







1. 项目背景
经常用电脑的朋友应该会发现,电脑锁屏页面是微软必应每天更新的精美壁纸,偶尔还能看到一些十分惊艳的壁纸,于是我去寻找如何下载他们,我在 GitHub 上闲逛时,还真发现一个自动归档这些壁纸的仓库。
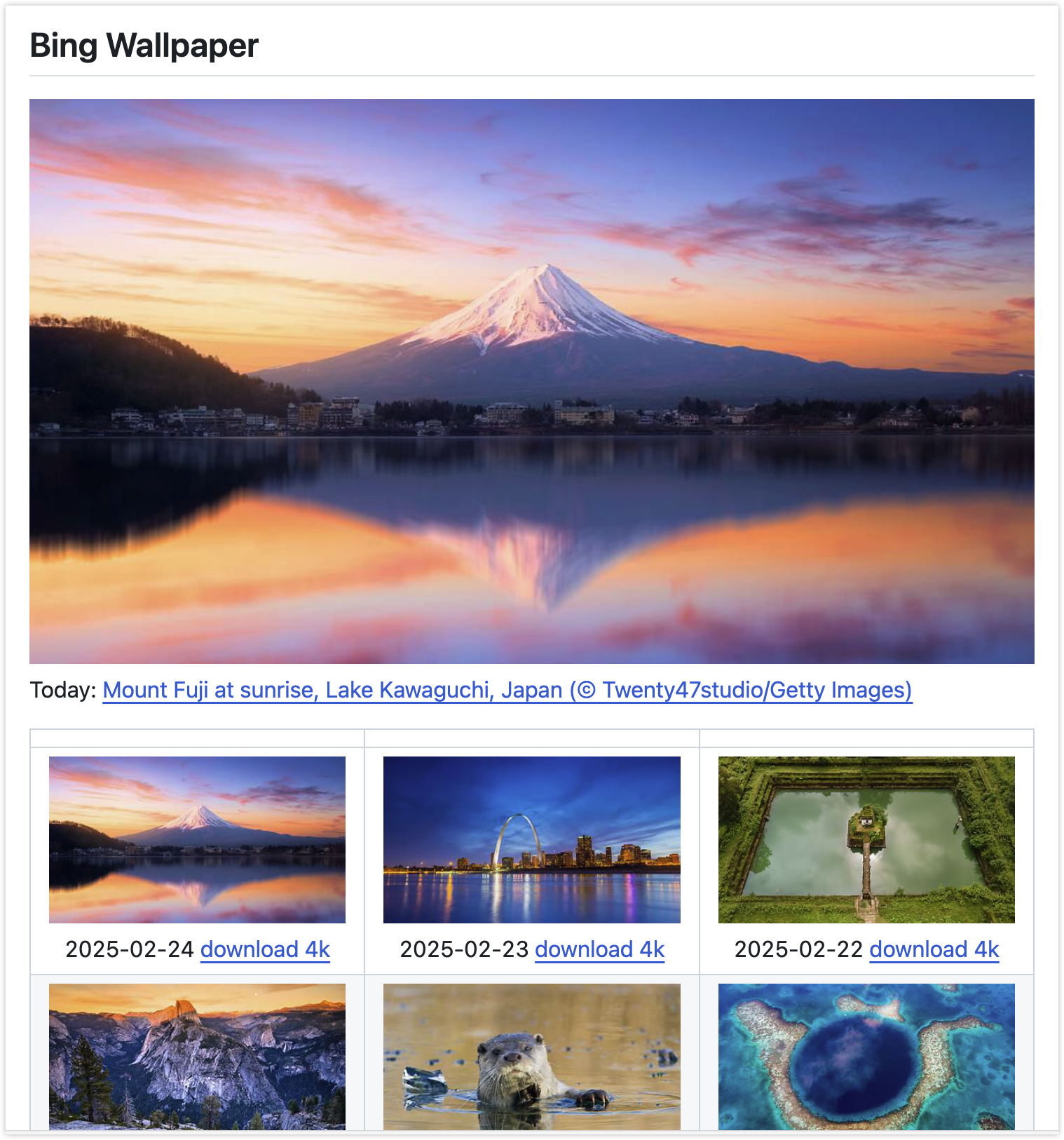
该项目由GitHub用户niumoo维护,项目地址:niumoo/bing-wallpaper。
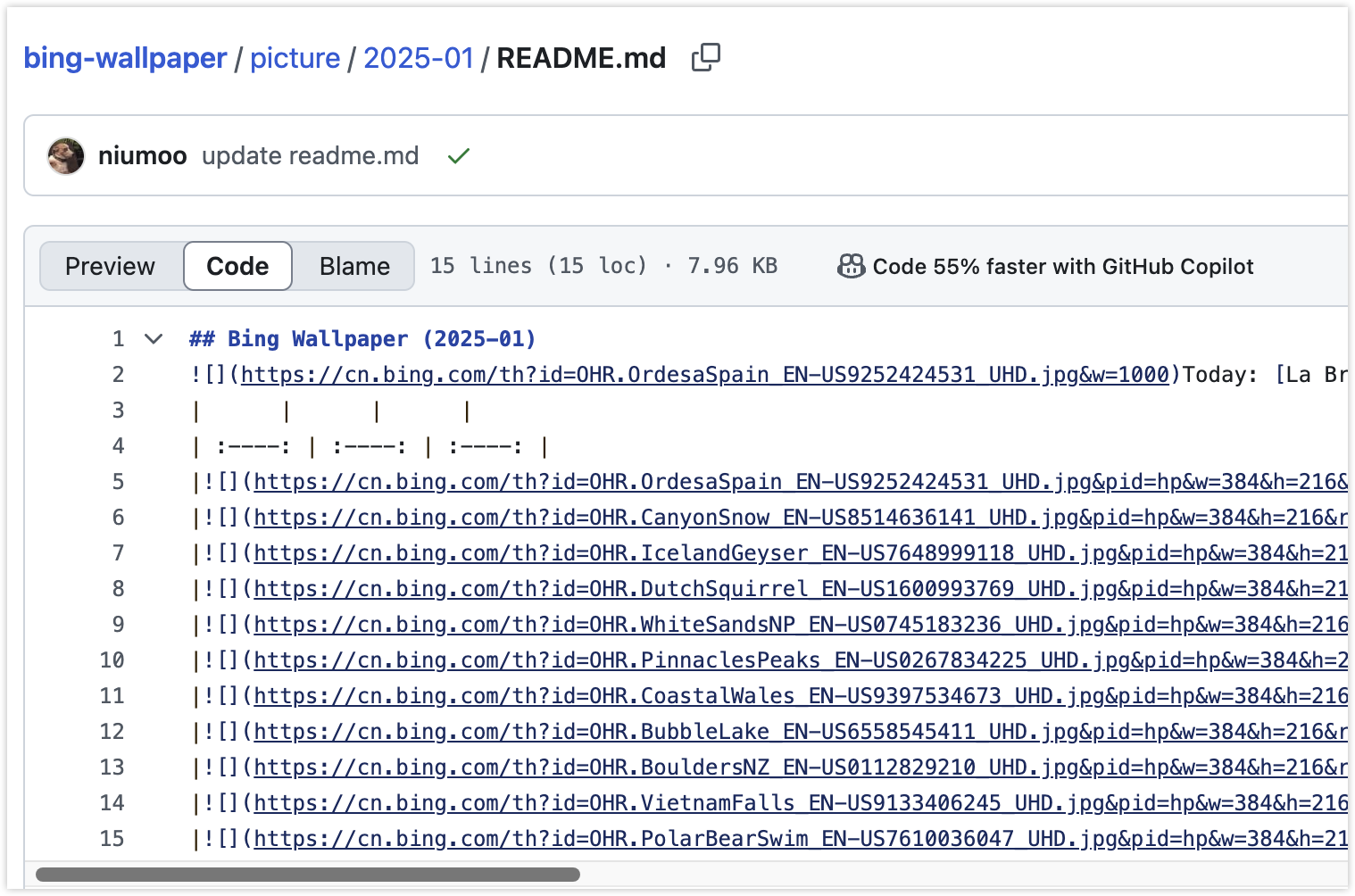
该项目每天自动归档必应首页美图!但当我点开 README.md 时,发现仓库仅保存图片Markdown索引文件,并没有原图,我们要下载必须手动,不过都有下载链接了,我们用爬虫显然会更高效。
既然要写爬虫,我们对代码设定一些目标,要实现以下功能:
- 1️⃣ 批量下载4K壁纸
- 2️⃣ 自动化解析索引文件
- 3️⃣ 实现高效并发下载
- 4️⃣ 避免重复下载
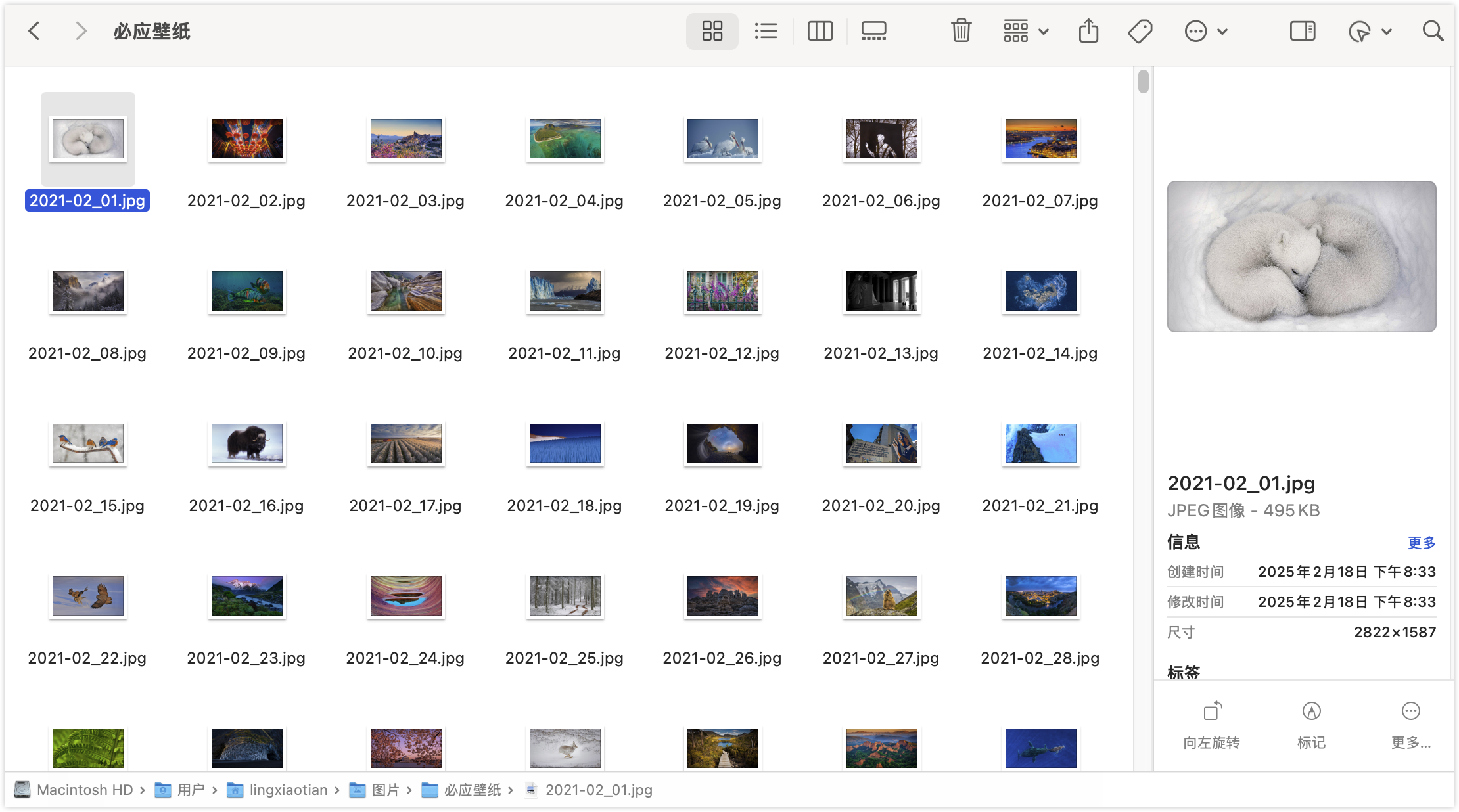
代码预期的最终效果:
2. 方案设计
2.1 分析数据源
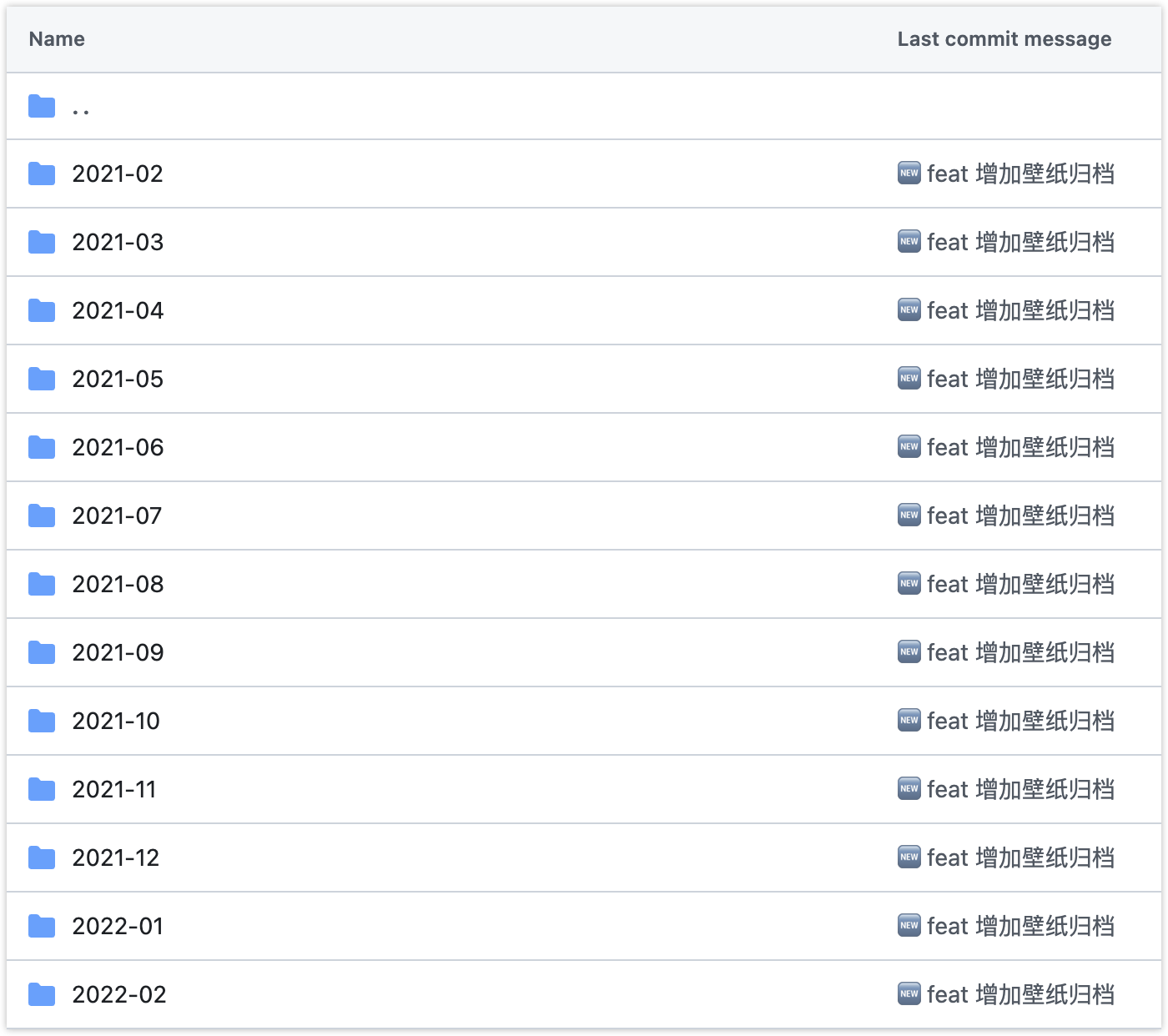
通过观察目标仓库的目录结构,我们发现md文件:
- 按年月分目录存储(如
2024-09) - 每个目录包含
README.md文件 - Markdown文件中包含
[download 4k]格式的图片直链
2.2 流程设计
2.3 需求分析
▶️ 批量下载4K壁纸:
我们有对应的壁纸URL,只需要调用requests库即可下载,这个很好解决。
▶️ 自动化解析索引文件
壁纸文件都保存在项目中的picture中的md文件里,目录格式如下:
bing-wallpaper/
├── picture/ # 存储每日壁纸的文件夹
│ ├── 2021-01/ # 按年月分类
│ │ └── README.md # 每日壁纸的md文件
│ ├── 2021-02/
│ │ └── README.md
│ ├── 2021-03/
│ ├── ...
│ ├── 2025-02/
│ └── ...
└── README.md # 项目说明文件
我们可以使用os库来读取文件,并通过re正则表达式库来读取其中每条4K壁纸链接,也不算复杂。
▶️ 实现高效并发下载
并发下载可以参考Python多线程的那篇文章,使用concurrent.futures库可以方便的进行多线程并发,实现并发下载,每读取完一个文件,批量下载所有壁纸。
📎 传送门:
▶️ 避免重复下载
解决这个问题主要是通过文件名来识别,主要有两种方式:
- 一个下载链接对应的文件是唯一的,利用这个特性,我们可以根据URL链接生成一个md5编码,将URL的md5编码作为文件名保存,每次下载时先检查本地文件名和URL的md5。
- 根据本项目的特性,文件都是按照年月去划分的,我们完全可以根据md文件的文件名,如
2025-01_01或者2024-10-31这样的日期去命名,也更好区分图片的来源。
很显然,对于本项目来说选择后者是更好的方案,至此,我们已经确定了基本的方案,接下来就是用代码去实现。
3. 代码实现
3.1 文件遍历
首先我们先clone项目文件,或者直接在线下载:
git@github.com:niumoo/bing-wallpaper.git
找到项目中的picture,复制对应的文件路径
我们直接写到主函数中,先顺序读取文件,再对调用函数提取其中的图片链接:
def main(root_dir, output_dir):
"""
遍历根目录下的所有子文件夹,查找 README.md 文件并下载图片。
""" # 遍历根目录下的所有子文件夹
for root, dirs, files in os.walk(root_dir):
for file in files:
if file == "README.md":
# 获取年月信息(文件夹名即为年月)
folder_name = os.path.basename(root)
# 确保文件夹名称是有效的年月格式
if re.match(r'^\d{4}-\d{2}$', folder_name):
md_file_path = os.path.join(root, file)
print(f"正在处理 {md_file_path} ...")
# 下载该目录下的所有图片
get_url(md_file_path, output_dir, folder_name)
要点:
- 循环时注意嵌套层数,找到正确的文件
- 正则表达式
\d{4}-\d{2}验证年月格式合法性 - 路径拼接使用
os.path.join
3.2 Markdown文件解析
我们接着上一步,获取到文件后,我们需要读取其中的4K壁纸下载链接,而不是缩略图
md文件节选:
## Bing Wallpaper (2021-10)
Today: [Misty pine forest in the Central Highlands of Vietnam (© Thanh Thuy/Moment/Getty Images)](https://cn.bing.com/th?id=OHR.MistyForest_EN-US5261676101_UHD.jpg)
|
2021-10-31 [download 4k](https://cn.bing.com/th?id=OHR.MistyForest_EN-US5261676101_UHD.jpg)|
2021-10-30 [download 4k](https://cn.bing.com/th?id=OHR.UnkindnessRavens_EN-US5051823062_UHD.jpg)|
2021-10-29 [download 4k](https://cn.bing.com/th?id=OHR.Dargavs_EN-US4957085337_UHD.jpg)|
我们可以通过正则表达式提取所有的[download 4k]标签后的链接,并提交给线程池下载。
def get_url(md_file, output_dir, ym):
# 读取 md 文件内容
with open(md_file, "r", encoding="utf-8") as f:
content = f.read() # 使用正则表达式提取图片链接
pattern = r'\[download 4k\]\((.*?)\)'
urls = re.findall(pattern, content)
print(f"在 {md_file} 中找到 {len(urls)} 个图片链接。")
# 创建图片存储文件夹(如果不存在)
os.makedirs(output_dir, exist_ok=True)
# 使用线程池下载每个图片
with ThreadPoolExecutor() as executor:
for idx, url in enumerate(urls, start=1):
executor.submit(download_image, url, output_dir, ym, idx)
要点:
- 多线程中可以使用
max_workers限制并发数 - 使用正则表达式时也可以提取出链接前面的日期作为文件名
3.3 图片下载
接着我们来实现对单独图片的下载,使用requests库即可
def download_image(url, output_dir, ym, idx):
print(f"正在下载第 {idx} 张图片:{url}")
try:
response = requests.get(url, stream=True, timeout=10)
if response.status_code == 200:
# 获取文件扩展名
parsed_url = urlparse(url)
ext = os.path.splitext(parsed_url.path)[1]
if not ext:
ext = ".jpg" # 默认使用 jpg 扩展名
# 图片保存的路径和文件名
filename = f"{ym}_{idx:02d}{ext}"
filepath = os.path.join(output_dir, filename)
# 保存图片到文件
with open(filepath, "wb") as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
print(f"保存到:{filepath}")
else:
print(f"下载失败,状态码:{response.status_code}")
except Exception as e:
print(f"下载图片时出现错误:{e}")
要点:
stream=True实现流式下载(适合大文件)response.iter_content分块处理数据,分成1kb传输os.path.exists实现去重,查看有无同名文件。
3.4 完整代码
[!note]
若直接复制完整代码,使用时请修改对应的文件路径,否则无法运行
# -*- coding: utf-8 -*-
"""
@file: bing.py.py
@author: lingxiaotian
@date: 2025/2/24 11:49
"""
# Copyright (c) 2025, 凌小添
# All rights reserved.
import os
import re
import requests
from urllib.parse import urlparse
from concurrent.futures import ThreadPoolExecutor
def download_image(url, output_dir, ym, idx):
"""
下载单个图片并保存到指定文件夹中。
"""
print(f"正在下载第 {idx} 张图片:{url}")
try:
response = requests.get(url, stream=True, timeout=10)
if response.status_code == 200:
# 获取文件扩展名
parsed_url = urlparse(url)
ext = os.path.splitext(parsed_url.path)[1]
if not ext:
ext = ".jpg" # 默认使用 jpg 扩展名
# 图片保存的路径和文件名
filename = f"{ym}_{idx:02d}{ext}"
filepath = os.path.join(output_dir, filename)
# 保存图片到文件
with open(filepath, "wb") as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
print(f"保存到:{filepath}")
else:
print(f"下载失败,状态码:{response.status_code}")
except Exception as e:
print(f"下载图片时出现错误:{e}")
def get_url(md_file, output_dir, ym):
# 读取 md 文件内容
with open(md_file, "r", encoding="utf-8") as f:
content = f.read() # 使用正则表达式提取图片链接
pattern = r'\[download 4k\]\((.*?)\)'
urls = re.findall(pattern, content)
print(f"在 {md_file} 中找到 {len(urls)} 个图片链接。")
# 创建图片存储文件夹(如果不存在)
os.makedirs(output_dir, exist_ok=True)
# 使用线程池下载每个图片
with ThreadPoolExecutor() as executor:
for idx, url in enumerate(urls, start=1):
executor.submit(download_image, url, output_dir, ym, idx)
def main(root_dir, output_dir):
"""
遍历根目录下的所有子文件夹,查找 README.md 文件并下载图片。
"""
# 遍历根目录下的所有子文件夹
for root, dirs, files in os.walk(root_dir):
for file in files:
if file == "README.md":
# 获取年月信息(文件夹名即为年月)
folder_name = os.path.basename(root)
# 确保文件夹名称是有效的年月格式
if re.match(r'^\d{4}-\d{2}$', folder_name):
md_file_path = os.path.join(root, file)
print(f"正在处理 {md_file_path} ...")
# 下载该目录下的所有图片
get_url(md_file_path, output_dir, folder_name)
if __name__ == "__main__":
# 根目录路径(wallpaper 文件夹路径)
wallpaper_dir = "/Users/lingxiaotian/Downloads/bing-wallpaper-main/picture"
# 指定图片保存的输出文件夹
output_directory = "/Users/lingxiaotian/Downloads/wallpaper"
# 遍历并下载所有图片
main(wallpaper_dir, output_directory)
4. 优化方案
4.1 在线实时爬取
我们目前是直接下载Github项目文件,读取文件进行下载,我们也可以直接通过在线读取的方式来下载最新数据。
项目文件URL如下,其中要修改的只有年月那个参数:https://github.com/niumoo/bing-wallpaper/blob/main/picture/2021-02/README.md
我们要获取最新月份的壁纸时,比如2025年4月,可以像下面这样直接获取md文件解析下载。
new_date = '2025-04'
url = f"https://github.com/niumoo/bing-wallpaper/blob/main/picture/{new_date}/README.md"
4.2 高级去重机制
我们也可以直接计算文件的Md5值来实现去重,调用hashlib库来实现。
import hashlib
def get_file_md5(filepath):
"""计算文件MD5值"""
hash_md5 = hashlib.md5()
with open(filepath, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest()
# 在下载前检查
if os.path.exists(filepath) and get_file_md5(filepath) == remote_md5:
print("文件内容未变化,跳过下载")
5. 写在最后:技术让生活更美好 ✨
小Tips:
- 🚦 遵守 Robots 协议,建议设置请求间隔,减少访问频率
- 🚫 本项目仅用于技术学习交流、请勿用于商业用途
- 🌟 最佳实践:设为自动壁纸更换 + 脚本定期下载
📦 作者在这里已经整理好了必应近年来的壁纸,直接分享给大家
👉 2021-2025 必应绝美壁纸合集(夸克网盘,解压密码:lingxiaotian)
- 公众号后台回复
必应即可获取下载链接。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











