







代码仓库
会同步代码到 GitHub
https://github.com/turbo-duck/flink-demo
上节进度
上一节,已经实现了 Flink + Kafka + Redis 的相关配置和代码。
Kakfa Redis In Docker

KafkaProducer
StartApp
这里没有数据是正常的,因为都 写入到 Redis 了,并没有进行计算。
Redis数据
滚动窗口
Flink 中的滚动窗口(Tumbling Window)是一种常见的窗口机制,用于对数据流进行分割和处理。在滚动窗口中,时间驱动是窗口触发和关闭的关键机制。
什么是滚动窗口?
滚动窗口将数据流按照固定的时间间隔进行分割,每个时间间隔形成一个独立的窗口。滚动窗口的特点是窗口之间不重叠,每个元素只属于一个窗口。
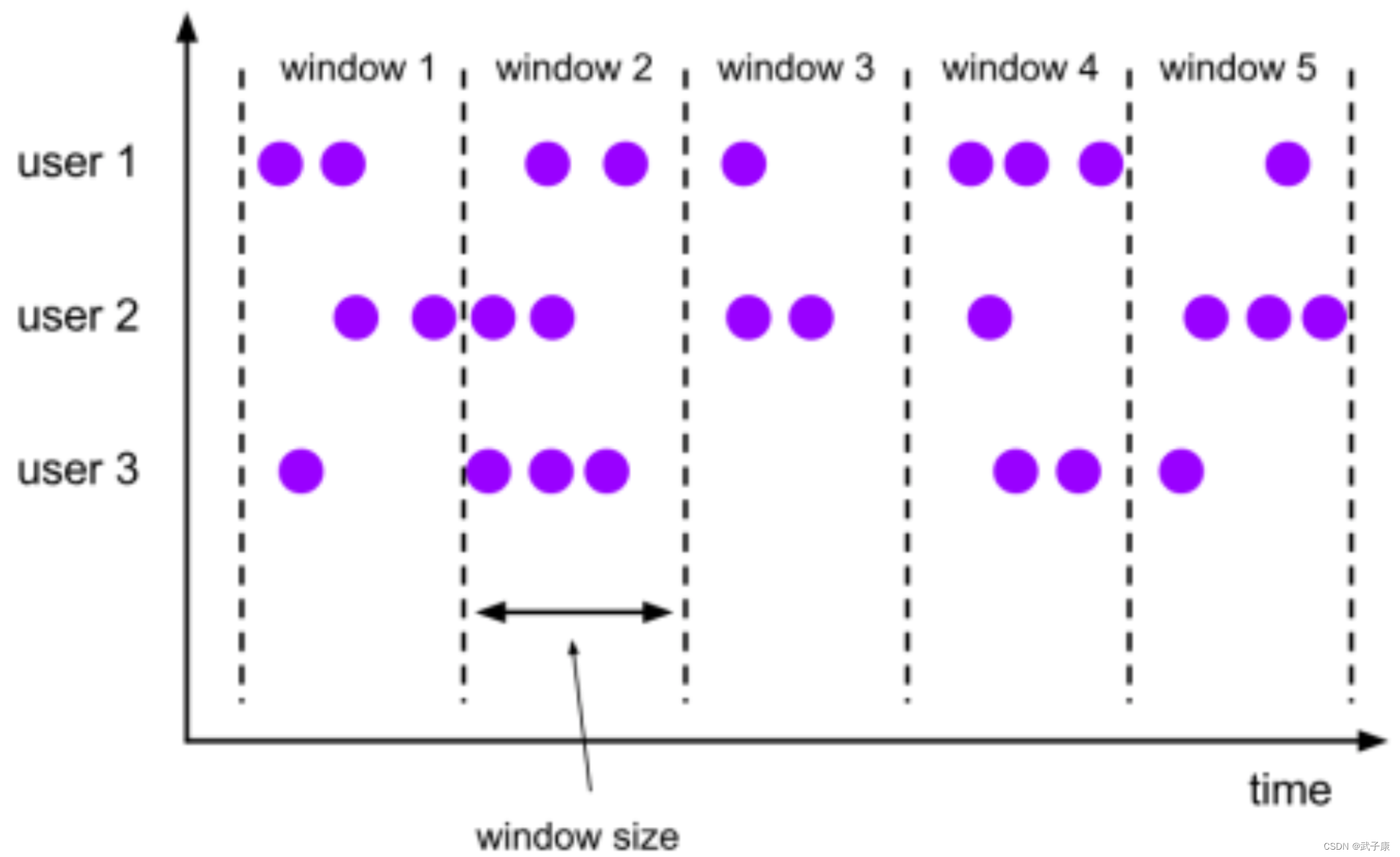
时间驱动
核心代码
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> timeWindow = keyedStream
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));
timeWindow.apply(new MyTimeWindowFunction()).print();
StartApp
package icu.wzk.demo06;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.api.java.tuple.Tuple2;
import java.text.SimpleDateFormat;
import java.util.Random;
/**
* 滚动时间窗口 Tumbling Window
* 时间对齐,窗口长度固定,没有重叠
* @author wzk
* @date 10:48 2024/6/22
**/
public class TumblingWindow {
private static final Random RANDOM = new Random();
public static void main(String[] args) throws Exception {
//设置执行环境,类似spark中初始化sparkContext
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<String> dataStreamSource = env.socketTextStream("0.0.0.0", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = dataStreamSource.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
long timeMillis = System.currentTimeMillis();
int random = RANDOM.nextInt(10);
System.out.println("value: " + value + " random: " + random + "timestamp: " + timeMillis + "|" + format.format(timeMillis));
return new Tuple2<>(value, random);
}
});
KeyedStream<Tuple2<String, Integer>, String> keyedStream = mapStream
.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
});
// =============== 时间驱动 ============================
// 每隔10s划分一个窗口
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> timeWindow = keyedStream
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));
timeWindow.apply(new MyTimeWindowFunction()).print();
env.execute();
}
}
MyTimeWindowFunction
package icu.wzk.demo06;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.text.SimpleDateFormat;
/**
* 基于时间驱动 TimeWindow
* @author wzk
* @date 10:26 2024/6/22
**/
public class MyTimeWindowFunction implements WindowFunction<Tuple2<String,Integer>, String, String, TimeWindow> {
@Override
public void apply(String s, TimeWindow window, Iterable<Tuple2<String, Integer>> input, Collector<String> out) throws Exception {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
int sum = 0;
for(Tuple2<String,Integer> tuple2 : input){
sum +=tuple2.f1;
}
long start = window.getStart();
long end = window.getEnd();
out.collect("key:" + s + " value: " + sum + "| window_start :"
+ format.format(start) + " window_end :" + format.format(end)
);
}
}















 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









