







背景
研究 “B表里的数据是否全部都在A表里” 的问题,那种写法比较合理效率高?
假设有A表和B表,B表通过自身外键和A表关联,查出B表中的外键值不在A中的。
过程
假设我们有t_master和t_pet表,即主人和宠物表,t_pet通过master_id跟t_master的id关联。假设不做数据库层面的外键约束,则有可能出现一种情况:t_pet中某些数据找不到对应的t_master记录。
建表语句如下(实验的数据库是pgsql)
create table t_master(
id serial,
name varchar(32),
constraint t_master_pk primary key(id)
);
create table t_pet(
id serial,
master_id int4,
name varchar(32),
constraint t_pet_pk primary key(id)
);
insert into t_master(name) values('Stone');
insert into t_pet(master_id,name) values(1,'Tom');
insert into t_pet(master_id,name) values(2,'Jerry');
insert into t_pet(master_id,name) values(null,'Peppa');
1、写法1
我们一般会写如下的语句,但是我觉得这种语句的效率不高
select * from t_pet where master_id not in (select id from t_master);
这种是通过子查询的方式,子查询应该是需要中间在内存中缓存中间结果,我觉得这种执行效率不高,而且一般in和not in都不建议里面的元素太多,阿里巴巴的开发文档好像建议是不超过3000个。
这个请自行查看执行计划研究下,由于笔者用pg,不太方便去查看执行计划,就请读者自行对比其执行计划和第二种写法的执行计划。
2、写法2
select * from t_pet a
where not exists (select 1 from t_master b where b.id=a.master_id);
利用not exists来实现。这种我认为效率是比方法1高非常多的。
3、补充
补充上述两种写法的差别,不仅仅是方法2的效率更高,而且两者的执行逻辑是有区别的,有时候甚至是个大坑。
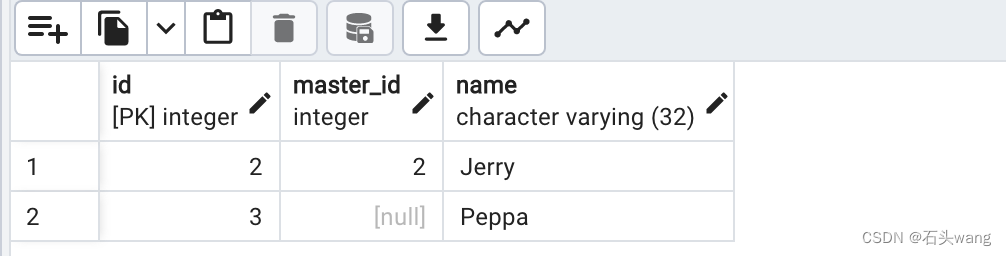
方法一执行的结果是:

有点奇怪的是null的那条记录有点意外地不在预期里头,而方法2更加符合我们的预期















 2926
2926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









