







 本文探讨了机器学习中误差的来源,包括偏差(Bias)和方差(Variance)。偏差大导致欠拟合,可通过增加特征或复杂模型解决;方差大导致过拟合,可通过增大数据量或正则化缓解。使用交叉验证来调整模型,并介绍梯度下降法及其学习率调整,如Adagrad和Stochastic Gradient Descent。特征缩放确保输入特征对损失的贡献均衡,而梯度下降可能陷入局部最优。
本文探讨了机器学习中误差的来源,包括偏差(Bias)和方差(Variance)。偏差大导致欠拟合,可通过增加特征或复杂模型解决;方差大导致过拟合,可通过增大数据量或正则化缓解。使用交叉验证来调整模型,并介绍梯度下降法及其学习率调整,如Adagrad和Stochastic Gradient Descent。特征缩放确保输入特征对损失的贡献均衡,而梯度下降可能陷入局部最优。
P5 误差
误差的来源
来源于两方面:Bias and Variance
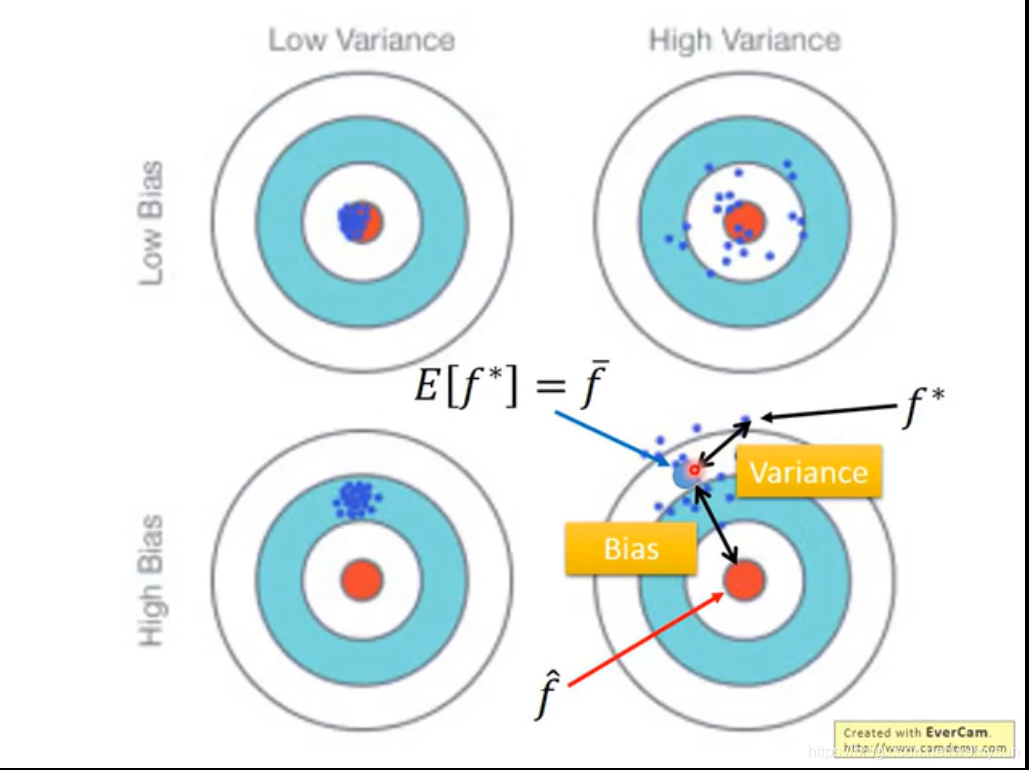
Bias
- 它是 f* 与 f^ 之间的差距
- bias大 是 underfitting(训练的就不好)
- 针对欠拟合,增加输入特征 或 构建复杂模型结构
Variance
- 它是 f(model set) 之间的差距
- variance大 是 overfitting (训练的好,但在测试上表现的不好)
- 针对过拟合,要增加数据量 或 regularization正则化更加平滑

以上两者要综合考虑,找到一个平衡点(bias 和 variance 都小),既不欠拟合也不过拟合。
How to do with error?
使用cross validation 交叉验证,training set 划分为training set 和 validation set。进一步地,使用n-fold cross validation 。
注:使用training set调整网络,而不是使用testing set 调整网络!
P6 梯度下降
是 获得最小 loss的过程中 更新参数 的方法
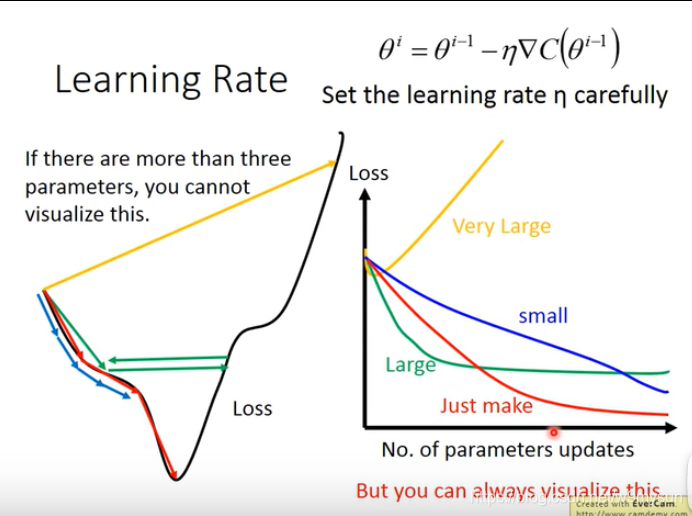
学习率
1.不能设置太大或者太小
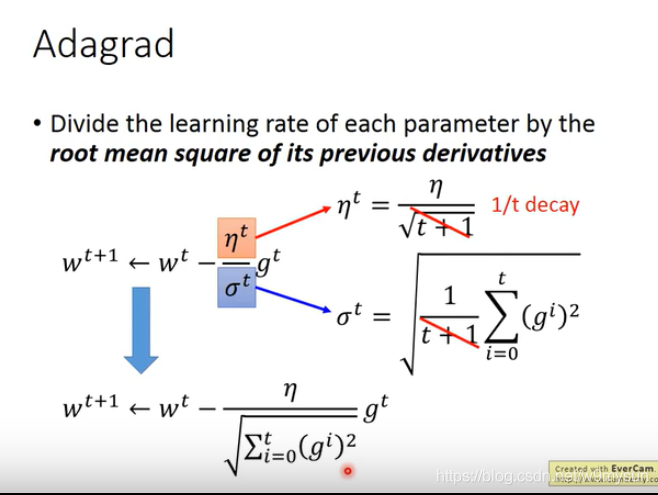
2. 自动调整learning rate: Adagrad (参数不同,lr不同)【g是梯度,梯度越大,步伐越大】
3. Stochastic gradient descent
gd是看完所有exampel后,才更新一次参数;sgd是 每看到一次example,就更新一次参数。【θ是参数】

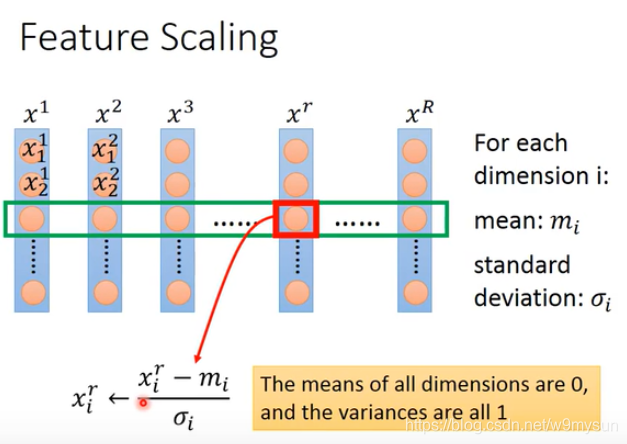
feature scaling
使得输入特征 x1,x2…xn对loss的影响 相对差不多。
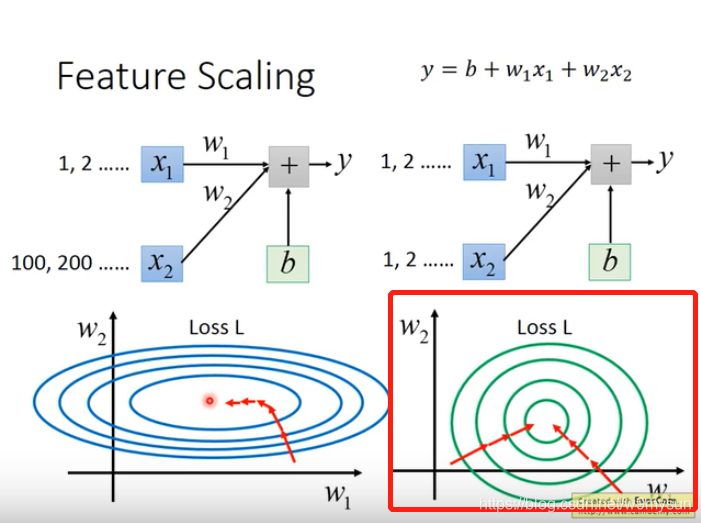
那如何 进行feature scaling,也就是 标准化。
GD 的限制
会卡在 local minima,或者说微分值为0

















 1790
1790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









