







1. OCR技术简介
OCR(Optical Character Recognition,光学字符识别)是一种将图像中的文字转换为可编辑文本的技术。它广泛应用于文档数字化、图片内容提取、身份证识别、车牌识别等多个领域。通过 OCR 技术,我们可以将纸质文档、扫描件、图片等中的文字信息提取出来,转换为电子文本,便于存储、编辑和分析。
1.1 OCR 应用场景
OCR通过图像预处理、文字定位、字符识别三个阶段,将像素数据转化为结构化文本,能够实现:
- 将纸质文档、扫描件等转换为可编辑的电子文档,提高办公效率。
- 从图片中提取文字信息,如从屏幕截图中提取文本,用于自动化测试等场景。
- 应用于身份证、驾驶证等证件信息的自动提取,简化信息录入流程。
- 广泛应用于智能交通、停车场管理等场景,实现车牌的自动识别。
- 支持表格识别,可应用于财务报表、问卷调查等场景的数据提取。
2.2 为什么选择Python实现OCR?
- 开源生态丰富(PaddleOCR、Tesseract等)
- 跨平台性(在 Windows、macOS、Linux 等多种操作系统上运行)
- 可集成到自动化工作流(如自动归档+数据分析)
2. PaddleOCR 库
飞桨 OCR(PaddleOCR)是百度开源的一款基于飞桨深度学习平台的光学字符识别(OCR)工具,具有高性能、易用性强、支持多种语言等特点,广泛应用于文档数字化、身份证识别、车牌识别等多个领域。
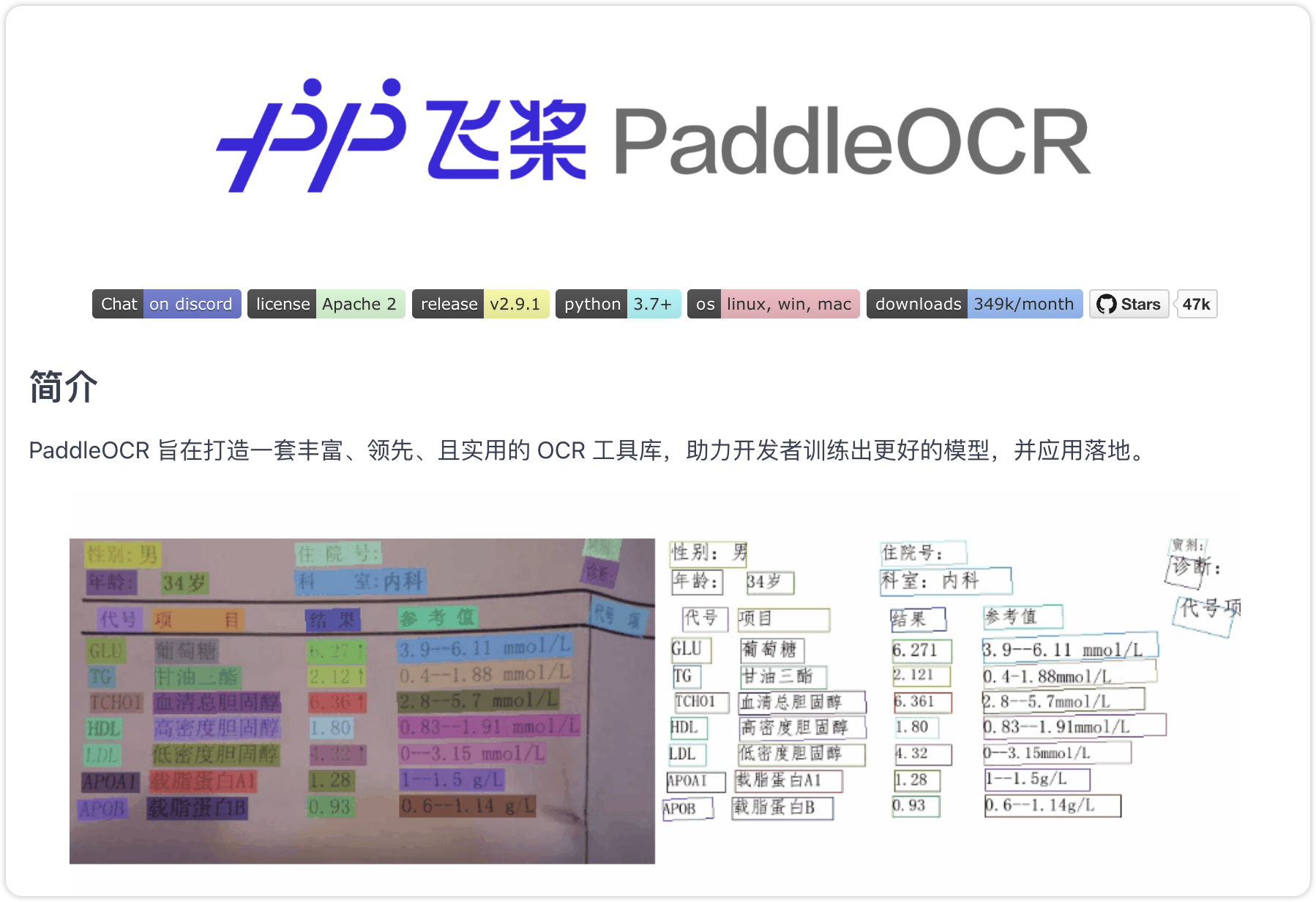
飞桨 OCR 具有以下特点:
- 高性能:采用先进的深度学习技术,识别速度快,准确率高。
- 轻量级:支持多种部署方式,包括服务器端、移动端和嵌入式设备,满足不同场景的需求。
- 多语言支持:支持多种语言识别,包括中文、英文、日文、韩文等。
2.1 环境部署
# 安装飞桨OCR核心库(需Python 3.7+)
pip install paddlepaddle paddleocr 注意:若运行时出现缺少某些 model,直接 pip 安装对应的模块即可。
2.2 基础功能实现
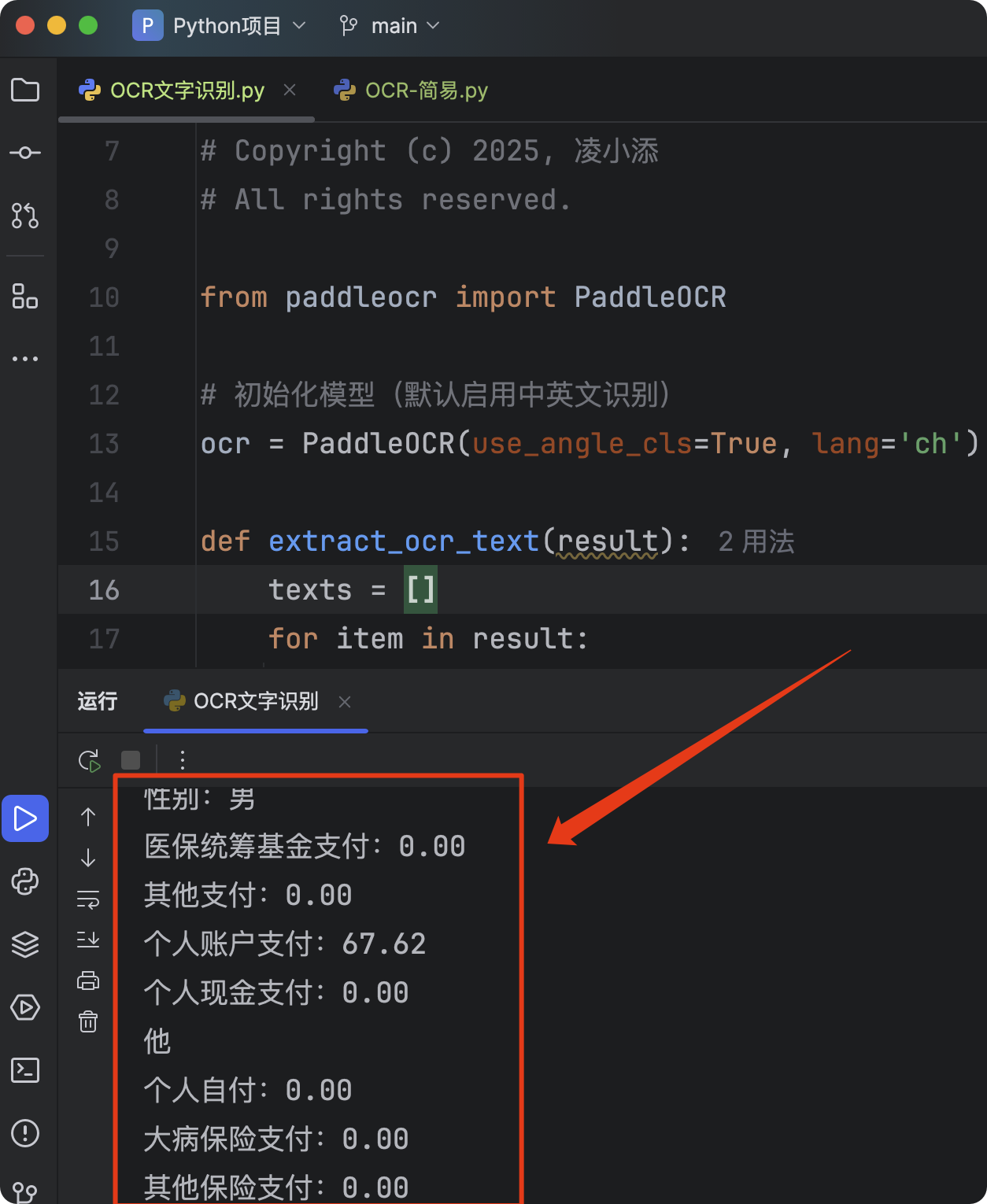
现在我们要识别一个票据中的内容,我们准备好这张票据.png的图片内容,放在代码同目录下。

完整代码:
from paddleocr import PaddleOCR
# 初始化模型(默认启用中英文识别)
ocr = PaddleOCR(use_angle_cls=True, lang='ch')
def extract_ocr_text(result):
texts = []
for item in result:
if isinstance(item, list):
texts.extend(extract_ocr_text(item))
# 如果当前元素是包含文字信息的元组(文本,置信度)
elif isinstance(item, tuple) and len(item) >= 2:
if isinstance(item[0], str): # 确保第一个元素是文本
texts.append(item[0])
elif isinstance(item, list) and len(item) >= 2:
if isinstance(item[1], tuple):
texts.append(item[1][0])
return texts
# OCR识别
result = ocr.ocr('票据.png', cls=True)
# 提取并打印所有文本
all_texts = extract_ocr_text(result)
for text in all_texts:
print(text)其中我们需要配置模型,并调用输出即可,需要修改的参数也不多:
ocr = PaddleOCR(use_angle_cls=True, lang='ch')设置中英文通用模型cr.ocr('票据.png', cls=True)输入图片路径
运行结果:
2.3 手写体文字识别
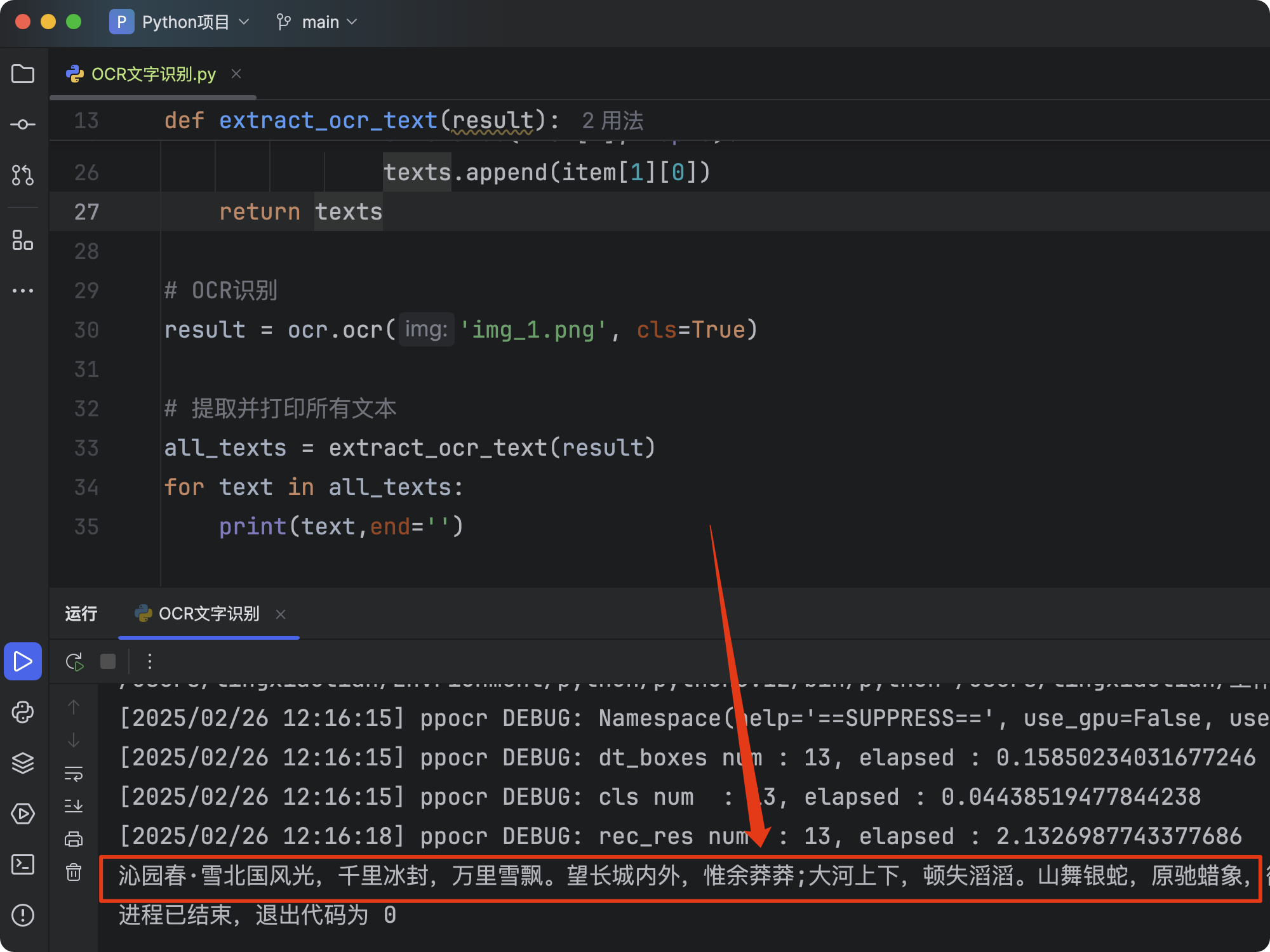
那这样的印刷体可以识别,那如果是手写体呢?我们试试看。
我们把这张图片丢给代码去识别:

输出结果:程序依然可以正确识别内容!
2.4 参数配置
在看完简单案例后,我们来详细了解下PaddleOCR的各种配置。
在初始化PaddleOCR对象时,可通过以下参数优化识别效果:
ocr = PaddleOCR(
use_angle_cls=True, # 启用文字方向检测(适合倾斜文本)
lang='ch', # 语言类型:ch(中文)、en(英文)、japan(日文)等
use_gpu=False, # 是否使用GPU加速
rec_model_dir='./models/ch_ppocr_server_v2.0_rec_infer', # 自定义识别模型路径
det_model_dir='./models/ch_ppocr_server_v2.0_det_infer', # 自定义检测模型路径
cls_model_dir='./models/ch_ppocr_mobile_v2.0_cls_infer', # 自定义方向分类模型路径
show_log=False # 关闭调试日志输出
) 参数说明表:
| 参数名 | 类型 | 默认值 | 作用 |
|
| bool | False | 是否检测文字方向(0/90/180/270度) |
|
| str | 'ch' | 支持80+语言组合,如 |
|
| int | 960 | 图片长边尺寸限制(超过会自动缩放) |
使用独立显卡可大幅提高处理速度,满足条件时非常推荐开启
GPU加速检测和配置:
# 检查GPU是否可用
import paddle
print(paddle.device.is_compiled_with_cuda()) # 输出True表示支持GPU
# 初始化时启用GPU
ocr = PaddleOCR(use_gpu=True) 注意,英伟达显卡用户需要安装 CUDA
地址:CUDA Toolkit - Free Tools and Training | NVIDIA Developer

3. 进阶操作
3.1 批量处理文件夹图片
如果我们需要批量识别图片,我们可以借助os库来遍历文件夹,并输出为单独的txt文本。
批量识别图片的示例:
import os
from paddleocr import PaddleOCR
ocr = PaddleOCR()
input_folder = 'input_images'
output_folder = 'ocr_results'
# 创建输出目录
os.makedirs(output_folder, exist_ok=True)
for filename in os.listdir(input_folder):
if filename.lower().endswith(('.png', '.jpg', '.jpeg')):
img_path = os.path.join(input_folder, filename)
result = ocr.ocr(img_path)
# 保存为独立文本文件
output_path = os.path.join(output_folder, f'{filename}.txt')
with open(output_path, 'w', encoding='utf-8') as f:
for line in result:
text = line[1][0]
f.write(text + '\n')
print(f'已处理 {len(os.listdir(input_folder))} 张图片') 3.2 结构化保存识别结果
如果我们不想将内容保存在txt格式中,我们也可以使用panda库保存到csv或者xlsx表格中。
需要更改的部分代码:
import pandas as pd
data = []
for line in result:
data.append({
'text': line[1][0],
'confidence': line[1][1],
'coordinates': line[0]
})
df = pd.DataFrame(data)
df.to_excel('structured_results.xlsx', index=False) 保存为json格式需要对内容进行预处理,下面是一个简单的未分类的示例:
import json
with open('result.json', 'w', encoding='utf-8') as f:
json.dump(result, f, ensure_ascii=False, indent=2) 3.3 调用DeepSeek处理文本
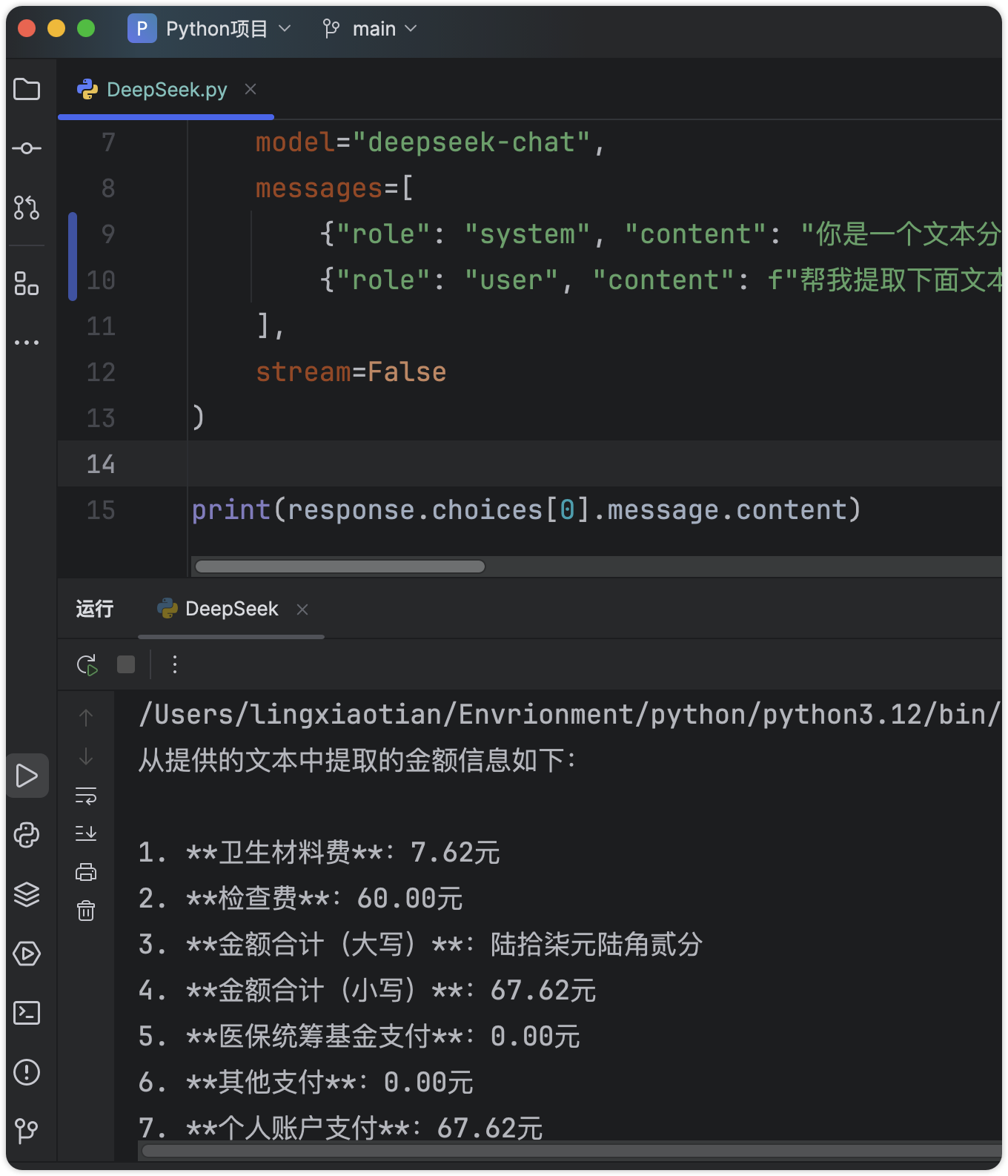
如果我们已经提取到了文本,但是文本内容太复杂,或者类型不同,规律性不强,我们还可用调用大模型来分析。
调用 DeepSeek 的示例代码:
from openai import OpenAI
# OCR提取文本
```
具体逻辑省略……
```
texts = texts
# 调用API
client = OpenAI(api_key="你的DeepSeek API", base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是一个文本分析机器人"},
{"role": "user", "content": f"帮我提取下面文本中的金额信息,格式化输出,不要用md语法……内容:{texts}"},
],
stream=False
)
print(response.choices[0].message.content)DeepSeek 解析结果:
3.4 多线程批量处理
为了提高运行速度,我们也可以加入多线程,使用concurrent.futures模块
一个多线程并发的示例:
from concurrent.futures import ThreadPoolExecutor
def process_image(img_path):
result = ocr.ocr(img_path)
return [line[1][0] for line in result]
with ThreadPoolExecutor(max_workers=4) as executor:
results = list(executor.map(process_image, image_paths)) 4. 其他OCR库
4.1 Tesseract:经典开源OCR引擎
核心特点:
- 由谷歌维护,社区生态成熟
- 支持100+语言(需单独下载语言包)
- 对印刷体英文识别精度高
安装与使用
# 安装库及英文语言包
pip install pytesseract
# Windows需单独安装Tesseract引擎:https://github.com/UB-Mannheim/tesseract/wikiimport pytesseract
from PIL import Image
# 多语言识别示例(中英文混合)
text = pytesseract.image_to_string(
Image.open('混合文本.jpg'),
lang='chi_sim+eng' # 中英文混合识别
)
print(text)适用场景
- 学术论文、书籍扫描件(英文为主)
- 多语言文档(需配置语言组合)
- 需要高度定制OCR模型的场景
4.2 EasyOCR:即用型多语言OCR
核心特点
- 开箱即用,预训练模型涵盖80+语言
- 支持中文、英文、日文、韩文等混合识别
- 对模糊、低光照图片鲁棒性强
安装与使用
pip install easyocr # 自动下载预训练模型import easyocr
# 初始化多语言模型
reader = easyocr.Reader(['ch_sim', 'en'])
# 识别文本并获取坐标
result = reader.readtext(
'广告牌.jpg',
detail=0, # 0: 只返回文本,1: 返回坐标+置信度
paragraph=True # 按段落合并文本
)
print('\n'.join(result))适用场景
- 路牌、广告牌等自然场景文字
- 多语言混合文档(如中英文合同)
- 需要快速验证OCR效果的场景
- ❌ 缺点:模型体积大(1GB+)、GPU资源消耗高
(图片位置提示:此处插入两组对比图)
图1-Tesseract效果:
英文论文扫描件 → 精准提取公式和段落
图2-EasyOCR效果:
中英文混合路牌 → 正确识别文字及排版
4.3 OCR工具选择
| 评估维度 | PaddleOCR | Tesseract | EasyOCR |
| 中文精度 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| 英文精度 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 安装便捷性 | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ |
选型建议:
- 中文场景优先选择PaddleOCR
- 纯英文文档使用Tesseract
5. 常见问题与解决方案
1️⃣ 报错ModuleNotFoundError
问题原因:缺少依赖库
解决方案:安装对应库
pip install setuptools pillow 2️⃣ 路径报错
现象:UnicodeDecodeError
修复:将图片路径改为全英文
3️⃣ 低分辨率图片识别率低
问题:文字模糊导致识别率暴跌
解决方案:对图片进行预处理
from PIL import ImageEnhance
img = Image.open('blur_text.jpg').convert('L') # 转灰度图
img = ImageEnhance.Contrast(img).enhance(2.0) # 增加对比度
img.save('enhanced.jpg') 4️⃣ 扭曲文字(如瓶盖文字)
解决方案:
# 使用PaddleOCR的版面分析功能
ocr = PaddleOCR(use_angle_cls=True, layout=True) 优化方法:
from PIL import ImageEnhance
img = Image.open('模糊图.jpg').convert('L')
img = ImageEnhance.Contrast(img).enhance(2.0)
img.save('优化后.jpg') 🌐 更多资源
- 预训练模型库:PaddleOCR Model Zoo
- 官方部署方案:PaddleServing部署指南


















 1973
1973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











