetes 服务发现等。借助这些机制,Prometheus 能够动态地找到需要监控的目标,并定期从这些目标收集指标。
Prometheus Operator:
Prometheus Operator 可以在 Kubernetes 集群中作为控制器运行,它引入了几个自定义资源定义(CRD),如 Prometheus、ServiceMonitor 和 PrometheusRule。它的核心优点之一就是能够自动化并简化原本更为复杂的服务发现和配置流程。
- 使用 Prometheus Operator 时,当你部署新的应用到 Kubernetes 集群中,并且希望 Prometheus 监控该应用,你只需要创建一个
ServiceMonitor资源。ServiceMonitor定义了 Prometheus 应该如何发现和抓取应用的指标。 - Prometheus Operator 会监视
ServiceMonitor资源,然后自动更新 Prometheus 的配置,从而使其不断发现新服务并收集指标。 - 同样的,对于告警规则,你可以创建一个
PrometheusRule资源,Prometheus Operator 也会将这些规则自动应用到 Prometheus 实例中。
区别与联系:
- 根本区别在于 Prometheus 本身是一个独立的工具,它直接使用配置文件来设定服务发现,并需要手动进行管理和更新。而 Prometheus Operator 是为了简化在 K8s 环境中运行 Prometheus 的管理工作。
- Prometheus Operator 基于 Prometheus 的服务发现和监控能力,提供更易于管理的方式,并拓展 Kubernetes 原生支持的功能,通过 Kubernetes API 自动化配置管理。
- Prometheus Operator 的自动化服务发现不是替代 Prometheus 本身的服务发现,而是在 Kubernetes 上的一个更高层次的抽象,便于集群管理员使用和维护。
在使用 Prometheus 对 Kubernetes 集群进行监控时,Prometheus Operator 能够提供更为方便和符合 Kubernetes 生态的管理方式。这两者紧密结合,让在 Kubernetes 上部署和维护 Prometheus 变得更加便捷和自动化。
问了zhangyu:
ServiceMonitor负责发现Service,然后将Service告知Prometheus的k8s自动发现(需要根据Service去发现)
另外,prometheus operator默认会监听所有命名空间下是否有ServiceMonitor对象(也可以指定哪些命名空间下),然后将发现的Service转到prometheus的配置文件中
本质上:
- prometheus operator是通过监听k8s APIServer,知道了有哪些Service需要发现,然后告知prometheus,这些service需要进行服务发现
- 所以,真正的服务发现还是prometheus
十、prometheus operator监听k8s APIServer需要什么权限?
Prometheus Operator 监听 Kubernetes API Server 是为了发现和管理 Kubernetes 资源,如服务(Service)、端点(Endpoints)、Pods 等,以及其自定义资源定义(CRD),如 ServiceMonitor 或 PodMonitor。为了执行这些操作,Prometheus Operator 需要有相应的权限,这些权限通常通过 Kubernetes 的角色访问控制(RBAC)机制提供。
具体来说,Prometheus Operator 需要以下权限:
-
ClusterRole 和 ClusterRoleBinding: 要赋予 Prometheus Operator 对集群级资源 (如 Nodes, Services) 的读取权限以及对自定义资源的完整权限,需要创建一个 ClusterRole 和相对应的 ClusterRoleBinding。ClusterRole 定义了一组权限,而 ClusterRoleBinding 将这些权限赋予到某个特定的服务账号(ServiceAccount)上。
-
ServiceAccount: Prometheus Operator 通常运行在它自己的命名空间下,并且会有一个关联的 ServiceAccount。该 ServiceAccount 被用来给 Prometheus Operator 的 Pod 授予必要的权限。
-
CRD 权限: 对于 Prometheus Operator 的自定义资源,如
ServiceMonitor、PodMonitor和PrometheusRule,需要特定的权限使其能够创建、获取、更新、删除这些资源。
以下是一个典型的 Prometheus Operator RBAC 配置示例:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-operator
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
verbs:
- get
- list
- watch
- apiGroups:
- monitoring.coreos.com
resources:
- alertmanagers
- prometheuses
- prometheuses/finalizers
- servicemonitors
- podmonitors
- prometheusrules
verbs:
- get
- list
- watch
- create
- update
- delete
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus-operator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus-operator
subjects:
- kind: ServiceAccount
name: prometheus-operator
namespace: monitoring在这个配置中,ClusterRole 定义了一系列的动作,比如对于 nodes、services、endpoints 和 pods 可执行的动作包括 get、list 和 watch;对于 Prometheus Operator 的自定义资源则包括 get、list、watch、create、update 和 delete。
然后,ClusterRoleBinding 将这些权限赋予了在 monitoring 命名空间中名为 prometheus-operator 的 ServiceAccount。这个 ServiceAccount 应该与运行 Prometheus Operator 的 Pod 绑定。这样一来,Prometheus Operator 就有了足够的权限来监听 Kubernetes API Server 以及对自定义资源进行操作。
要注意的是,实际的权限需求可能会因安装的 Prometheus Operator 版本、部署的方式、以及集群具体配置的不同而略有差异。因此,建议查阅最新的官方文档或自动化部署脚本来获取准确的 RBAC 配置。
十一、监控配置
1、介绍
我们基于开源的项目(kube-prometheus)配置了(QPaaS)k8s整个集群的监控,也是prometheus-operator提供的开源服务。GitHub - prometheus-operator/kube-prometheus: Use Prometheus to monitor Kubernetes and applications running on Kubernetes
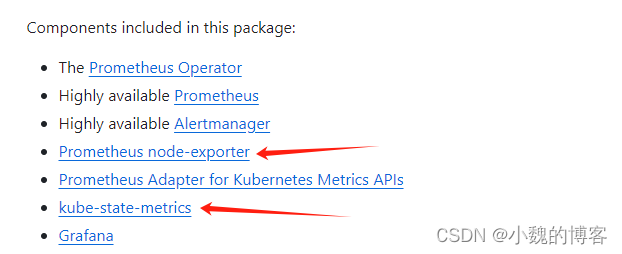
如图所示,kube-prometheus提供了node-exporter的配置和kube-state-metrics配置,再加上K8S本身提供了标准的 /metrics 端点来暴露内部组件的指标数据,基本就将K8S集群的监控都涵盖了。
监控分类:
- node-exporter:一个容器,需要部署到每个Node上,并且需要配置权限,可以采集node的数据,这和deepflow相似,deepflow也需要部署到每个node上,并且有需要较高的权限。
- kube-state-metrics:一个容器,一个集群只创建一个容器即可,需要对一些资源要有list和watch权限,通过调用k8s API工作
- k8s控制平面组件各组件
/metrics端点:k8s自带,无需另外安装服务
2、kube-state-metrics
kube-state-metrics 是一个监听 Kubernetes API 服务器的服务,它生成有关对象(如 Deployments、Pods、Nodes 等)状态的指标。下面是 kube-state-metrics 采集数据的基本机制:
-
连接 Kubernetes API:
kube-state-metrics会与 Kubernetes API 服务器建立连接。这通常需要给kube-state-metrics服务分配足够权限的 ServiceAccount,这样它就可以访问 API 服务器。 -
资源监听:
kube-state-metrics会对一系列预定义的资源对象注册 watch 功能,这允许它接收到这些资源对象状态变化的通知。这些资源可以包括 Nodes、Pods、Deployments、ReplicaSets、Services、PersistentVolumes 等。 -
**收集数据:**当 Kubernetes 资源发生变化时(创建、更新、删除等),API 服务器会发送事件给
kube-state-metrics。然后,kube-state-metrics会使用这些信息来更新其内部的数据商店。 -
生成指标:
kube-state-metrics对监听到的资源对象信息进行处理,并将其转换为可由 Prometheus 抓取的指标数据格式。这些指标反映了 Kubernetes 资源的当前状态。 -
提供指标:
kube-state-metrics将这些指标暴露在它的 HTTP/metrics端点上。一旦 Prometheus(或其他支持抓取 Prometheus 格式指标的监控系统)配置为抓取这些数据,它就会定期访问这个端点抓取最新指标。
kube-state-metrics 自身不存储指标数据,它仅在请求时即时生成指标。它的设计聚焦于简单性和易于操作,这意味着它不缓存任何数据,只是直接向 API 服务器请求最新的状态数据来生成指标。这个设计保证了监控数据的时效性,因为所有暴露的指标都与最新的集群状态一致。

3、node-exporter的工作原理
node-exporter 是 Prometheus 生态系统中的一个组件,用于收集宿主机的硬件和操作系统层面的指标数据,比如 CPU、内存、磁盘和网络统计信息等。
以下是 node-exporter 的基本工作原理:
-
部署:
node-exporter通常作为 DaemonSet 在 Kubernetes 环境中的每一个节点上部署,或者在非 Kubernetes 环境中直接作为服务运行在每台机器上。 -
收集指标:
node-exporter运行在主机上,利用不同的收集器(collectors)从操作系统和硬件获取指标数据。它使用操作系统提供的接口(如/proc文件系统在 Linux 上)来收集机器信息。 -
暴露指标:
node-exporter将收集到的数据暴露在一个 HTTP 端口的/metrics路径上。这些指标是以 Prometheus 标准格式展现的,因此可以被 Prometheus 服务器轻松抓取。 -
定时抓取:在 Prometheus 中,你可以配置 scrape job 来定期抓取
node-exporter暴露的指标。这个抓取作业通常设置为每 15 秒到 1 分钟执行一次。 -
存储指标:Prometheus 服务器在抓取这些指标后,会存储它们以便进行查询、可视化和警告。这些数据可以用 Grafana 等工具进一步展示,并创建监控仪表板。
node-exporter 的设计非常模块化,包含了多个独立的收集器,每一个收集器负责收集特定类型的系统信息。这允许在启动 node-exporter 时通过命令行参数来启用或禁用特定的收集器,从而优化性能和收集范围。
在 Kubernetes 环境中,你也可以使用 Service Discovery 功能来自动发现并监控所有节点上的 node-exporter 实例。
综上所述,node-exporter 提供了一种机制,通过它收集的指标,Prometheus 可以监控各个主机的资源使用情况和性能状况,以保持系统的稳定性和高效性。
4、K8S本身提供了标准的 /metrics 端点
在 Kubernetes 中,许多核心组件都提供了 /metrics 端点以暴露关于其运行状态和性能的指标,用于监控和故障排查。比如 API server、scheduler、controller-manager 和 etcd 等控制平面组件的指标。这些 /metrics 端点默认情况下都是激活的,你可以配置监控系统,如 Prometheus,来抓取这些端点的数据。
例如,Kubernetes API server 提供的 /metrics 端点暴露了关于 Kubernetes API 请求的各种指标,你可以使用 Prometheus 来抓取和存储这些指标。
以下是 Kubernetes 中几个关键组件的 /metrics 端点以及它们所暴露的指标类型简述:
-
Kubelet:
- 端点:
http://<node-ip>:10250/metrics - 描述:Kubelet 的
/metrics端点暴露了与 Kubernetes 节点(Node)相关的指标,也包括 Pod 和容器相关的指标。它提供了资源使用情况、节点健康检查以及 kubelet 操作的详细指标,如 API 调用、容器操作和节点状态。
- 端点:
-
API Server:
- 端点:
https://<api-server-host>:443/metrics - 描述:API Server 是 Kubernetes 控制平面的核心组件,它的
/metrics端点提供了与 Kubernetes API 相关的性能指标,例如请求延迟、请求大小、API 请求次数、正在处理的请求数等。
- 端点:
-
Scheduler:
- 端点:
http://<scheduler-host>:10251/metrics - 描述:Scheduler
/metrics端点提供了与 Kubernetes 调度器相关的指标,比如调度尝试的数量、调度失败和成功的次数、调度延迟以及队列的深度等信息。
- 端点:
-
Controller Manager:
- 端点:
http://<controller-manager-host>:10252/metrics - 描述:Controller Manager 的
/metrics端点暴露了关于 Kubernetes 控制循环的指标,如各种控制器处理资源的次数、队列长度、工作项处理时间等。
- 端点:
-
Etcd:
- 端点:
http://<etcd-host>:2379/metrics - 描述:作为 Kubernetes 的后端存储,Etcd 提供了
/metrics端点来输出关于请求、响应时间、领导选举和一致性等方面的指标。
- 端点:
-
Proxy (kube-proxy):
- 端点:
http://<node-ip>:10249/metrics - 描述:Kube-proxy 的
/metrics端点提供了关于 Kubernetes 网络代理组件的指标,包括代理规则、同步延时和网络连接等统计信息。
- 端点:
要注意,访问这些端点可能需要适当的授权和认证,因为它们可能会暴露敏感信息。在生产环境中,对监控端点的访问应该受到安全控制。
这些 /metrics 端点可以被 Prometheus 监控系统配置为定期抓取,从而使你能够监控 Kubernetes 控制平面和工作节点的健康状况和性能。
5、权限
我们注意到,node-exporter 和 kube-state-metrics都涉及到创建ClusterRole这个资源对象,而ClusterRole普通用户一般是没有权限创建的,因此需要K8S管理员给我们设置权限。
k8s管理员先帮我们配置好用户账号权限,以及ServiceAccount权限,比如拥有创建ClusterRole的权限等,然后会提供给我们kubeconfig文件,我们每次使用此kubeconfig进行操作即可。
apiVersion: v1
kind: Namespace
metadata:
name: monitoring
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: k8s-monitor
namespace: monitoring
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: k8s-monitor
rules:
- apiGroups:
- apiextensions.k8s.io
resources:
- customresourcedefinitions
verbs:
- '*'
- apiGroups:
- apiextensions.k8s.io
resourceNames:
- alertmanagers.monitoring.coreos.com
- podmonitors.monitoring.coreos.com
- prometheuses.monitoring.coreos.com
- prometheusrules.monitoring.coreos.com
- servicemonitors.monitoring.coreos.com
resources:
- customresourcedefinitions
verbs:
- get
- update
- apiGroups:
- monitoring.coreos.com
resources:
- alertmanagers
- prometheuses
- prometheuses/finalizers
- alertmanagers/finalizers
- servicemonitors
- podmonitors
- prometheusrules
verbs:
- '*'
- apiGroups:
- ""
resources:
- configmaps
verbs:
- '*'
- apiGroups:
- ""
resources:
- services
- services/finalizers
- serviceaccounts
- endpoints
verbs:
- '*'
- apiGroups:
- ""
resources:
- nodes
- pods
- nodes/proxy
- namespaces
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
- apiGroups:
- "rbac.authorization.k8s.io"
resources:
- clusterroles
- clusterrolebindings
- roles
- rolebindings
verbs:
- '*'
- apiGroups:
- "apps"
resources:
- daemonsets
- deployments
verbs:
- '*'
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: monitoring
name: prometheus-operator-role
rules:
- apiGroups:
- ""
resources:
- secrets
verbs:
- '*'
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: k8s-monitor
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: k8s-monitor
subjects:
- kind: ServiceAccount
name: k8s-monitor
namespace: monitoring
- kind: User
name: promethus-operator
apiGroup: rbac.authorization.k8s.io
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: k8s-monitor-promethus-operator-rolebinding
namespace: monitoring
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: prometheus-operator-role
subjects:
- kind: ServiceAccount
name: k8s-monitor
namespace: monitoring
- kind: User
name: promethus-operator
apiGroup: rbac.authorization.k8s.io
参考:

















 1384
1384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









