







使用python的requests库,就是跳过浏览器直接用脚本去访问服务器;
- 首先我们要知道服务器的url,然后先用浏览器模拟访问该url,获取浏览器的信息(user-agent)和cookie进行重置request_header
"cookie": "read_mode=day; default_font=font2; locale=zh-CN; __yadk_uid=tBJkWigvhZok7EuAKfwbks5CEThAs7SQ; Hm_lvt_0c0e9d9b1e7d617b3e6842e85b9fb068=1564490433,1564582799,1564584053; remember_user_token=W1sxODk0NTA5MF0sIiQyYSQxMSQ0cC5hNkFBWlZXdC5wTExLSm1xVWhlIiwiMTU2NDU4NDE1MC43ODU1MyJd--492bdf762eff89f4862fd1253125371c872f6f1c; _m7e_session_core=e791d2ac5b26540689c22156723f10a6; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2218945090%22%2C%22%24device_id%22%3A%2216c42e580991c4-076c7180f30ebe-c343162-2073600-16c42e5809a632%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%2216c42e580991c4-076c7180f30ebe-c343162-2073600-16c42e5809a632%22%7D; Hm_lpvt_0c0e9d9b1e7d617b3e6842e85b9fb068=1564585064", "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"
若是需要上传参数(写博文,评论,更改或获取具体信息),则需要使用post请求并在请求后面添加具体的参数
data = { 'content': "Just Try 一下!" + str(x), 'parent_id': 'null' } r = requests.post(url_writer, headers=header_writer, data=data)
一.登陆简书
import requests
from bs4 import BeautifulSoup
url = "https://www.jianshu.com/"
headers1 = {
# 记得每个参数之后要带“,”
# 不能带这些参数
# ":authority": "www.jianshu.com",
# ':method': 'GET',
# ":path": "/subscriptions",
# ":scheme": "https",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "max-age=0",
"cookie": "read_mode=day; default_font=font2; locale=zh-CN; __yadk_uid=tBJkWigvhZok7EuAKfwbks5CEThAs7SQ; Hm_lvt_0c0e9d9b1e7d617b3e6842e85b9fb068=1564490433,1564582799,1564584053; remember_user_token=W1sxODk0NTA5MF0sIiQyYSQxMSQ0cC5hNkFBWlZXdC5wTExLSm1xVWhlIiwiMTU2NDU4NDE1MC43ODU1MyJd--492bdf762eff89f4862fd1253125371c872f6f1c; _m7e_session_core=e791d2ac5b26540689c22156723f10a6; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2218945090%22%2C%22%24device_id%22%3A%2216c42e580991c4-076c7180f30ebe-c343162-2073600-16c42e5809a632%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%2216c42e580991c4-076c7180f30ebe-c343162-2073600-16c42e5809a632%22%7D; Hm_lpvt_0c0e9d9b1e7d617b3e6842e85b9fb068=1564585064"
,
'if-none-match': 'W/"49471185b1d3265f2d523c590b251605"',
"referer": "https://www.jianshu.com/notifications",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"
}
# requests库获取html请求
r = requests.get(url, headers=headers1)
# beautifulSoup库解析html文件
connect = BeautifulSoup(r.text, "html.parser")
# print(connect.text)
# 打印html页面
print(r.text)
print(r.status_code)首先自己在网页登录简书的账号,然后找到链接并复制request header用来当作我们请求头,前面部分的要去掉,估计requests请求的时候自带一部分的内容
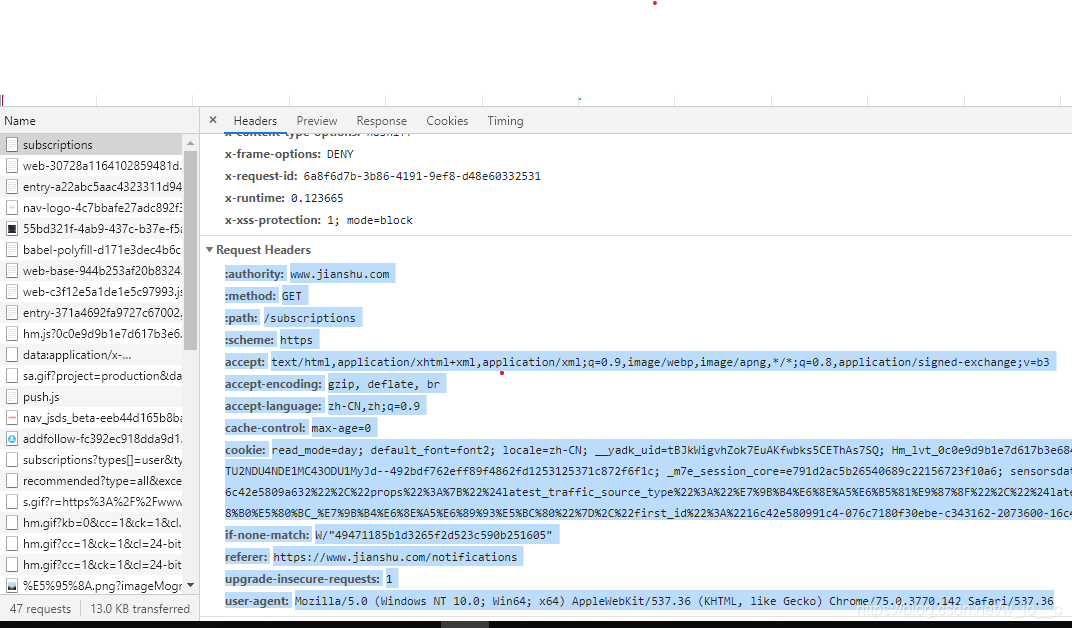
二.在文章里面评论
首先找到发送评论的url,以及参数名(可以在Chrome的开发者模式network获取,或者使用fiddle)
import requests
from bs4 import BeautifulSoup
import time
# 简书写文章
url_writer = "https://www.jianshu.com/notes/47346873/comments"
header_writer = {
# :authority: www.jianshu.com
# :method: POST
# :path: /notes/47346873/comments
# :scheme: https
# accept: application/json
# accept-encoding: gzip, deflate, br
# accept-language: zh-CN,zh;q=0.9
# content-length: 34
# content-type: application/json;charset=UTF-8
'cookie': 'read_mode=day; default_font=font2; locale=zh-CN; __yadk_uid=tBJkWigvhZok7EuAKfwbks5CEThAs7SQ; _m7e_session_core=29d8488b1360c5c5c82504b394f435e0; Hm_lvt_0c0e9d9b1e7d617b3e6842e85b9fb068=1564490433,1564582799,1564584053,1564673087; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2218945090%22%2C%22%24device_id%22%3A%2216c42e580991c4-076c7180f30ebe-c343162-2073600-16c42e5809a632%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%2216c42e580991c4-076c7180f30ebe-c343162-2073600-16c42e5809a632%22%7D; Hm_lpvt_0c0e9d9b1e7d617b3e6842e85b9fb068=1564673722',
'origin ': 'https://www.jianshu.com ',
'referer': 'https://www.jianshu.com/p/5d4091cfdbc9',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
'x-csrf-token': '0vcu/8mVFisy9QHdnNK/I3nsyesq7Rzaf7mSj7kj49XuQUUKyZbvEGVw3XVkbbU2kub8c34EJBTO1/a3daSPwQ=='
}
# requests库获取html请求
x = 5
while x:
data = {
'content': "Just Try 一下!" + str(x),
'parent_id': 'null'
}
r = requests.post(url_writer, headers=header_writer, data=data)
x = x-1
print(data['content'])
time.sleep(2)
# beautifulSoup库解析html文件
connect = BeautifulSoup(r.text, "html.parser")
# print(connect.text)
# 打印html页面
print(r.text)
print(r.status_code)















 1711
1711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









