







今天项目里面用到dom4j解析xml数据,特地整理了一下封装dom4j的工具方法,使用dom4j来解析xml文档.
首先是封装了dom4j的工具类:
package myDOM4J;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.StringReader;
import java.io.StringWriter;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
/**
* 基于dom4j的工具包
*
* @author PengChan
*
*/
public class DOMUtils {
/**
* 通过文件的路径获取xml的document对象
*
* @param path 文件的路径
* @return 返回文档对象
*/
public static Document getXMLByFilePath(String path) {
if (null == path) {
return null;
}
Document document = null;
try {
SAXReader reader = new SAXReader();
document = reader.read(new File(path));
} catch (Exception e) {
e.printStackTrace();
}
return document;
}
/**
* 通过xml字符获取document文档
* @param xmlstr 要序列化的xml字符
* @return 返回文档对象
* @throws DocumentException
*/
public static Document getXMLByString(String xmlstr) throws DocumentException{
if(xmlstr==""||xmlstr==null){
return null;
}
Document document = DocumentHelper.parseText(xmlstr);
return document;
}
/**
* 获取某个元素的所有的子节点
* @param node 制定节点
* @return 返回所有的子节点
*/
public static List<Element> getChildElements(Element node) {
if (null == node) {
return null;
}
@SuppressWarnings("unchecked")
List<Element> lists = node.elements();
return lists;
}
/**
* 获取指定节点的子节点
* @param node 父节点
* @param childnode 指定名称的子节点
* @return 返回指定的子节点
*/
public static Element getChildElement(Element node,String childnode){
if(null==node||null == childnode||"".equals(childnode)){
return null;
}
return node.element(childnode);
}
/**
* 获取所有的属性值
* @param node
* @param arg
* @return
*/
public static Map<String, String> getAttributes(Element node,String...arg){
if(node==null||arg.length==0){
return null;
}
Map<String, String> attrMap = new HashMap<String,String>();
for(String attr:arg){
String attrValue = node.attributeValue(attr);
attrMap.put(attr, attrValue);
}
return attrMap;
}
/**
* 获取element的单个属性
* @param node 需要获取属性的节点对象
* @param attr 需要获取的属性值
* @return 返回属性的值
*/
public static String getAttribute(Element node,String attr){
if(null == node||attr==null||"".equals(attr)){
return "";
}
return node.attributeValue(attr);
}
/**
* 添加孩子节点元素
*
* @param parent
* 父节点
* @param childName
* 孩子节点名称
* @param childValue
* 孩子节点值
* @return 新增节点
*/
public static Element addChild(Element parent, String childName, String childValue) {
Element child = parent.addElement(childName);// 添加节点元素
child.setText(childValue == null ? "" : childValue); // 为元素设值
return child;
}
/**
* DOM4j的Document对象转为XML报文串
*
* @param document
* @param charset
* @return 经过解析后的xml字符串
*/
public static String documentToString(Document document, String charset) {
StringWriter stringWriter = new StringWriter();
OutputFormat format = OutputFormat.createPrettyPrint();// 获得格式化输出流
format.setEncoding(charset);// 设置字符集,默认为UTF-8
XMLWriter xmlWriter = new XMLWriter(stringWriter, format);// 写文件流
try {
xmlWriter.write(document);
xmlWriter.flush();
xmlWriter.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
return stringWriter.toString();
}
/**
* 去掉声明头的(即<?xml...?>去掉)
*
* @param document
* @param charset
* @return
*/
public static String documentToStringNoDeclaredHeader(Document document, String charset) {
String xml = documentToString(document, charset);
return xml.replaceFirst("\\s*<[^<>]+>\\s*", "");
}
/**
* 解析XML为Document对象
*
* @param xml
* 被解析的XMl
* @return Document
* @throws ParseMessageException
*/
public final static Element parseXml(String xml) {
StringReader sr = new StringReader(xml);
SAXReader saxReader = new SAXReader();
Document document = null;
try {
document = saxReader.read(sr);
} catch (DocumentException e) {
e.printStackTrace();
}
Element rootElement = document != null ? document.getRootElement() : null;
return rootElement;
}
/**
* 获取element对象的text的值
*
* @param e
* 节点的对象
* @param tag
* 节点的tag
* @return
*/
public final static String getText(Element e, String tag) {
Element _e = e.element(tag);
if (_e != null)
return _e.getText();
else
return null;
}
/**
* 获取去除空格的字符串
*
* @param e
* @param tag
* @return
*/
public final static String getTextTrim(Element e, String tag) {
Element _e = e.element(tag);
if (_e != null)
return _e.getTextTrim();
else
return null;
}
/**
* 获取节点值.节点必须不能为空,否则抛错
*
* @param parent 父节点
* @param tag 想要获取的子节点
* @return 返回子节点
* @throws ParseMessageException
*/
public final static String getTextTrimNotNull(Element parent, String tag) {
Element e = parent.element(tag);
if (e == null)
throw new NullPointerException("节点为空");
else
return e.getTextTrim();
}
/**
* 节点必须不能为空,否则抛错
*
* @param parent 父节点
* @param tag 想要获取的子节点
* @return 子节点
* @throws ParseMessageException
*/
public final static Element elementNotNull(Element parent, String tag) {
Element e = parent.element(tag);
if (e == null)
throw new NullPointerException("节点为空");
else
return e;
}
/**
* 将文档对象写入对应的文件中
* @param document 文档对象
* @param path 写入文档的路径
* @throws IOException
*/
public final static void writeXMLToFile(Document document,String path) throws IOException{
if(document==null||path==null){
return;
}
XMLWriter writer = new XMLWriter(new FileWriter(path));
writer.write(document);
writer.close();
}
}
然后使用了dom4j来解析xml格式的数据,首先自己给自己写了一个xml文档(文档内容略微随意,不过不用在意这些细节,哈哈)
<?xml version="1.0" encoding="UTF-8"?>
<myfriend>
<xiaoxue>
<loc>小学</loc>
<list>
<stud>
<name>张三</name>
<gender>男</gender>
</stud>
<stud>
<name>小花</name>
<gender>女</gender>
</stud>
</list>
</xiaoxue>
<chuzhong>
<oc>初中</oc>
<list>
<stud>
<name>小明</name>
<gender>男</gender>
</stud>
<stud>
<name>小龙</name>
<gender>女</gender>
</stud>
</list>
<anlian>
<xihuan>
<list>
<stud>
<name>小娜</name>
<key>女</key>
</stud>
<stud>
<name>小齐</name>
<key>男</key>
</stud>
</list>
</xihuan>
<feichangxihuan>
<stud>
<name>哈哈</name>
<des>苍老师</des>
</stud>
</feichangxihuan>
</anlian>
</chuzhong>
</myfriend>编写测试类来解析这个xml格式的文档:
package myDOM4J.test;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.Element;
import org.junit.Test;
import myDOM4J.DOMUtils;
public class MyTest {
@SuppressWarnings("unchecked")
@Test
public void test(){
Document document = DOMUtils.getXMLByFilePath("I:/javaweb/MYWORKING_SPACE/myDOM4J/src/myDOM4J/test/friends.xml");
// 查询我所有的小学的结点
Element root = document.getRootElement();
List<Element> elements = root.element("xiaoxue").elements();
System.out.println(elements.get(0).getText());
List<Element> studs = elements.get(1).elements();
for(Element stu:studs){
System.out.print("-->"+stu.element("name").getText()+" ");
System.out.println(stu.element("gender").getText());
}
for(Iterator iterator = root.element("chuzhong").elementIterator();iterator.hasNext();){
Element element = (Element) iterator.next();
if(element.getName().equals("oc")){
System.out.println(element.getText());
}else if(element.getName().equals("list")){
for(Iterator iterator2 = element.elements("stud").iterator();iterator2.hasNext();){
Element stuElement = (Element) iterator2.next();
System.out.print("-->"+stuElement.element("name").getText());
System.out.println(stuElement.element("gender").getText());
}
}else if(element.getName().equals("anlian")){
for(Iterator iterator2 = element.elementIterator();iterator2.hasNext();){
Element current = (Element) iterator2.next();
if(current.getName().equals("xihuan")){
for(Iterator iterator3 = current.element("list").elementIterator();iterator3.hasNext();){
Element sElement = (Element) iterator3.next();
System.out.print("-->"+sElement.element("name").getText());
System.out.println(sElement.element("key").getText());
}
}else if(current.getName().equals("feichangxihuan")){
Element element2 = current.element("stud");
System.out.print("-->"+element2.element("name").getText());
System.out.println(element2.element("des").getText());
}
}
}
}
}
}
运行的结果如下如:
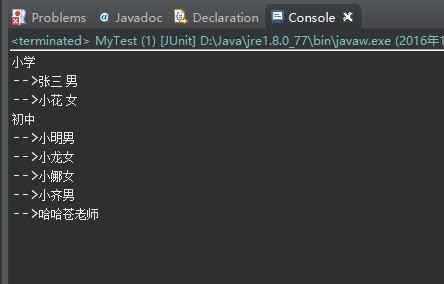
解析xml还是挺简单的,不过有点繁琐,是个体力活!一直好奇什么时候出来一个框架,使得解析xml文档像,前端里面jquery框架操作dom一样方便就好了!















 210
210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









