







章节内容:
上一节完成:
- HDFS 文件操作
- WordCount 案例 分布式运行
- 查看运行结果
背景介绍
这里是三台公网云服务器,每台 2C4G,搭建一个Hadoop的学习环境,供我学习。
之前已经在 VM 虚拟机上搭建过一次,但是没留下笔记,这次趁着前几天薅羊毛的3台机器,赶紧尝试在公网上搭建体验一下。
注意,如果你和我一样,打算用公网部署,那一定要做好防火墙策略,避免不必要的麻烦!!!
请大家都以学习为目的,也请不要对我的服务进行嗅探或者攻击!!!
但是有一台公网服务器我还运行着别的服务,比如前几天发的:autodl-keeper 自己写的小工具,防止AutoDL机器过期的。还跑着别的Web服务,所以只能挤出一台 2C2G 的机器。那我的配置如下了:
- 2C4G 编号 h121
- 2C4G 编号 h122
- 2C2G 编号 h123

请确保上一节内容全部完毕和跑通!!!
目前问题
在YARN中运行的任务生产的日志都看不了,所以如果需要查看程序历史的运行结果,需要配置历史服务器。
历史服务
mapred-site
修改 mapred-site.xml,在之前的基础上,添加如下的内容:
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>h121.wzk.icu:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>h121.wzk.icu:19888</value>
</property>

同步配置
通过分发脚本将脚本同步,你也可以手动都配置一下。
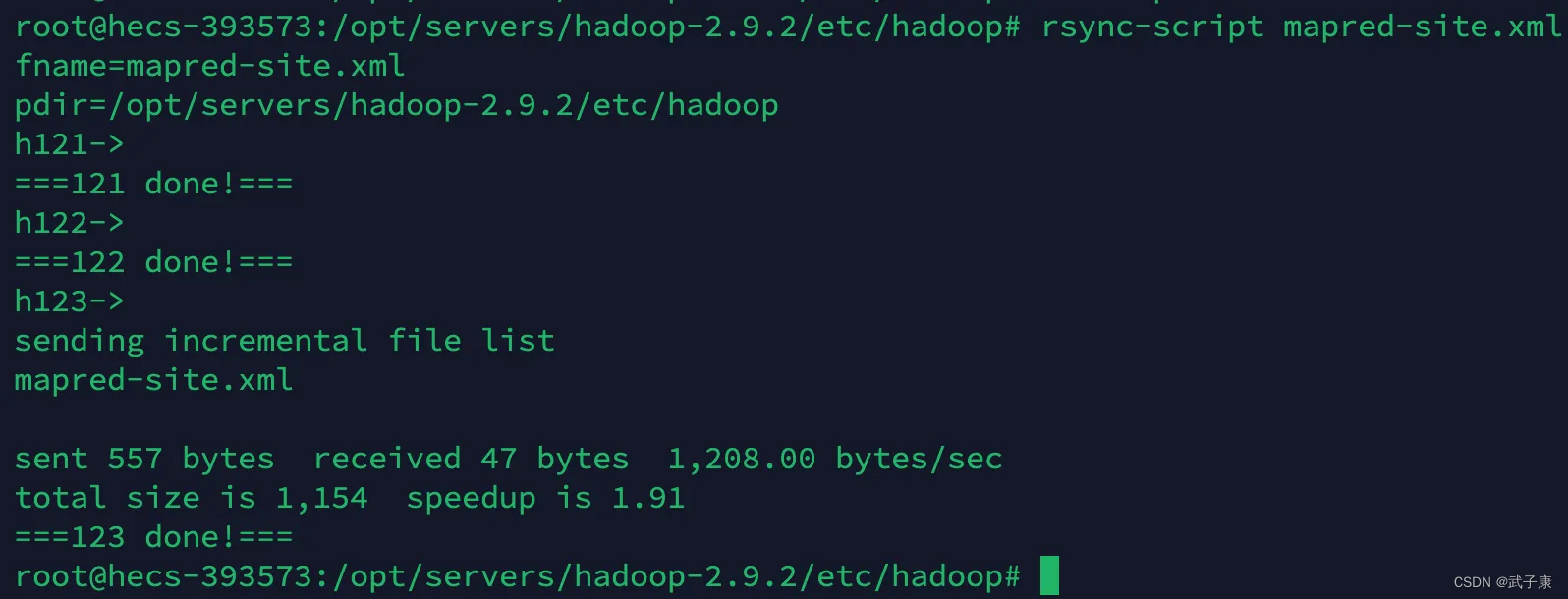
rsync-script mapred-site.xml
保证这三台节点的配置一致即可!
- h121
- h122
- h123
启动服务
在 h121 机器上运行
mr-jobhistory-daemon.sh start historyserver
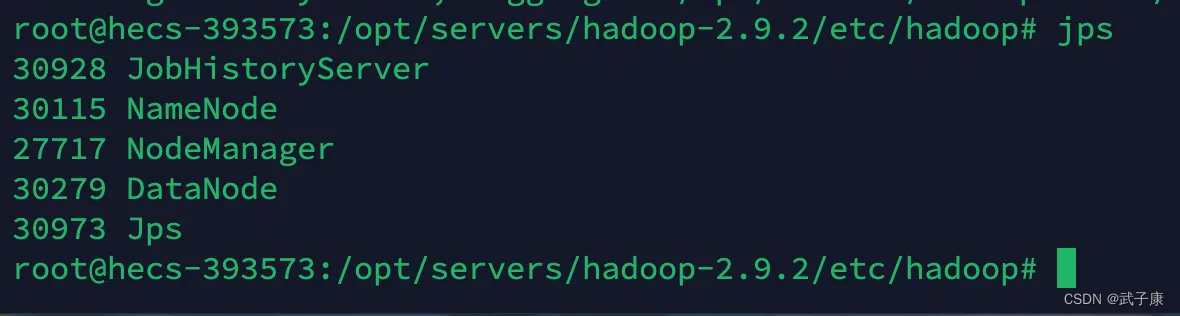
查看结果
jps
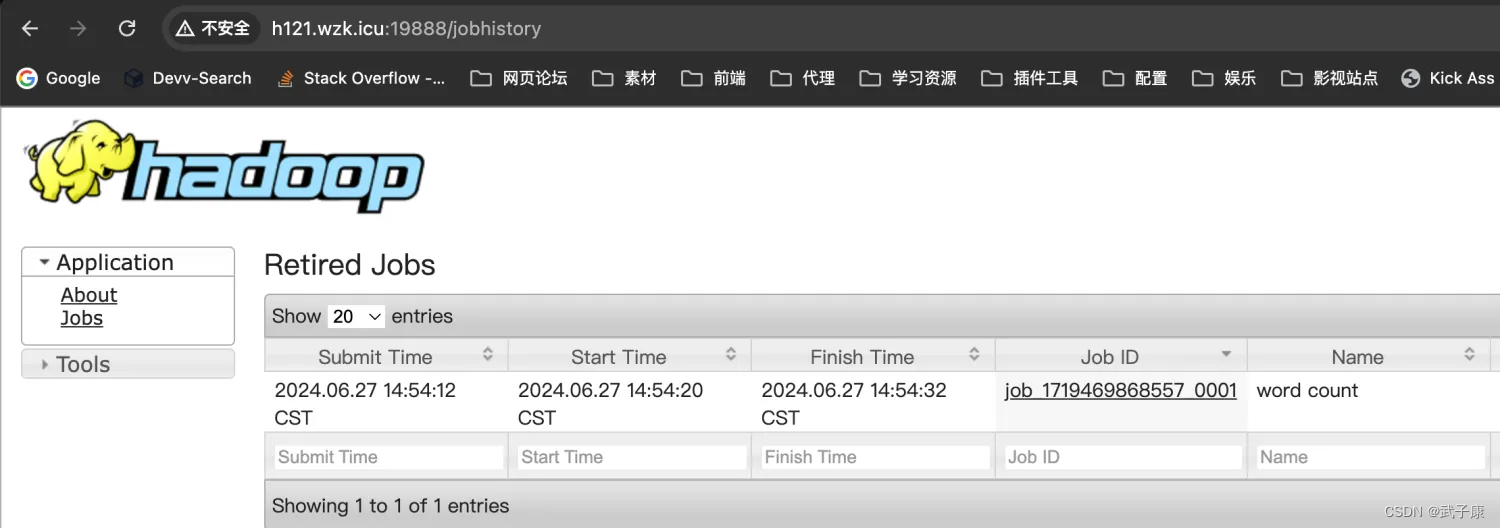
访问网页
http://h121.wzk.icu:19888/jobhistory
日志聚集
在 h121节点上修改 yarn-site.xml
修改为如下的内容:
vim yarn-site.xml
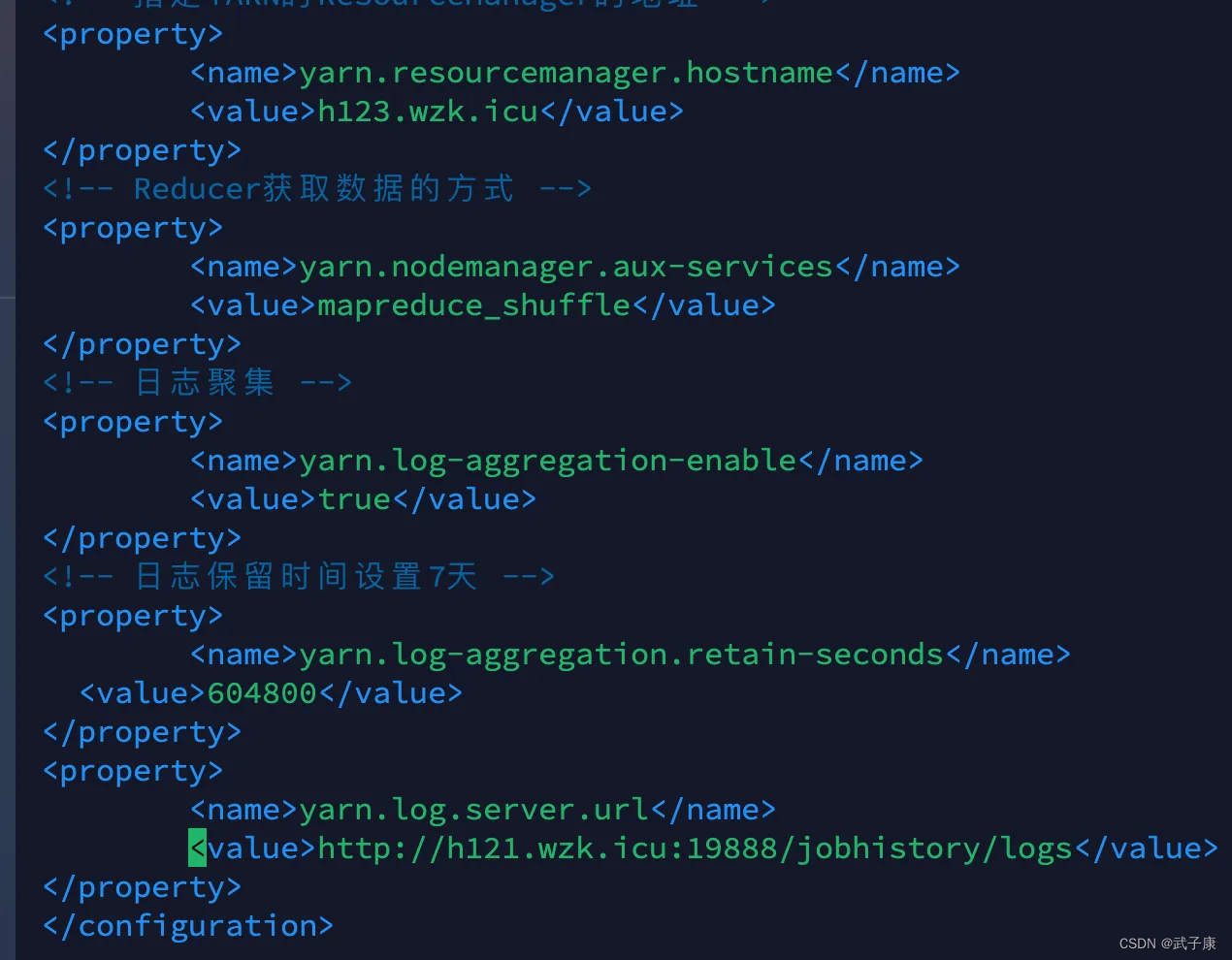
<!-- 日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://h121.wzk.icu:19888/jobhistory/logs</value>
</property>
修改截图如下:
同步配置
同样的,你也可以使用手动进行同步,只要保证配置是一致的即可
rsync-script yarn-site.xml
重启服务
在 h121 上进行操作:
yarn-daemon.sh stop resourcemanager
yarn-daemon.sh stop nodemanager
mr-jobhistory-daemon.sh stop historyserver
在 h121 上继续操作:
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
mr-jobhistory-daemon.sh start historyserver
测试效果
hdfs dfs -rm -R /wcoutput

运行测试
重新运行我们之前跑的 WordCount 的案例:
cd /opt/servers/hadoop-2.9.2
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wcinput /wcoutput
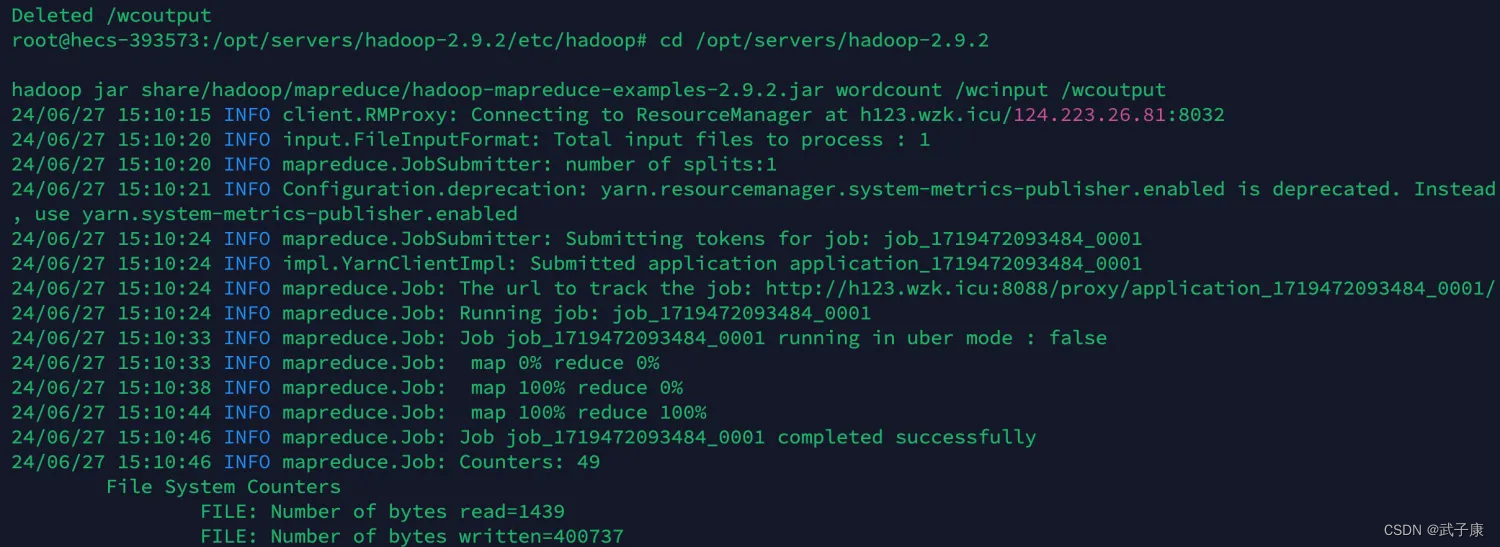
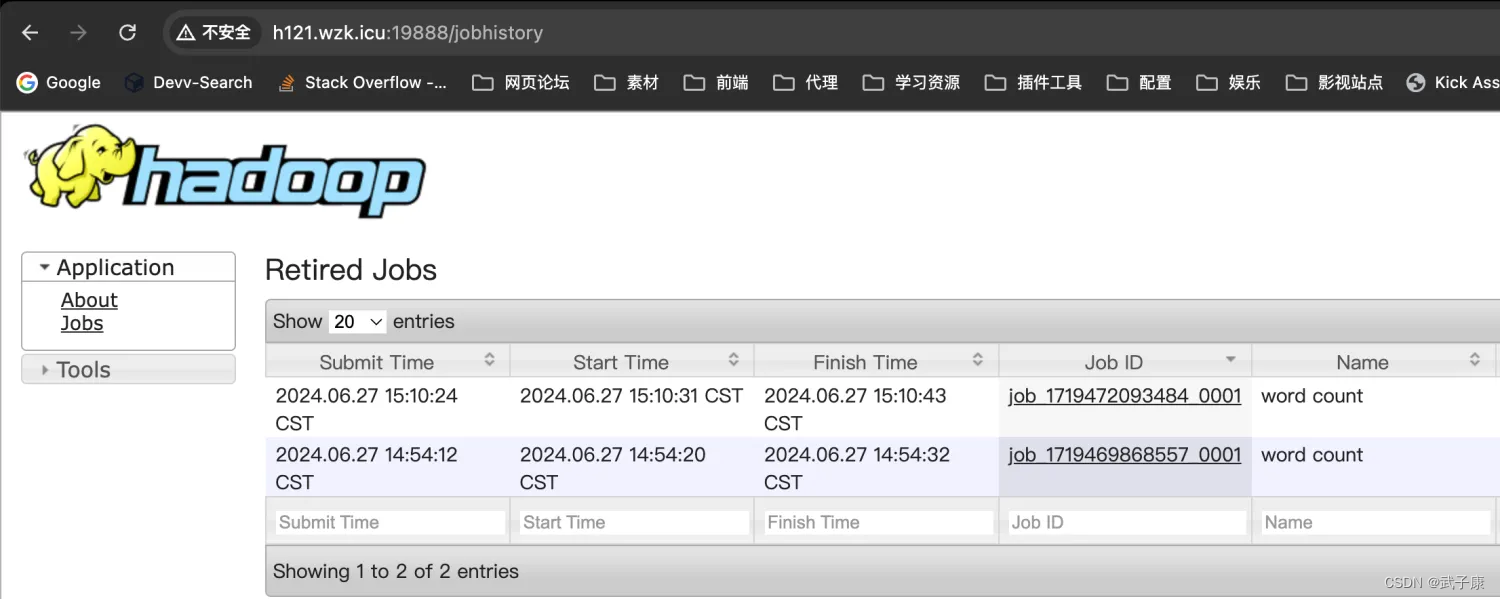
查看日志
http://h121.wzk.icu:19888/jobhistory















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









