









一.java.net.UnknownHostException: seacluster
在presto on yarn启动之后,在presto-cli控制台访问hive的数据库,不论是show schemas还是show tables都能成功
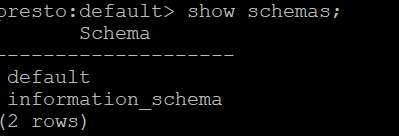
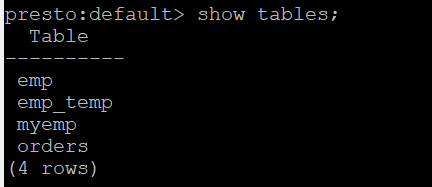
但是真正用sql去查询表的时候,却会报java.net.UnknownHostException: seacluster。原因是上面两个语句是访问hive的metadata,而select table是访问hdfs上的文件,需要访问hdfs

这里的seacluster是我的集群名字nameservers,这个指向我集群里面两个namenode做的HA。

在core-site.xml里面的设置是
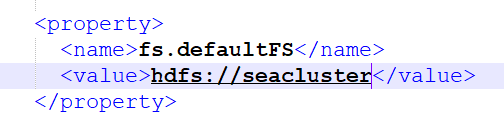
在查询了各种文章均没有特别的启发,自己想应该是哪里配置问题。在访问hive的时候需要加载core-site.xml,hdfs-site.xml,启动presto的主节点引用该文件的地址是/usr/local/share/prestoyarn/slider-0.92.0-incubating-all/hive2

这个地址是配置在appConfig-default.json里面的site.global.catalog配置项的,这个地址难道存在问题吗?于是我去查看某个子节点里面生成的配置/var/lib/presto/etc/catalog/hive2.propertis,地址也是这个,突然间我似乎明白了,子节点的这个目录和文件是不存在的啊,那么presto分发任务到这个节点的时候,这个节点去访问hive是读取不到这几个文件的,这样去访问肯定是识别不了seacluster域名的,问题就出现了。

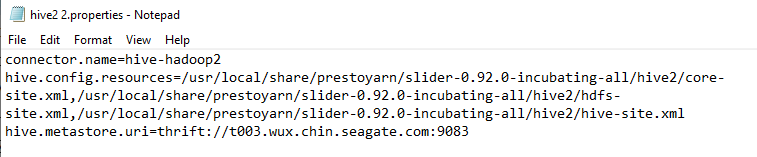
于是我将这几个文件分别拷贝到每个节点的同一目录下/usr/local/share,并将appConfig-default.json里面的site.global.catalog访问hive的地址改为这个目录


重启presto on yarn,select表成功。并且在namenode漂移到standby节点后,再select也是成功的。此问题解决。

ps:当然此问题我最初的解决办法不是这样的,当时发现这个问题是觉得子节点没有访问域名是因为无法识别,于是再/etc/hosts里面去设置这个seacluster的对应主机名,这样设置后也能访问了。但是问题是当namenode节点漂移时,需要每次来修改这个对应关系,每个节点都要设置,是很麻烦的。为了解决这个问题,出现了上面的方案。

二.presto节点重启或掉线后重新加入问题。
修改resources-default.json里面yarn.component.placement.policy为2
{
"schema": "http://example.org/specification/v2.0.0",
"metadata": {
},
"global": {
"yarn.vcores": "1"
},
"components": {
"slider-appmaster": {
},
"COORDINATOR": {
"yarn.role.priority": "1",
"yarn.component.instances": "1",
"yarn.component.placement.policy": "2",
"yarn.memory": "15360",
"yarn.label.expression": "coordinator"
},
"WORKER": {
"yarn.role.priority": "2",
"yarn.component.instances": "7",
"yarn.component.placement.policy": "2",
"yarn.memory": "15360",
"yarn.label.expression": "worker"
}
}
}重启presto,然后reboot其中一台节点exmp:t011,此时监控界面会显示少一个几点

t011重启成功后,拉起yarn相关的服务。

在yarn的application界面会显示该节点lost,且重启了一个container,t011的container_1584422422428_0009_01_000009是第一次启动的,container_1584422422428_0009_01_000012是在t011的009container lost之后,重新启动的一个container。

ps:拉起presto服务的时候会有个问题,yarn在t011挂了之后,会重新在资源池里去重新启动一个container,此时经常会在已经跑了presto任务的的机器上再启动一个container,再同一个机器上启动两个container会失败,失败原因可能是端口占用,二此时尝试了多次之后,会使得yarn的这个presto任务整个挂掉,导致presto集群挂掉。
有个办法是在resources-default.json的component配置里面,将yarn.memory尽量调大,我测试时机器有48G内存,这里我设置了35G,然后再启动。后面有worker节点挂掉时,yarn就不会再找已有presto服务的节点再去启container了,会找新的机器节点。此问题暂且记下,等后续有更好的方案再更新
问题二参考:https://groups.google.com/forum/#!topic/presto-users/nlja-IO0GQw
















 3464
3464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









