






有需要这本书的pdf资源的可以联系我~
这本书不是偏向于非常详细的教你很多函数怎么用,更多的是交个基本使用,主要是后面的深度学习相关的内容。
1.Numpy提供两种基本的对象:ndarray(n维数组对象)(用于储存多维数据)和ufunc(通用函数对象,用于处理不同的数据)。
2.numpy的主要优点:ndarray提供了很多数组化的运算,并且可以快读对数组进行操作,不用写循环来操作。
3.numpy是外部的库,使用的话需要导入先,没有库可以安装。
4.使用时候要导入numpy
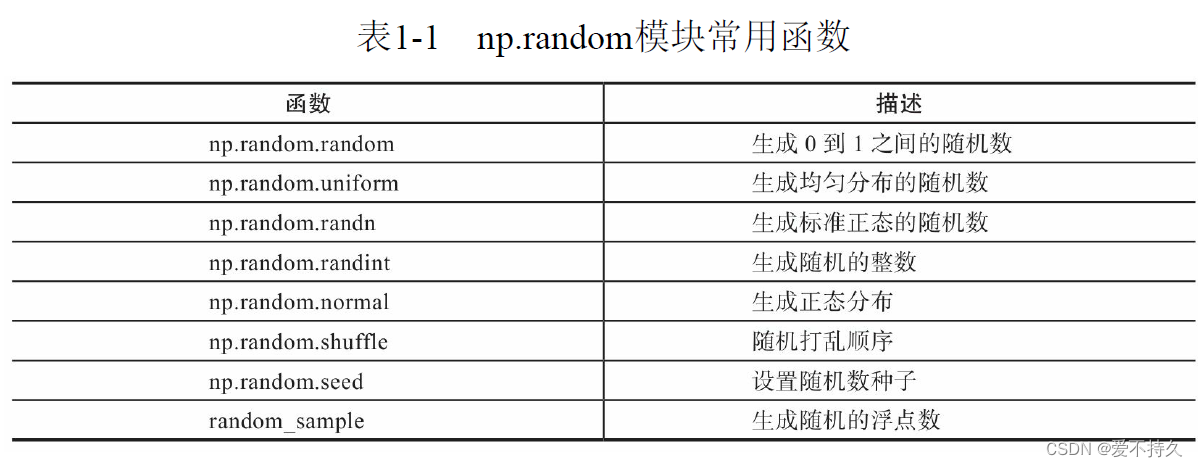
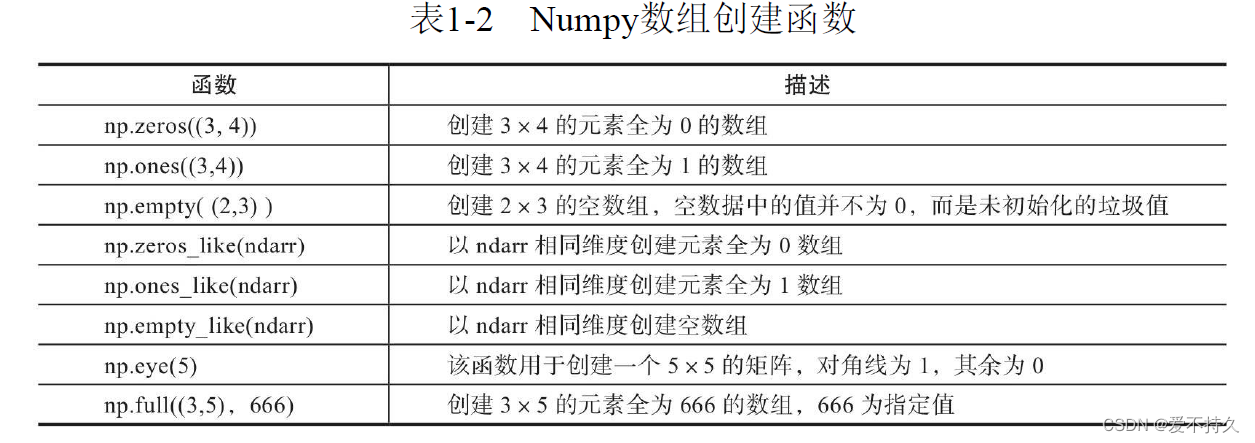
5.创建ndarry的方法
注意:
range是个范围一般是用在for里的
arange是一种快捷生成方式,几到几隔几个这种,或者直接生成然后reshape
array一般用于生成有具体内容的ndarry
import numpy as np
#1.使用转换函数将现有的list或者元组转换为ndarry
list1=[[3.14,2.17,0,1,2],[3,44,2.22,55,9]]
nd1=np.array(list1)
print(nd1)
#2.use the random to generate the ndarry
nd2=np.random.random([3,3])
print(nd2)
#指定了seed之后就会生成固定的内容
nd3=np.random.random([3,3])
print(nd3)
#3.使用便捷生成函数zeros、ones等,可可以将生成的结果进行保存
nd4=np.zeros((3,4),int)#默认是float类型
np.savetxt(X=nd4,fname='./test1.txt')
print(nd4)
#4.使用arange和linspace函数生成数组
nd4=np.arange(4,50,12)#4-50 per 12 ,no including 50
print(nd4)
nd5=np.arange(9,-1,-2)#倒着生成需要在步长前添加-
print(nd5)
nd6=np.linspace(0,4,8)#在0-4之间均匀的生成8个,包含起点和终点,等差数列
print(nd6)
nd7=np.logspace(0,4,8,base=2)#等比数列
print(nd7)6.获取元素
#获取元素
nd8=np.random.random(10)
print(nd8)
print(nd8[3])#从0开始算,其实是第四个
print(nd8[3:6])#索引为3的开始一直到索引为5,不包括6
print(nd8[1:6:2])#索引1到索引5,每隔1个取一个
print(nd8[1:6:1])#每隔0个,也就是挨个取
print(nd8[::-2])#倒序每隔两个
nd9=np.arange(25).reshape([5,5])
print('nd9:',nd9)
print('second and third row:',nd9[1:3,:])#指定行,先行后列
print('second and third row:',nd9[[1,2]])#指定行
print('second and third cloum:',nd9[:,1:3])#指定列
print(nd9[1:5,1:3])#先行后列
print('range[2,8]:',nd9[(nd9>2)&(nd9<8)])#筛选7.运算
#算数运算
#主要用到的就是乘法:普通乘法(对应元素相乘)和点乘(内积)
A = np.array([[1,2],[3,4]])
B = np.array([[5,6],[7,8]])
C = np.array([3,5,6])
print(A)
print(B)
print(A*B)#数乘
print(np.multiply(A,B))#数乘
print(3*A)#数乘
print(B/3.0)#数乘
D = np.random.rand(4,2)
def softmoid(x):#定义一个函数
return 1/(1+np.exp(-x))
print(D)
print(softmoid(D))
print(softmoid(D).shape)#输出数据的shape,就是形状大小
print(np.shape(D))#函数的形式输出和上面是一样的意思
print(softmoid(D).size)#size是个数
X1 = np.array([[1,2],[3,4]])
X2 = np.array([[5,6,7],[8,9,10]])
print(np.dot(X1,X2))8.数组变形
#数据变形
#reshape()改变维度,不改变数组本身
X1 = np.arange(10)
print(X1)
print(X1.reshape(2,5))
print(X1.reshape(-1,5))
print(X1)
#resize改变维度,改变数组本身
print(X1.resize(2,5))
print(X1)
#转置
print(X1.T)
#展平如果我们将 order 参数设置为“C”,则意味着数组以行优先顺序展平。
#如果设置了“F”,则数组将按列优先顺序展平。
#仅当“A”在内存中是 Fortran 连续的并且我们将 order 参数设置为“A”时,数组才以列优先顺序展平。
#最后一个顺序是“K”,它以与元素在内存中出现的顺序相同的顺序展平数组。默认情况下,此参数设置为“C”。
print(X1.ravel())#按照行展平,default
print(X1.ravel('F'))#按照列展平
print(X1.ravel('C'))#按照行展平
#flatten 把矩阵转换为向量,这种需求经常出现在卷积网络与全连接层之间。
a =np.floor(10*np.random.random((3,4)))#floor取整
print(a)
print(a.flatten())
#squeeze降维 这是一个主要用来降维的函数,把矩阵中含1的维度去掉,不改变原变量。在PyTorch中还有一种与之相反的操作——torch.unsqueeze
arr1 = np.arange(3).reshape(3,1)
print(arr1)
print(arr1.shape)
print(arr1.squeeze())
print(arr1.squeeze().shape)
print(arr1)
print(arr1.shape)
arr2 =np.arange(6).reshape(3,1,2,1)#
print(arr2)
print(arr2.shape)
print(arr2.squeeze().shape)
print(arr2.squeeze())#去掉了两个维度,就是为1的维度
#transpose 对高维矩阵进行轴对换,这个在深度学习中经常使用,比如把图片中表示颜色顺序的RGB改为GBR
arr3 = np.arange(24).reshape(2,3,4)
print(arr3)
print(arr3.shape)
print(arr3.transpose(1,2,0))#索引代表了如何进行轴对换0和2换,1在和2换
print(arr3.transpose(1,2,0).shape)9.合并

#数组合并,按照行合并就是按照行往下走,合并到下面;按照列合并就是往右走,放到右边
#1.append
a=np.array([1,2,3])
b=np.array([4,5,6])
print(np.append(a,b))#合并一维数组
c=np.arange(4).reshape(2,2)
d=np.arange(4).reshape(2,2)
print(np.append(c,d,axis=0))#=0按照行合并
print(np.append(c,d,axis=1))#=1按照列合并
#2.concatenate按照指定轴连接数组或矩阵,要连接的那个方向维度大小要一致
e = np.array([[1,2],[3,4]])#2*2
f = np.array([[5,6]])#2*1
print(np.concatenate((e,f),axis=0))
#print(np.concatenate((e,f),axis=1))#列的尺寸不一样 会报错,可以转置之后再拼接
print(np.concatenate((e,f.T),axis=1))
#3.stack 沿着制定轴堆叠数组和矩阵,只是单纯的堆叠
print(np.stack((e,e),axis=0))10.批处理
#批处理:1.获得数据集2.打乱3.定义批大小4.处理
data_train = np.random.randn(10000,2,3)#create 10000 2*3 ndarry
print(data_train.shape)
np.random.shuffle(data_train)#打乱
batch_size = 100
for i in range(0,len(data_train),batch_size):
x_batch_sum = np.sum(data_train[i:i+batch_size])
print('第{}批,该批次之和:{}'.format(i,x_batch_sum))11.通用函数
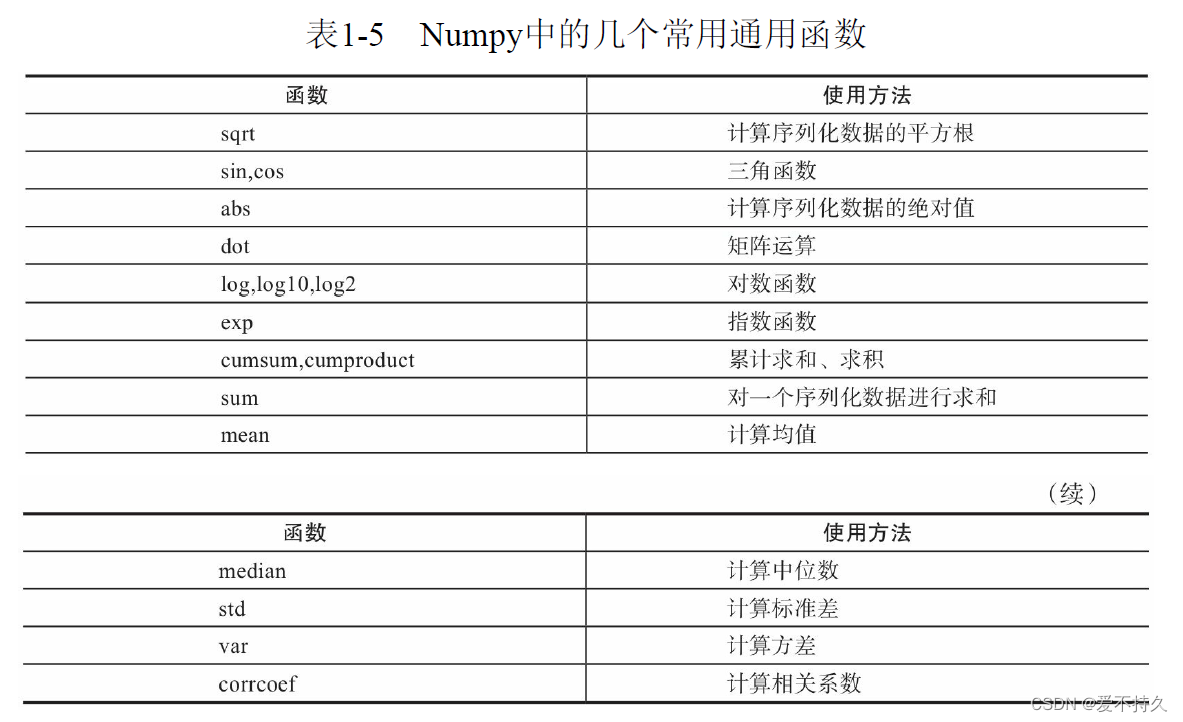
#通用函数 ufunc 对数组的每个元素进行处理的一类函数 。
#math模块的输入一般是标量,但Numpy中的函数可以是向量或矩阵,而利用向量或矩阵可以避免使用循环语句,这点在机器学习、深度学习中非常重要
x=[i*0.001 for i in np.arange(1000000)]
start = time.perf_counter()#计时器开始,到最后在记一次然后减去最初的
for i,t in enumerate(x):
x[i]=math.sin(t)#math中必须对每个元素逐个sin
print ("math.sin:", time.perf_counter() - start )
y = [i * 0.001 for i in np.arange(1000000)]
y = np.array(y)
tic = time.process_time()#计时器
np.sin(y)#可以直接对ndarry来使用
toc = time.process_time()
print ("numpy.sin:", toc - tic )11.广播机制:就是补齐数组,让shape相同
#广播机制:也就是数组的shape不一致时,会自动补齐
#补齐规则:
#1.让所有输入数组都向其中shape最长的数组看齐,不足的部分则通过在前面加1补齐a:2×3×2 b:3×2 则b向a看齐,在b的前面加1,变为:1×3×2
#2.输出数组的shape是输入数组shape的各个轴上的最大值
#3.如果输入数组的某个轴和输出数组的对应轴的长度相同或者某个轴的长度为1时,这个数组能被用来计算,否则出错
#4.当输入数组的某个轴的长度为1时,沿着此轴运算时都用(或复制)此轴上的第一组值
#官网http://www.Numpy.org/Pytorch的学习
1.numpy和tensor的最大的区别就是Numpy会把ndarray放在CPU中进行加速运算,而由Torch产生的Tensor会放在GPU中进行加速运算,如果有GPU的话。
2.使用tensor操作函数主要有两种:一种是torch.add(x,y)一种是x.add(y)。一种是从torch函数角度出发,一种是从tensor出发。

3.每个函数都可以实现修改原变量,运行符带下划线后缀

4.创建tensor
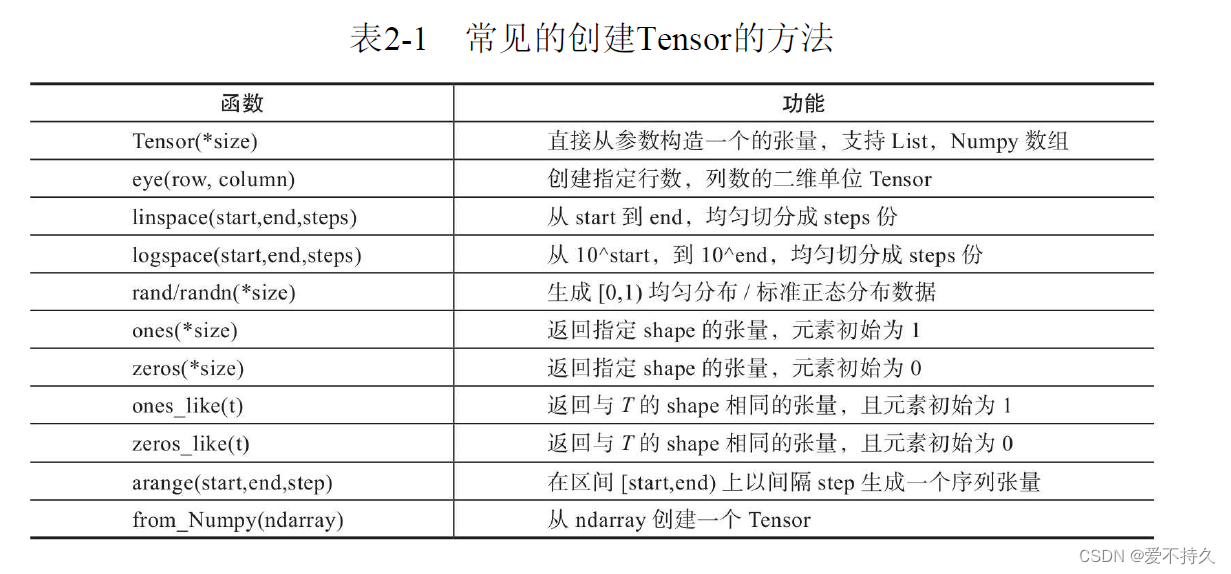
最好用Tensor,大写T的指令tensor和Tensor有一些区别,用Tensor更方便,tensor(2,3)会报错
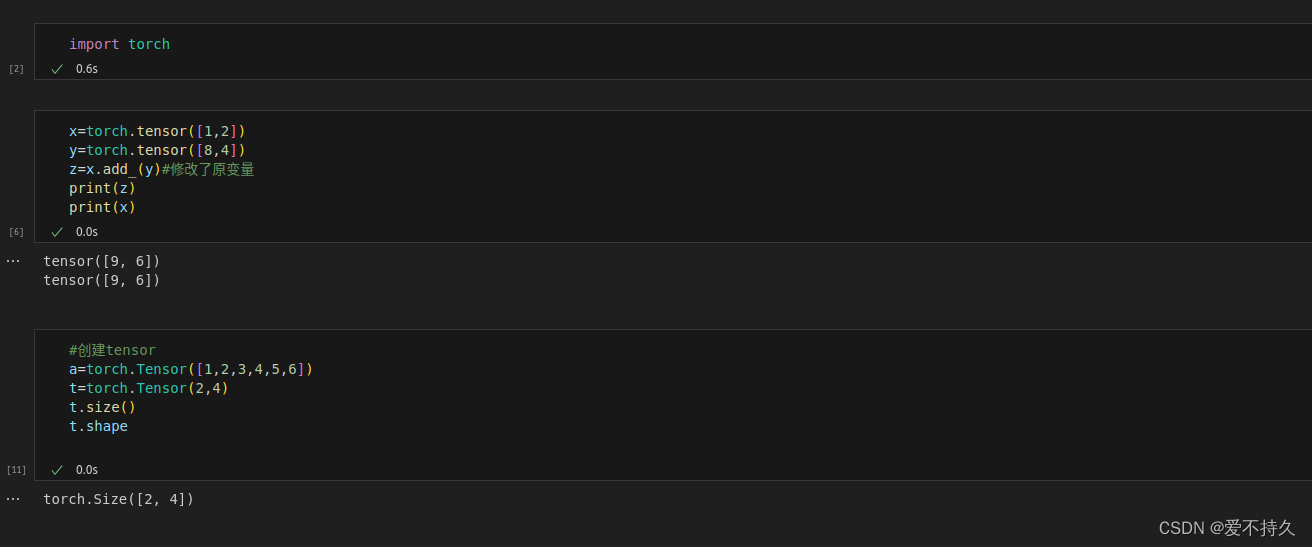
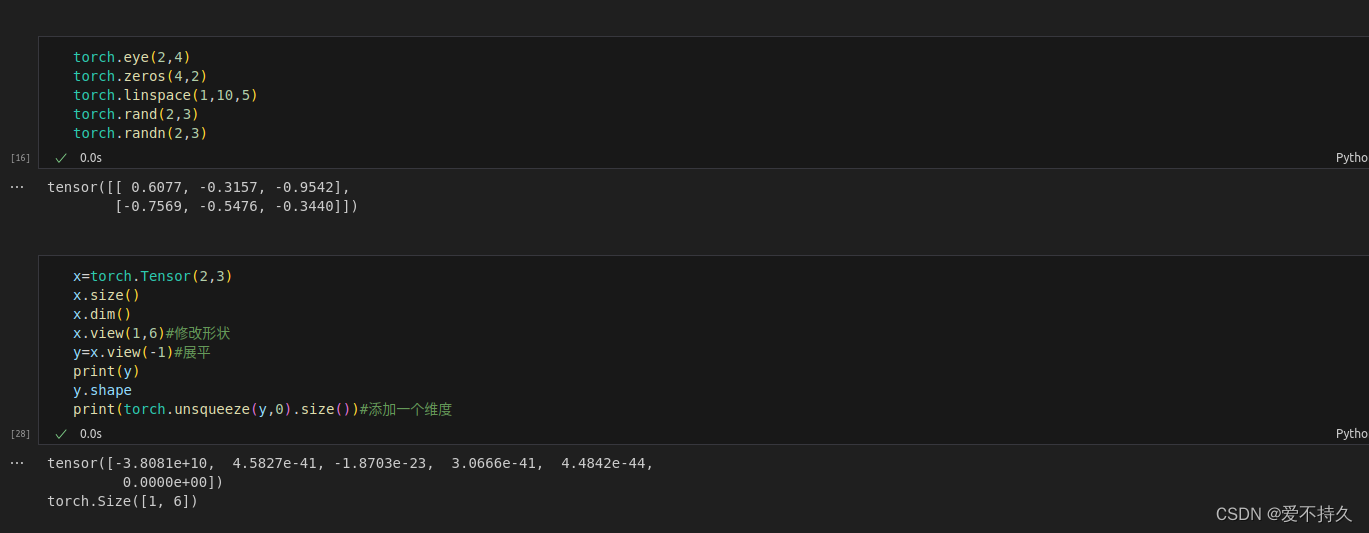
5.修改tensor的形状

torch.view=torch.reshape
如果你只想重塑张量,请使用torch.reshape。如果你还关注内存使用情况并希望确保两个张量共享相同的数据,请使用torch.view。
注意:没有resize()这个函数
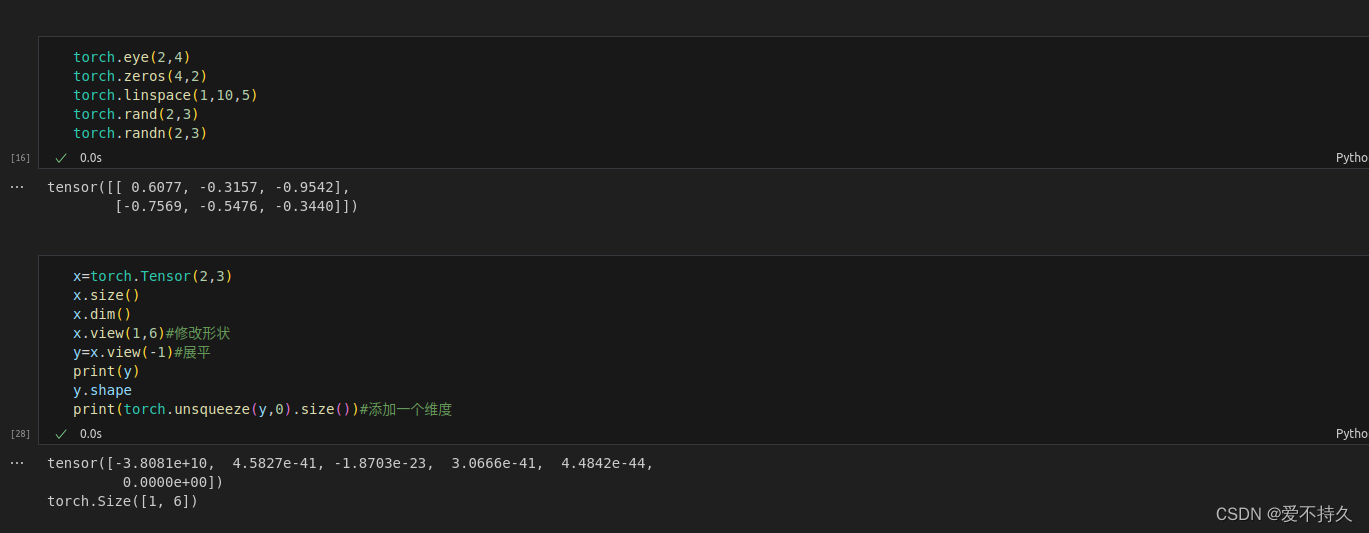
6.索引操作

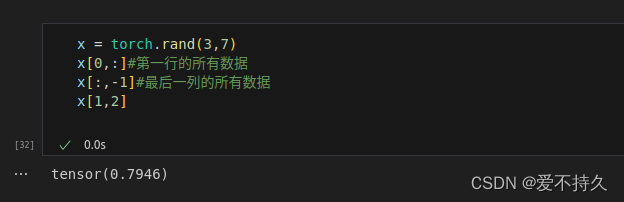
7.逐元素操作
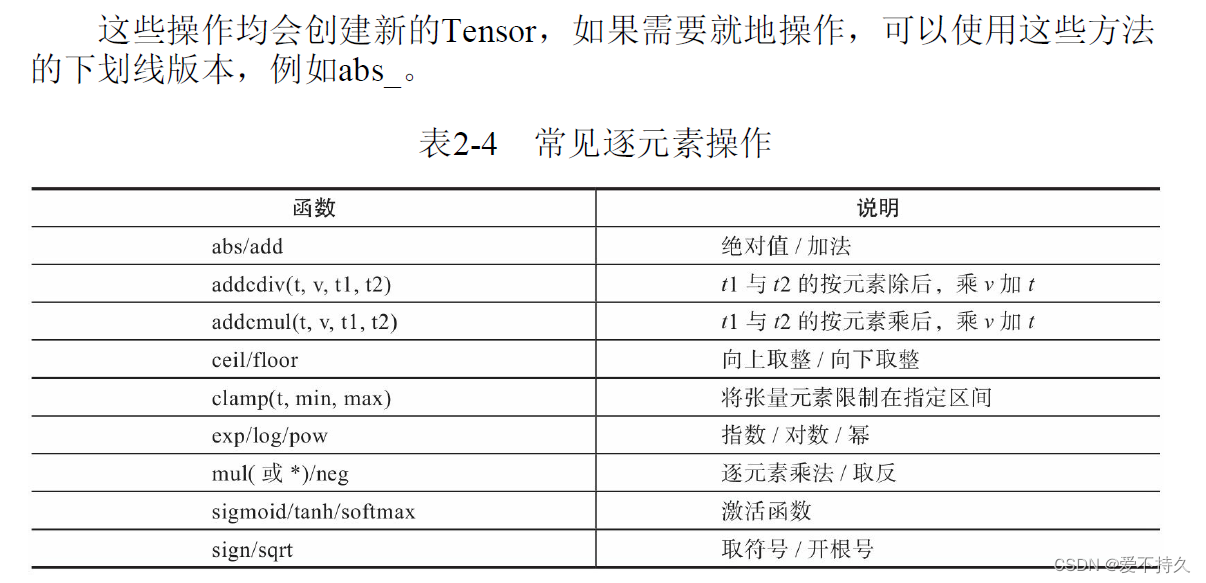
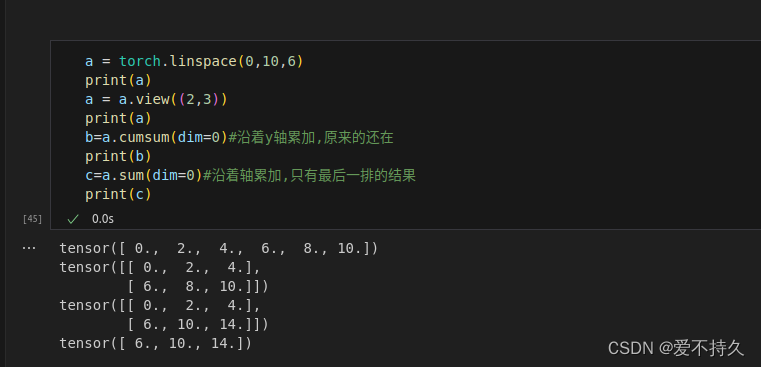
8.归并操作
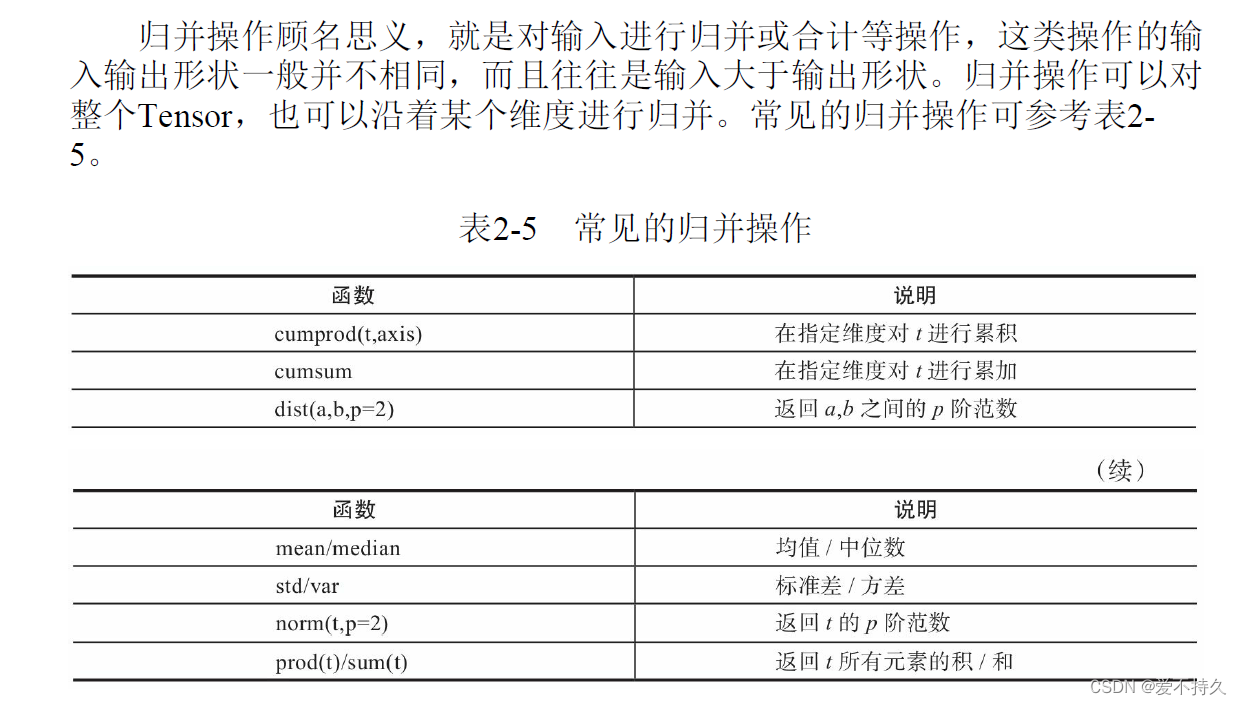
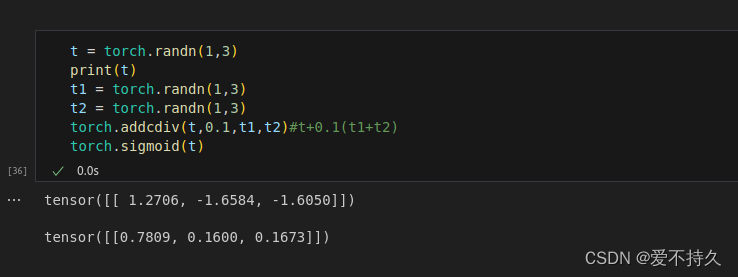
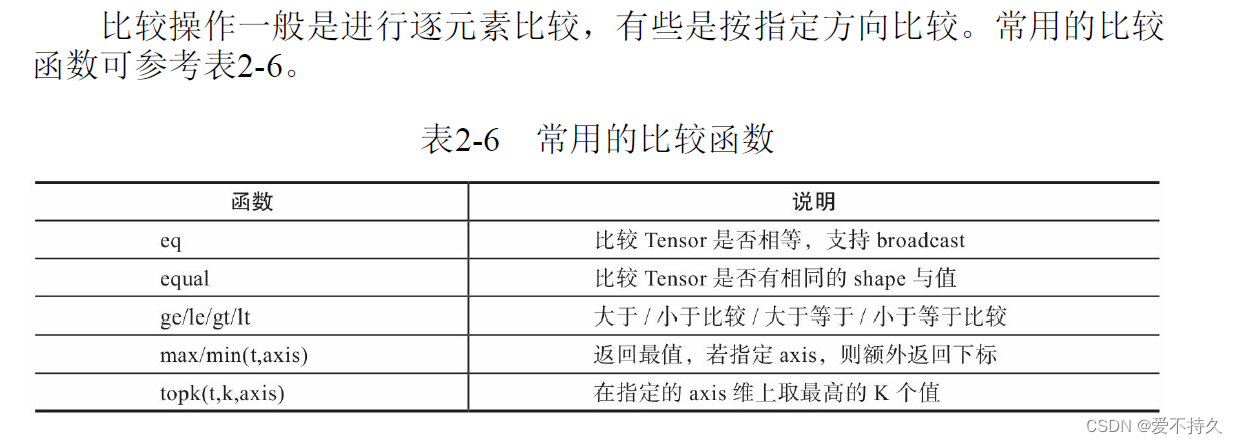
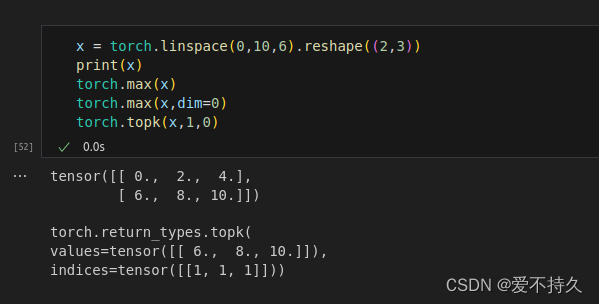
9.比较操作
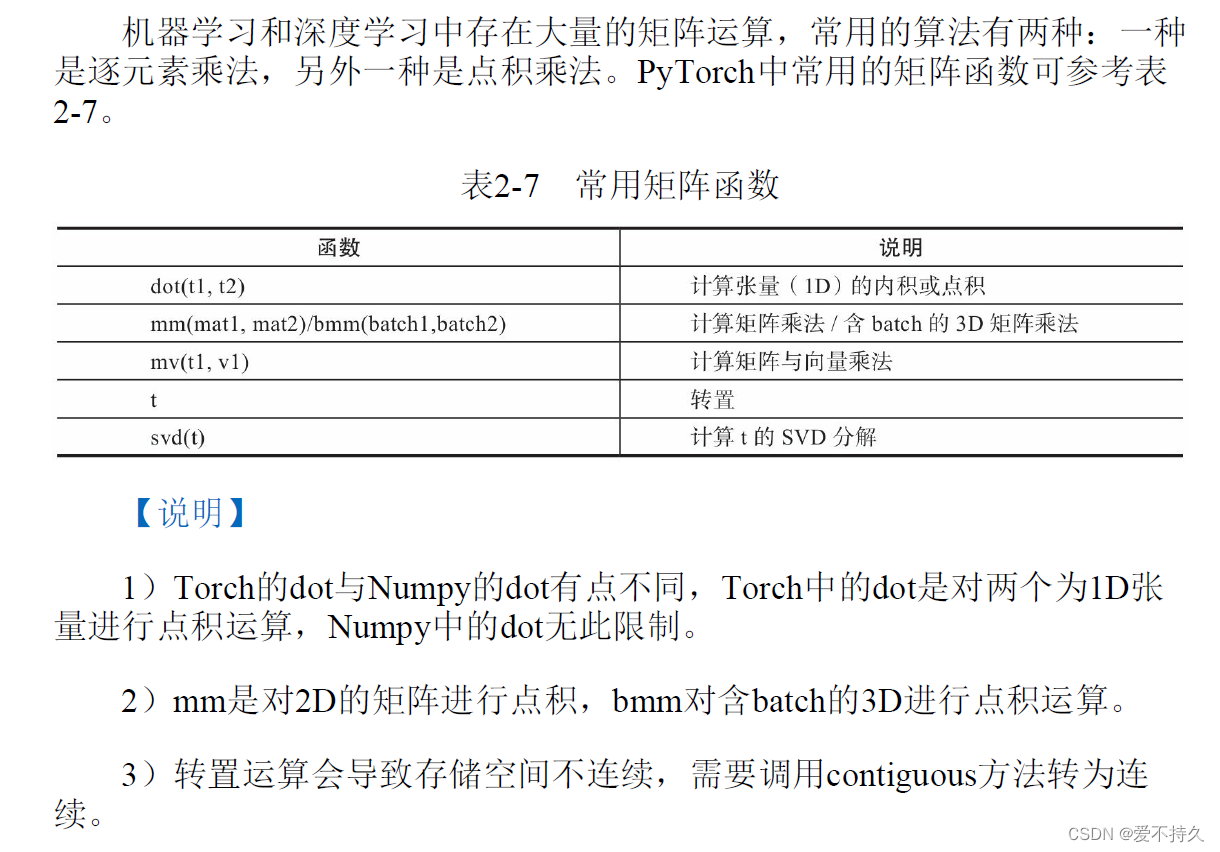
10矩阵操作
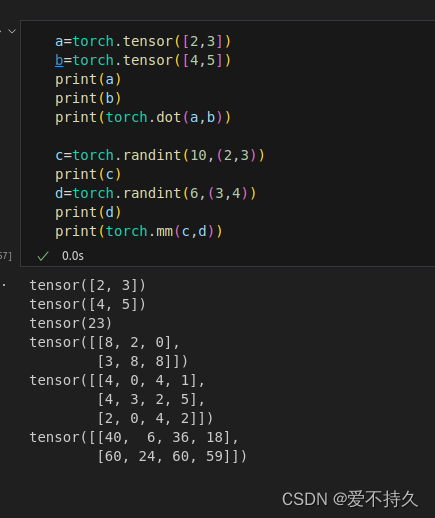
11.numpy和pytorch区别
12.求梯度
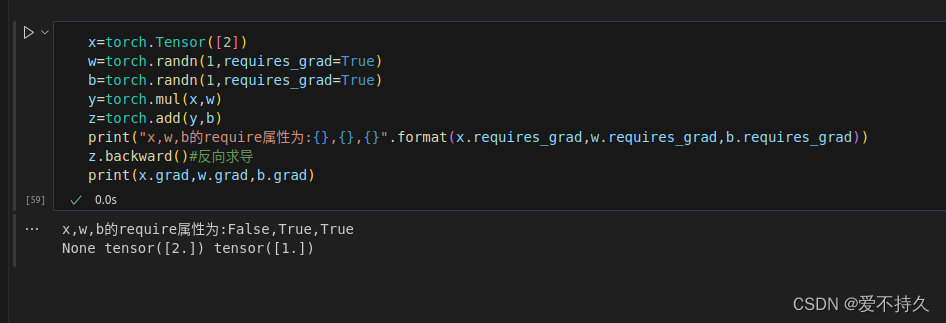
12.1标量求梯度
调用backward()并且不需要传入参数,loss通常是标量值
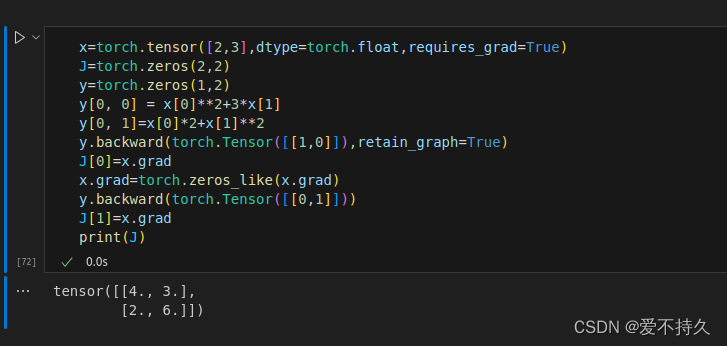
12.2非标量求梯度
要分别求,backward里要带着参数(1,0)就是第一个,除此之外因为是梯度的累加,求完一部分就要清0
13实现简单的机器学习
import torch as t
%matplotlib inline
from matplotlib import pyplot as plt
dtype=t.float
t.manual_seed(100)
lr=0.001
x=t.unsqueeze(t.linspace(-1,1,100),dim=1)
y=3*x.pow(2)+2+0.2*t.rand(x.size())
#plt.scatter(x.numpy(),y.numpy())
#plt.show()
w=t.randn(1,1,dtype=dtype,requires_grad=True)
b=t.zeros(1,1,dtype=dtype,requires_grad=True)
for ii in range(800):
y_pred=x.pow(2).mm(w)+b
loss=0.5*(y_pred-y)**2
loss=loss.sum()
loss.backward()
#手动更新参数
with t.no_grad():
w-=lr*w.grad
b-=lr*w.grad
w.grad.zero_()
b.grad.zero_()
plt.plot(x.numpy(),y_pred.detach().numpy(),'r-',label='predict')#画线(绘制经过点的曲线)
plt.scatter(x.numpy(),y.numpy(),color='blue',marker='o',label='true')#绘制散点图(绘制那些点)
plt.xlim(-1,1)#指定坐标轴的值的范围
plt.ylim(2,6)
plt.legend()#结合label创建图例
plt.show()
print(w,b)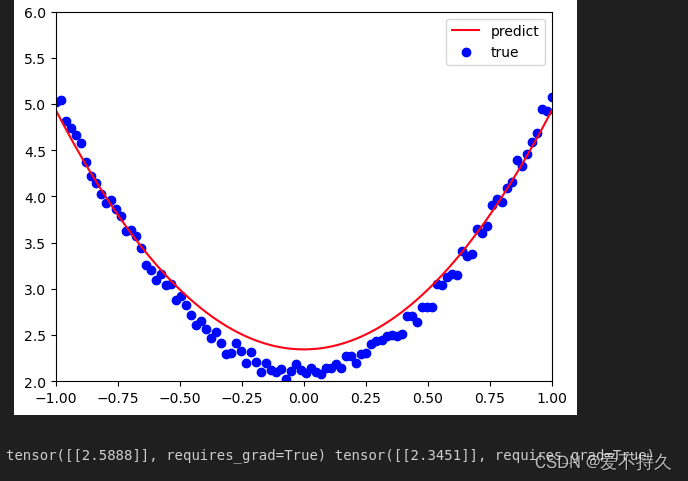
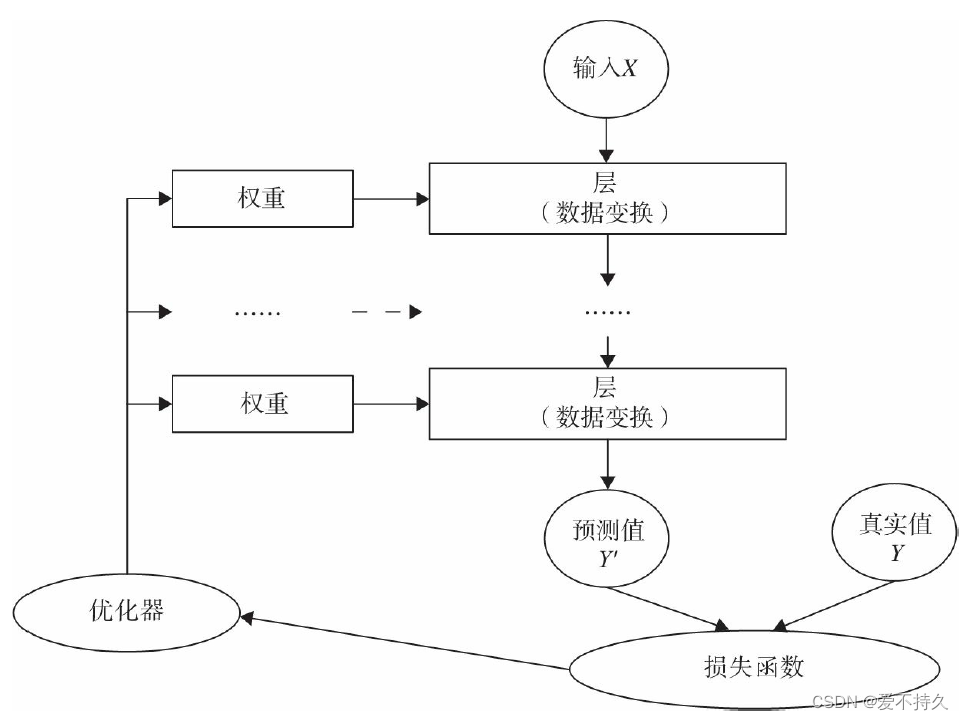
14.神经网络的核心组件
通常使用pytorch的nn工具箱,会有现成的包或类
层:将输入张量转换为输出张量;
模型:层构成的网络;
损失函数:参数学习的目标函数,也是优化的目标,通常让损失函数最小;
优化器:如何使损失函数最小;
15.实例
15.1构建网络层:构建网络层通常有两种,一种是nn.module,另一种是nn.functional,

具有学习参数的(例如,conv2d,linear,batch_norm)采用nn.Xxx方式。没有学习参数的(例如,maxpool、loss func、activation func)等根据个人选择使用nn.functional.xxx或者nn.Xxx方式

import numpy as np
import torch
from torchvision.datasets import mnist#导入数据集
import torchvision.transforms as transforms#数据预处理的包,一般来说是要用的
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
from torch import nn
import matplotlib.pyplot as plt
%matplotlib inline
#定义超参数
train_batch_size = 64
test_batch_size = 128
learning_rate = 0.01
num_epoches = 20
lr = 0.01
momentum = 0.5
#下载数据并进行预处理
#预处理函数要统一放到compose中,目前有将数据转换为tensor的处理以及数据归一化(三个通道则是【m1,m2,m3】,【n1,n2,n3】)
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5],[0.5])])
#下载数据,并且进行预处理
train_dataset = mnist.MNIST('./data',train=True,transform=transform,download=True)
test_dataset = mnist.MNIST('./data',train=False,transform=transform)
#dataloader 要将数据放到dataloader迭代器中,如果是自己的数据也要按照格式放到dataloader中
train_loader = DataLoader(train_dataset,batch_size=train_batch_size,shuffle=True)
test_loader = DataLoader(test_dataset,batch_size=test_batch_size,shuffle=True)
#显示数据
examples = enumerate(test_loader)#标签和数据进行对应
batch_idx,(example_data,example_target) = next(examples)#取出可以迭代的对象
# fig = plt.figure()
# for i in range(6):
# plt.subplot(2,3,i+1)
# plt.tight_layout()
# plt.imshow(example_data[i][0],cmap='gray',interpolation='none')
# plt.title("GroundTruth:{}".format(example_target[i]))
# plt.xticks([])
# plt.yticks([])
#构建网络,使用nn.sequential
class Net(nn.Module):
def __init__(self, in_dim,n_hidden1,n_hidden2,out_dim):#网络的参数
super(Net, self).__init__()
self.layer1 = nn.Sequential(nn.Linear(in_dim,n_hidden1),nn.BatchNorm1d(n_hidden1))
#self.layer1 = nn.Sequential(nn.Linear(in_dim,n_hidden1))
self.layer2 = nn.Sequential(nn.Linear(n_hidden1,n_hidden2),nn.BatchNorm1d(n_hidden2))
#self.layer2 = nn.Sequential(nn.Linear(n_hidden1,n_hidden2))
self.layer3 =nn.Sequential(nn.Linear(n_hidden2,out_dim))
#定义前向传播过程
def forward(self,x):
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
x = self.layer3(x)
return x
#实例化一个网络,使用gpu,没有的话就使用cpu
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = Net(28*28,300,100,10)
model.to(device)
#定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=lr,momentum=momentum)
losses=[]#损失值要依次存进来
acces=[]
eval_losses=[]
eval_acces=[]
for epoch in range(num_epoches):
train_loss = 0
train_acc = 0
model.train()
if epoch%5==0:
optimizer.param_groups[0]['lr']*=0.1
for img,label in train_loader:
img = img.to(device)#都放到gpu上计算
label = label.to(device)
img = img.view(img.size(0),-1)#展平
#print(type(img))
out=model(img)
#print(type(out))
loss=criterion(out,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss+=loss.item()#取出loss值
_,pred = out.max(1)
num_correct = (pred==label).sum().item()
acc=num_correct/img.shape[0]
train_acc+=acc
losses.append(train_loss/len(train_loader))
acces.append(train_acc/len(train_loader))
eval_loss=0
eval_acc=0
model.eval()
for img,label in test_loader:
img=img.to(device)
label = label.to(device)
img = img.view(img.size(0),-1)
out=model(img)
loss=criterion(out,label)
eval_loss+=loss.item()
_,pred=out.max(1)
num_correct = (pred==label).sum().item()
acc=num_correct/img.shape[0]
eval_acc+=acc
eval_losses.append(eval_loss/len(test_loader))
eval_acces.append(eval_acc/len(test_loader))
print('epoch:{},train_loss:{:.4f},trian_acc:{:.4f},test_loss:{:.4f},test_acc:{:.4f}'.format(epoch,train_loss/len(train_loader),train_acc/len(train_loader),eval_loss/len(test_loader),eval_acc/len(test_loader)))
plt.title('trainloss')
plt.plot(np.arange(len(losses)),losses)
plt.legend(['train loss'],loc='upper right')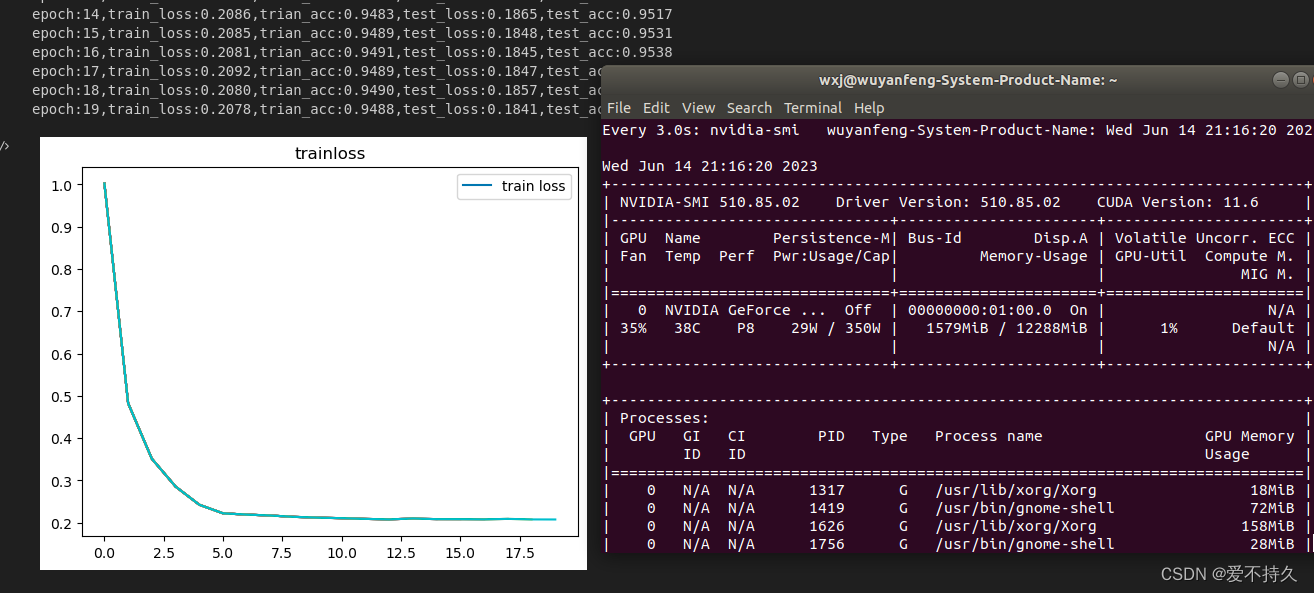
小结:
1.定义网络:有多种方式
2.前向传播:forward,把输入层和网络层和输出层链接起来。
3.反向传播:使用nn工具之后,直接loss.backward()就可以,然后选一个优化器optimizer
4.训练模型:model.train(),测试的话就是model.eval(),在这两个函数之后要调用loss.backward()和optimizer.step()执行

(注:可以使用不同的优化器)
( )
)



















 613
613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









