









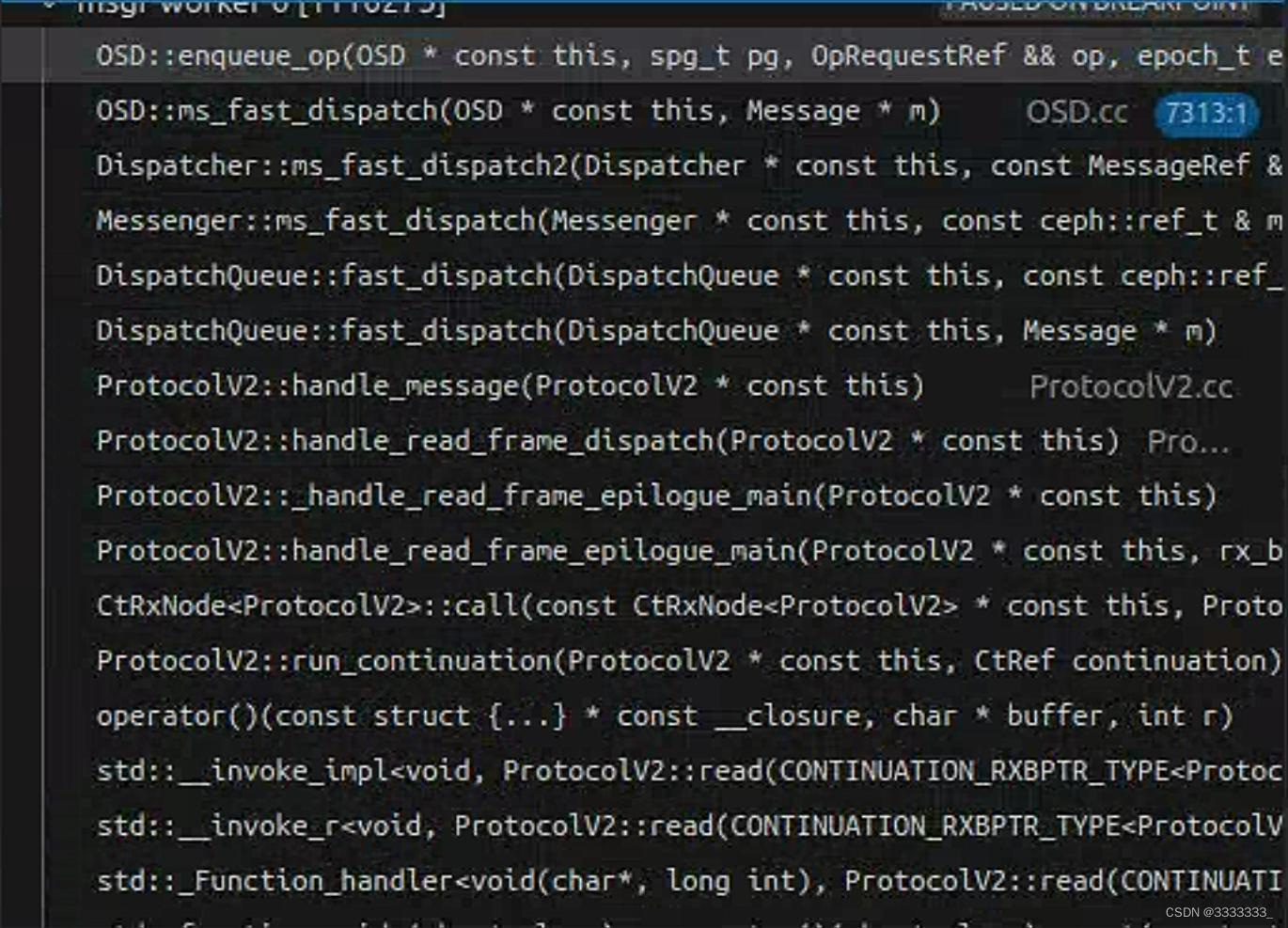

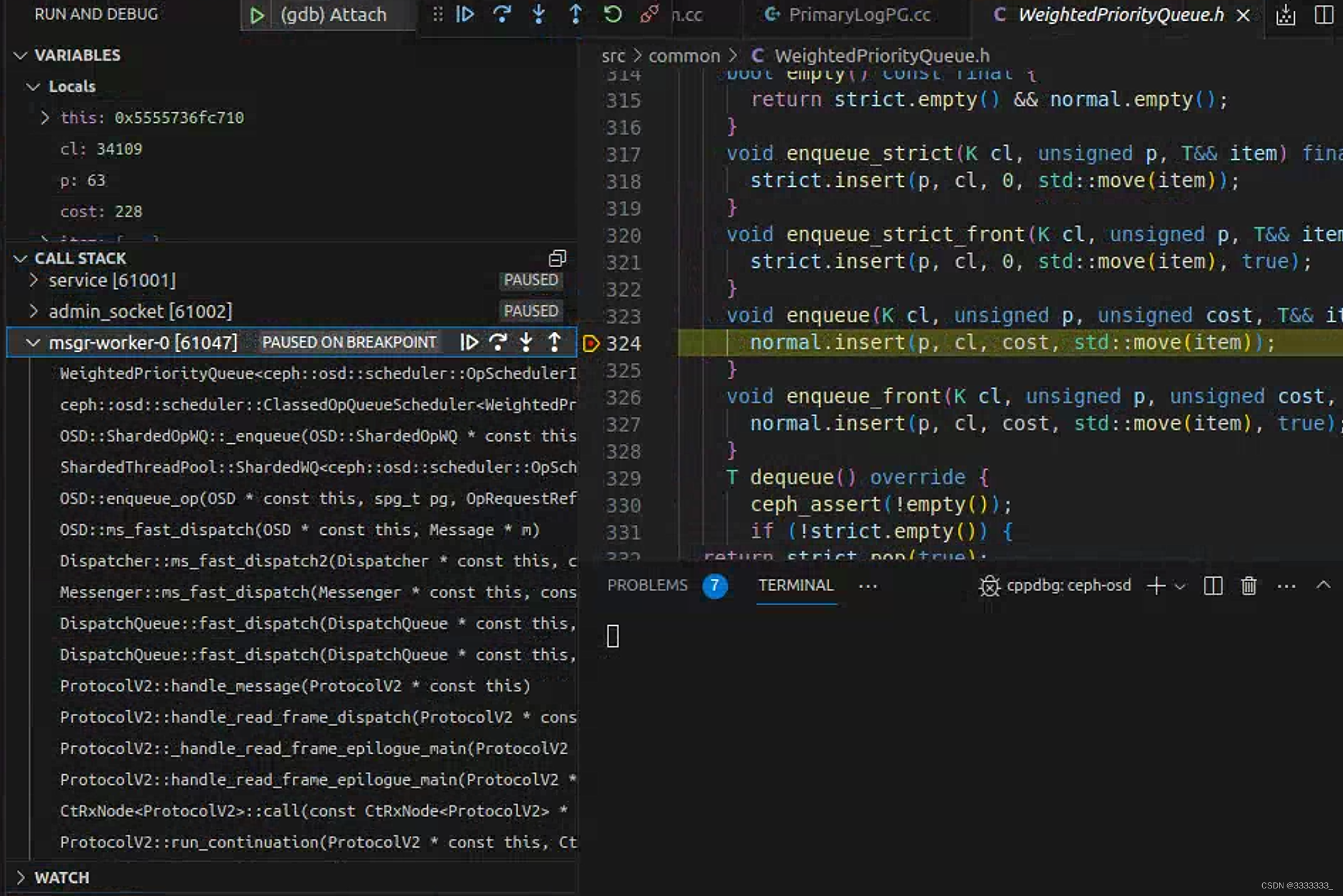
两个线程的调用栈
Breakpoint reached: WeightedPriorityQueue.h:324
Stack:
WeightedPriorityQueue::enqueue(unsigned long, unsigned int, unsigned int, ceph::osd::scheduler::OpSchedulerItem &&) WeightedPriorityQueue.h:324
ceph::osd::scheduler::ClassedOpQueueScheduler::enqueue(ceph::osd::scheduler::OpSchedulerItem &&) OpScheduler.h:105
OSD::ShardedOpWQ::_enqueue(ceph::osd::scheduler::OpSchedulerItem &&) OSD.cc:11306
ShardedThreadPool::ShardedWQ::queue(ceph::osd::scheduler::OpSchedulerItem &&) WorkQueue.h:616
OSD::enqueue_op(spg_t, boost::intrusive_ptr<…> &&, unsigned int) OSD.cc:9951
OSD::ms_fast_dispatch(Message *) OSD.cc:7313
Dispatcher::ms_fast_dispatch2(const boost::intrusive_ptr<…> &) Dispatcher.h:84
Messenger::ms_fast_dispatch(const boost::intrusive_ptr<…> &) Messenger.h:685
DispatchQueue::fast_dispatch(const boost::intrusive_ptr<…> &) DispatchQueue.cc:74
DispatchQueue::fast_dispatch(Message *) DispatchQueue.h:203
ProtocolV2::handle_message() ProtocolV2.cc:1478
ProtocolV2::handle_read_frame_dispatch() ProtocolV2.cc:1141
ProtocolV2::_handle_read_frame_epilogue_main() ProtocolV2.cc:1329
ProtocolV2::handle_read_frame_epilogue_main(std::unique_ptr<…> &&, int) ProtocolV2.cc:1304
CtRxNode::call(ProtocolV2 *) const Protocol.h:67
ProtocolV2::run_continuation(Ct<…> &) ProtocolV2.cc:47
operator() ProtocolV2.cc:755
std::__invoke_impl<…>(std::__invoke_other, (unnamed struct) &) invoke.h:61
std::__invoke_r<…>((unnamed struct) &) invoke.h:111
std::_Function_handler::_M_invoke(const std::_Any_data &, char *&&, long &&) std_function.h:291
std::function::operator()(char *, long) const std_function.h:560
AsyncConnection::process() AsyncConnection.cc:454
C_handle_read::do_request(unsigned long) AsyncConnection.cc:71
EventCenter::process_events(unsigned int, std::chrono::duration<…> *) Event.cc:422
operator() Stack.cc:53
std::__invoke_impl<…>(std::__invoke_other, (unnamed struct) &) invoke.h:61
std::__invoke_r<…>((unnamed struct) &) invoke.h:111
std::_Function_handler::_M_invoke(const std::_Any_data &) std_function.h:291
std::function::operator()() const std_function.h:560
std::__invoke_impl<…>(std::__invoke_other, std::function<…> &&) invoke.h:61
std::__invoke<…>(std::function<…> &&) invoke.h:96
std::thread::_Invoker::_M_invoke<…>(std::_Index_tuple<…>) std_thread.h:253
std::thread::_Invoker::operator()() std_thread.h:260
std::thread::_State_impl::_M_run() std_thread.h:211
<unknown> 0x00007fa7690e96b4
start_thread 0x00007fa76929e609
__clone 0x00007fa768dd0133
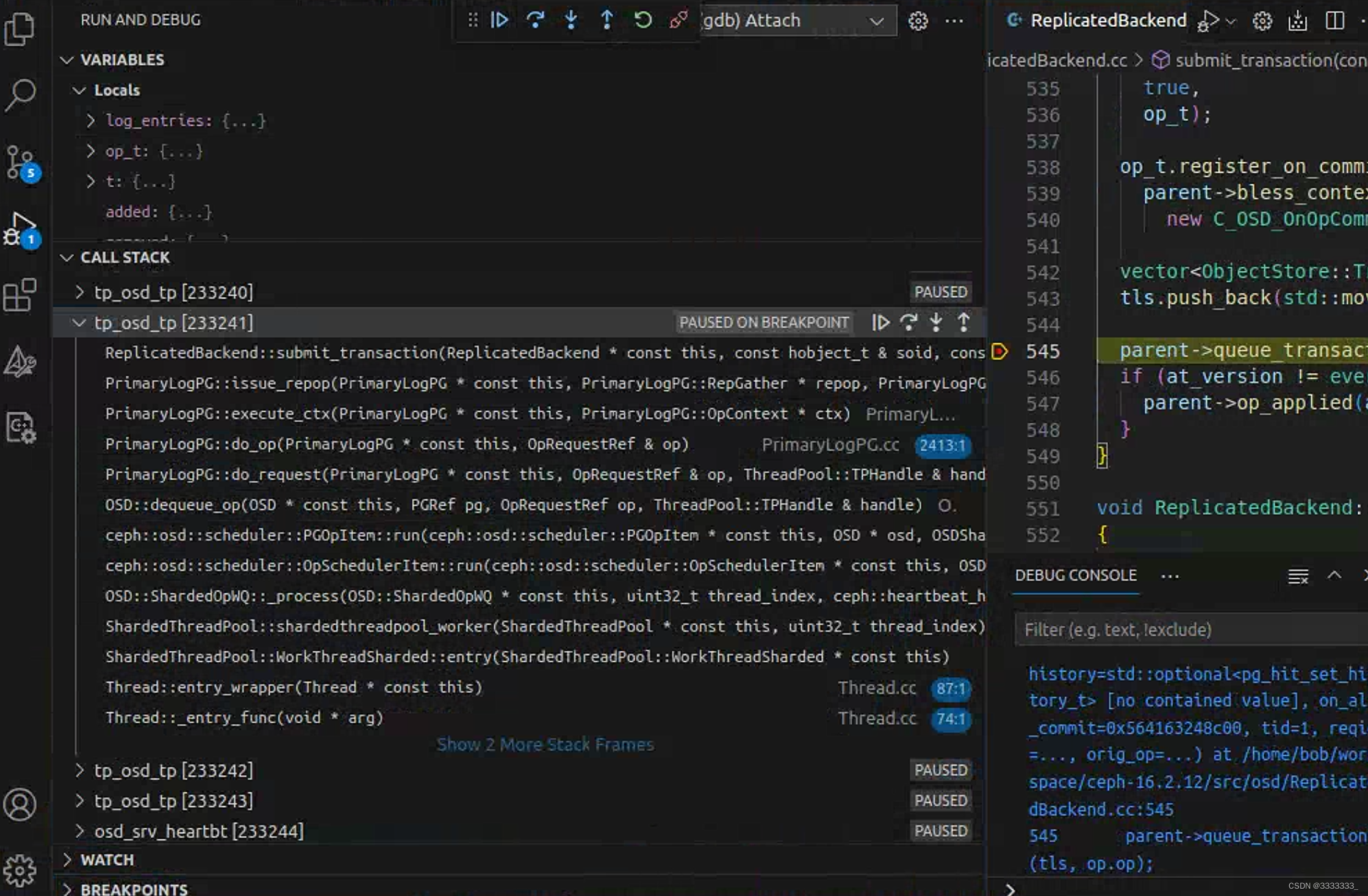
Breakpoint reached: BlueStore.cc:13068
Stack:
BlueStore::queue_transactions(boost::intrusive_ptr<…> &, std::vector<…> &, boost::intrusive_ptr<…>, ThreadPool::TPHandle *) BlueStore.cc:13068
PrimaryLogPG::queue_transactions(std::vector<…> &, boost::intrusive_ptr<…>) PrimaryLogPG.h:349
ReplicatedBackend::submit_transaction(const hobject_t &, const object_stat_sum_t &, const eversion_t &, std::unique_ptr<…> &&, const eversion_t &, const eversion_t &, std::vector<…> &&, std::optional<…> &, Context *, unsigned long, osd_reqid_t, boost::intrusive_ptr<…>) ReplicatedBackend.cc:545
PrimaryLogPG::issue_repop(PrimaryLogPG::RepGather *, PrimaryLogPG::OpContext *) PrimaryLogPG.cc:11089
PrimaryLogPG::execute_ctx(PrimaryLogPG::OpContext *) PrimaryLogPG.cc:4209
PrimaryLogPG::do_op(boost::intrusive_ptr<…> &) PrimaryLogPG.cc:2413
PrimaryLogPG::do_request(boost::intrusive_ptr<…> &, ThreadPool::TPHandle &) PrimaryLogPG.cc:1831
OSD::dequeue_op(boost::intrusive_ptr<…>, boost::intrusive_ptr<…>, ThreadPool::TPHandle &) OSD.cc:10005
ceph::osd::scheduler::PGOpItem::run(OSD *, OSDShard *, boost::intrusive_ptr<…> &, ThreadPool::TPHandle &) OpSchedulerItem.cc:32
ceph::osd::scheduler::OpSchedulerItem::run(OSD *, OSDShard *, boost::intrusive_ptr<…> &, ThreadPool::TPHandle &) OpSchedulerItem.h:148
OSD::ShardedOpWQ::_process(unsigned int, ceph::heartbeat_handle_d *) OSD.cc:11277
ShardedThreadPool::shardedthreadpool_worker(unsigned int) WorkQueue.cc:313
ShardedThreadPool::WorkThreadSharded::entry() WorkQueue.h:637
Thread::entry_wrapper() Thread.cc:87
Thread::_entry_func(void *) Thread.cc:74
start_thread 0x00007fa76929e609
__clone 0x00007fa768dd0133接下来根据调用栈逐个学习下代码(本篇就简单的根据调用栈分析)
1、操作入队
operator() Stack.cc:53
std::function<void ()> NetworkStack::add_thread(unsigned worker_id)
{
Worker *w = workers[worker_id];
return [this, w]() {
char tp_name[16];
sprintf(tp_name, "msgr-worker-%u", w->id);
ceph_pthread_setname(pthread_self(), tp_name);
const unsigned EventMaxWaitUs = 30000000;
w->center.set_owner();
ldout(cct, 10) << __func__ << " starting" << dendl;
w->initialize();
w->init_done();
while (!w->done) {
ldout(cct, 30) << __func__ << " calling event process" << dendl;
ceph::timespan dur;
int r = w->center.process_events(EventMaxWaitUs, &dur);
if (r < 0) {
ldout(cct, 20) << __func__ << " process events failed: "
<< cpp_strerror(errno) << dendl;
// TODO do something?
}
w->perf_logger->tinc(l_msgr_running_total_time, dur);
}
w->reset();
w->destroy();
};
}在指定的worker上添加一个线程,并返回一个函数对象,该对象可以在新线程中执行
获取指定worker的指针,创建一个lambda表达式作为返回值,lambda表达式中会设置线程名称、初始化Worker对象并在循环中处理事件,直到Worker对象被标记为完成(done为真)
EventCenter::process_events(unsigned int, std::chrono::duration *) Event.cc:422
int EventCenter::process_events(unsigned timeout_microseconds, ceph::timespan *working_dur)
{
。。。。。。
//首先获取time_events数组的第一个元素,并判断是否需要触发该事件
auto it = time_events.begin();
if (it != time_events.end() && end_time >= it->first) {
trigger_time = true;
end_time = it->first;
if (end_time > now) {
timeout_microseconds = std::chrono::duration_cast<std::chrono::microseconds>(end_time - now).count();
} else {
timeout_microseconds = 0;
}
}
//判断是否需要阻塞等待事件的触发。
bool blocking = pollers.empty() && !external_num_events.load();
if (!blocking)
timeout_microseconds = 0;
tv.tv_sec = timeout_microseconds / 1000000;
tv.tv_usec = timeout_microseconds % 1000000;
std::vector<FiredFileEvent> fired_events;
//调用driver->event_wait等待事件的触发
numevents = driver->event_wait(fired_events, &tv);
auto working_start = ceph::mono_clock::now();
//遍历fired_events数组,处理事件的读写操作。如果事件是可读事件,则调用相应的回调函数,
//进行读取操作;如果事件是可写事件,则调用相应的回调函数,进行写入操作。
for (int event_id = 0; event_id < numevents; event_id++) {
..........
if (event->mask & fired_events[event_id].mask & EVENT_READABLE) {
......
cb->do_request(fired_events[event_id].fd);
}
if (event->mask & fired_events[event_id].mask & EVENT_WRITABLE) {
if (!rfired || event->read_cb != event->write_cb) {
cb = event->write_cb;
cb->do_request(fired_events[event_id].fd);
}
}
}
//如果存在定时事件需要触发,函数调用process_time_events函数,触发定时事件的回调函数
if (trigger_time)
numevents += process_time_events();
//如果存在外部事件需要处理,函数则通过external_events数组获取事件,并依次调用相应的回调函数处理事件
if (external_num_events.load()) {
.....................
while (!cur_process.empty()) {
EventCallbackRef e = cur_process.front();
ldout(cct, 30) << __func__ << " do " << e << dendl;
e->do_request(0);
cur_process.pop_front();
}
}
//如果没有事件触发,且不需要阻塞等待事件,函数遍历pollers数组,调用poll函数获取事件。
if (!numevents && !blocking) {
for (uint32_t i = 0; i < pollers.size(); i++)
numevents += pollers[i]->poll();
}
。。。。。。。。。。。。。
//返回处理的事件个数
return numevents;
}EventCenter事件中心的事件处理函数process_events,用于等待并处理事件。事件中心是Ceph异步网络通信机制的核心之一,它封装了底层的事件驱动机制,提供了事件的注册、删除、等待等接口,用于实现网络通信的异步处理。
C_handle_read::do_request(unsigned long) AsyncConnection.cc:71
class C_handle_read : public EventCallback {
AsyncConnectionRef conn;
public:
explicit C_handle_read(AsyncConnectionRef c): conn(c) {}
void do_request(uint64_t fd_or_id) override {
conn->process();
}
};AsyncConnection::process() AsyncConnection.cc:454
void AsyncConnection::process() {
....................
//根据当前连接的状态state,分别处理不同的事件
switch (state) {
case STATE_NONE: {
........
}
case STATE_CLOSED: {
........
}
//连接正在建立中,需要进行连接操作。
//该状态中会创建一个定时事件用于超时检测
case STATE_CONNECTING: {
...........
}
//表示连接正在尝试重新建立中,需要进行连接操作。
该状态中会创建一个定时事件用于超时检测,如果连接建立成功,则进入STATE_CONNECTION_ESTABLISHED状态。
case STATE_CONNECTING_RE: {
ssize_t r = cs.is_connected();
..................
}
//表示连接正在等待接收连接,需要注册读事件等待连接请求。
case STATE_ACCEPTING: {
center->create_file_event(cs.fd(), EVENT_READABLE, read_handler);
state = STATE_CONNECTION_ESTABLISHED;
break;
}
//连接已经建立,需要进行读写操作。
case STATE_CONNECTION_ESTABLISHED: {
if (pendingReadLen) {
ssize_t r = read(*pendingReadLen, read_buffer, readCallback);
if (r <= 0) { // read all bytes, or an error occured
pendingReadLen.reset();
char *buf_tmp = read_buffer;
read_buffer = nullptr;
readCallback(buf_tmp, r);
}
return;
}
break;
}
}
//处理完连接状态后,处理连接的读事件
protocol->read_event();
}主要是处理异步连接的状态转换和事件处理
operator() ProtocolV2.cc:755
CtPtr ProtocolV2::read(CONTINUATION_RXBPTR_TYPE<ProtocolV2> &next,
rx_buffer_t &&buffer) {
const auto len = buffer->length();
const auto buf = buffer->c_str();
//将buffer保存到next.node中,以便在读取完成后进行回调处理。
next.node = std::move(buffer);
//读取网络数据,如果读取成功,则返回nullptr,否则返回&next,表示读取操作仍在进行中。
ssize_t r = connection->read(len, buf,
[&next, this](char *buffer, int r) {
//unlikely是一个宏,用于提示编译器某个条件的概率较小,以便在编译时优化代码的执行路径
//判断是否启用了预认证(pre_auth)机制,并且读取的数据不为空。由于这种情况比较少见,因此使用
unlikely宏可以告诉编译器这种情况的概率较小,从而优化代码的执行路径,提高程序的性能
if (unlikely(pre_auth.enabled) && r >= 0) {
pre_auth.rxbuf.append(*next.node);
ceph_assert(!cct->_conf->ms_die_on_bug ||
pre_auth.rxbuf.length() < 20000000);
}
next.r = r;
//读取完成后,函数调用run_continuation(next)回调处理函数,处理读取到的数据
run_continuation(next);
});
if (r <= 0) {
// error or done synchronously
if (unlikely(pre_auth.enabled) && r == 0) {
pre_auth.rxbuf.append(*next.node);
ceph_assert(!cct->_conf->ms_die_on_bug ||
pre_auth.rxbuf.length() < 20000000);
}
next.r = r;
return &next;
}
return nullptr;
}用于读取网络数据并处理。ProtocolV2是Ceph异步网络通信机制中的一个重要类,它封装了底层的网络通信协议,提供了异步的发送和接收接口,并处理网络连接的建立和断开等事件。
ProtocolV2::run_continuation(Ct &) ProtocolV2.cc:47
//continuation参数,表示需要执行的异步回调函数
void ProtocolV2::run_continuation(CtRef continuation) {
//使用try-catch语句块捕获异步回调函数执行过程中可能抛出的异常。
如果捕获到异常,则调用_fault()函数进行错误处理
try {
CONTINUATION_RUN(continuation)
} catch (const ceph::buffer::error &e) {
_fault();
} catch (const ceph::crypto::onwire::MsgAuthError &e) {
_fault();
} catch (const DecryptionError &) {
lderr(cct) << __func__ << " failed to decrypt frame payload" << dendl;
}
}用于运行异步回调函数并捕获异常
#define CONTINUATION_RUN(CT) \
{ \
Ct<std::remove_reference<decltype(*this)>::type> *_cont = &CT;\
do { \
_cont = _cont->call(this); \
} while (_cont); \
}
这是一个宏定义,用于运行异步回调函数。在宏定义中,CT表示异步回调函数的引用。
宏展开后的代码将定义一个指向异步回调函数的指针_cont,并通过一个do-while循环来反复执行异步回调函数,直到该函数返回nullptr为止。在每次循环中,调用call函数执行异步回调函数,并将ProtocolV2类的实例作为参数传递给异步回调函数,以便在回调函数中访问ProtocolV2实例的成员变量和方法。
在异步回调函数执行过程中,可能会返回一个新的异步回调函数,即继续执行异步回调函数链。因此,do-while循环会一直执行直到链条结束。
该宏的作用是简化运行异步回调函数的代码,提高程序的可读性和可维护性。
CtRxNode::call(ProtocolV2 *) const Protocol.h:67
inline Ct<C> *call(C *foo) const override { //使用std::move将node对象的所有权转移给异步回调函数,以避免不必要的内存拷贝和资源浪费。 return (foo->*_f)(std::move(node), r); }
ProtocolV2::handle_read_frame_epilogue_main(std::unique_ptr &&, int) ProtocolV2.cc:1304
ProtocolV2::_handle_read_frame_epilogue_main() ProtocolV2.cc:1329
上面两个,处理读取到的网络数据帧的结束部分
ProtocolV2::handle_read_frame_dispatch() ProtocolV2.cc:1141
CtPtr ProtocolV2::handle_read_frame_dispatch() {
ldout(cct, 10) << __func__
<< " tag=" << static_cast<uint32_t>(next_tag) << dendl;
switch (next_tag) {
case Tag::HELLO:
case Tag::AUTH_REQUEST:
case Tag::AUTH_BAD_METHOD:
........................
case Tag::KEEPALIVE2_ACK:
case Tag::ACK:
case Tag::WAIT:
// 处理网络数据帧的payload(负载))部分
return handle_frame_payload();
case Tag::MESSAGE:
//
return handle_message();
default: {
lderr(cct) << __func__
<< " received unknown tag=" << static_cast<uint32_t>(next_tag)
<< dendl;
return _fault();
}
}
return nullptr;
}根据接收到的网络数据帧的标签(tag)来选择相应的处理函数
ProtocolV2::handle_message() ProtocolV2.cc:1478
CtPtr ProtocolV2::handle_message() {
//解码接收到的消息帧
auto msg_frame = MessageFrame::Decode(rx_segments_data);
// XXX: paranoid copy just to avoid oops
ceph_msg_header2 current_header = msg_frame.header();
//将解码后的消息帧的头部信息封装到 ceph_msg_header2 类型变量 current_header 中,
//并将其转化为 ceph_msg_header 类型变量 header。
INTERCEPT(16);
ceph_msg_header header{current_header.seq,
current_header.tid,
current_header.type,
current_header.priority,
current_header.version,
init_le32(msg_frame.front_len()),
init_le32(msg_frame.middle_len()),
init_le32(msg_frame.data_len()),
current_header.data_off,
peer_name,
current_header.compat_version,
current_header.reserved,
init_le32(0)};
ceph_msg_footer footer{init_le32(0), init_le32(0),
init_le32(0), init_le64(0), current_header.flags};
//解码消息内容,并将消息内容封装到一个Message对象中。
Message *message = decode_message(cct, 0, header, footer,
msg_frame.front(),
msg_frame.middle(),
msg_frame.data(),
connection);
if (!message) {
ldout(cct, 1) << __func__ << " decode message failed " << dendl;
return _fault();
} else {
state = READ_MESSAGE_COMPLETE;
}
INTERCEPT(17);
//对接收到的消息进行一系列处理,包括校验消息序列号、设置字节流和消息流速率控制等。
message->set_byte_throttler(connection->policy.throttler_bytes);
message->set_message_throttler(connection->policy.throttler_messages);
// store reservation size in message, so we don't get confused
// by messages entering the dispatch queue through other paths.
message->set_dispatch_throttle_size(cur_msg_size);
message->set_recv_stamp(recv_stamp);
message->set_throttle_stamp(throttle_stamp);
message->set_recv_complete_stamp(ceph_clock_now());
// check received seq#. if it is old, drop the message.
// note that incoming messages may skip ahead. this is convenient for the
// client side queueing because messages can't be renumbered, but the (kernel)
// client will occasionally pull a message out of the sent queue to send
// elsewhere. in that case it doesn't matter if we "got" it or not.
// 检查接收到的消息的序列号是否正确
uint64_t cur_seq = in_seq;
if (message->get_seq() <= cur_seq) {
message->put();
if (connection->has_feature(CEPH_FEATURE_RECONNECT_SEQ) &&
cct->_conf->ms_die_on_old_message) {
ceph_assert(0 == "old msgs despite reconnect_seq feature");
}
return nullptr;
}
if (message->get_seq() > cur_seq + 1) {
if (cct->_conf->ms_die_on_skipped_message) {
ceph_assert(0 == "skipped incoming seq");
}
}
。。。。。。。。。。。。。。。。。。。。。。。。。。
// note last received message.
in_seq = message->get_seq();
bool need_dispatch_writer = false;
if (!connection->policy.lossy) {
ack_left++;
need_dispatch_writer = true;
}
//根据接收到的消息的类型进行不同的处理
state = READY;
ceph::mono_time fast_dispatch_time;
//如果连接对象是一个blackhole,则直接释放该消息并跳转到 out 标签处
if (connection->is_blackhole()) {
ldout(cct, 10) << __func__ << " blackhole " << *message << dendl;
message->put();
goto out;
}
//进行消息的预处理
messenger->ms_fast_preprocess(message);
fast_dispatch_time = ceph::mono_clock::now();
if (connection->delay_state) {
...........
connection->delay_state->queue(delay_period, message);
} else if (messenger->ms_can_fast_dispatch(message)) {
//如果该消息可以被快速分发,则通过 fast_dispatch() 快速分发该消息
..............
if (state != READY) {
// yes, that was the case, let's do nothing
return nullptr;
}
} else {
//否则,将该消息加入到连接对象的消息队列(dispatch_queue)中。
connection->dispatch_queue->enqueue(message, message->get_priority(),
connection->conn_id);
}
handle_message_ack(current_header.ack_seq);
out:
if (need_dispatch_writer && connection->is_connected()) {
connection->center->dispatch_event_external(connection->write_handler);
}
//返回 CONTINUE(read_frame) 继续读取下一个消息。
return CONTINUE(read_frame);
}用于处理接收到的消息
bool ms_can_fast_dispatch(const ceph::cref_t<Message>& m) {
for (const auto &dispatcher : fast_dispatchers) {
if (dispatcher->ms_can_fast_dispatch2(m))
return true;
}
return false;
}
virtual bool ms_can_fast_dispatch2(const MessageConstRef& m) const {
return ms_can_fast_dispatch(m.get());
}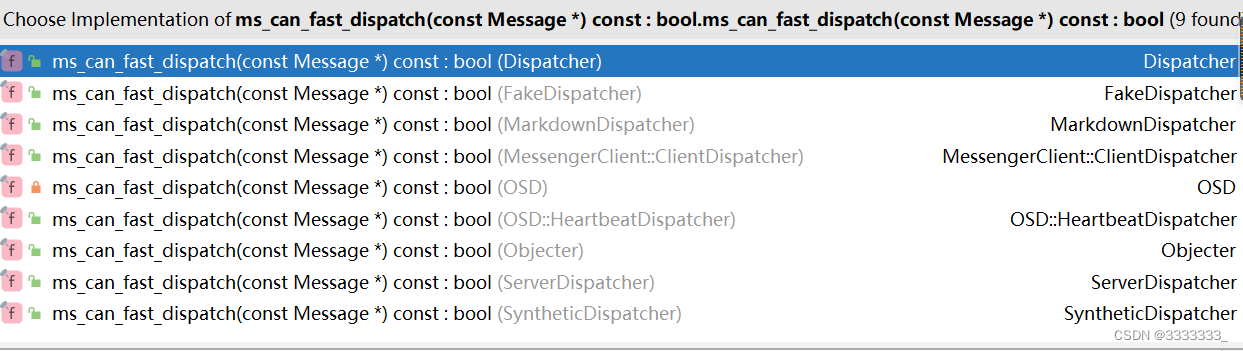
这个判断是否能够fast_dispatch,每Dispatcher实现不同,OSD的如下
bool ms_can_fast_dispatch(const Message *m) const override {
switch (m->get_type()) {
case CEPH_MSG_PING:
case CEPH_MSG_OSD_OP:
case CEPH_MSG_OSD_BACKOFF:
case MSG_OSD_SCRUB2:
case MSG_OSD_FORCE_RECOVERY:
case MSG_MON_COMMAND:
case MSG_OSD_PG_CREATE2:
case MSG_OSD_PG_QUERY:
case MSG_OSD_PG_QUERY2:
case MSG_OSD_PG_INFO:
case MSG_OSD_PG_INFO2:
case MSG_OSD_PG_NOTIFY:
case MSG_OSD_PG_NOTIFY2:
case MSG_OSD_PG_LOG:
case MSG_OSD_PG_TRIM:
case MSG_OSD_PG_REMOVE:
case MSG_OSD_BACKFILL_RESERVE:
case MSG_OSD_RECOVERY_RESERVE:
case MSG_OSD_REPOP:
case MSG_OSD_REPOPREPLY:
case MSG_OSD_PG_PUSH:
case MSG_OSD_PG_PULL:
case MSG_OSD_PG_PUSH_REPLY:
case MSG_OSD_PG_SCAN:
case MSG_OSD_PG_BACKFILL:
case MSG_OSD_PG_BACKFILL_REMOVE:
case MSG_OSD_EC_WRITE:
case MSG_OSD_EC_WRITE_REPLY:
case MSG_OSD_EC_READ:
case MSG_OSD_EC_READ_REPLY:
case MSG_OSD_SCRUB_RESERVE:
case MSG_OSD_REP_SCRUB:
case MSG_OSD_REP_SCRUBMAP:
case MSG_OSD_PG_UPDATE_LOG_MISSING:
case MSG_OSD_PG_UPDATE_LOG_MISSING_REPLY:
case MSG_OSD_PG_RECOVERY_DELETE:
case MSG_OSD_PG_RECOVERY_DELETE_REPLY:
case MSG_OSD_PG_LEASE:
case MSG_OSD_PG_LEASE_ACK:
return true;
default:
return false;
}
}DispatchQueue::fast_dispatch(Message *) DispatchQueue.h:203
void fast_dispatch(Message* m) {
return fast_dispatch(ceph::ref_t<Message>(m, false)); /* consume ref */
}
DispatchQueue::fast_dispatch(const boost::intrusive_ptr &) DispatchQueue.cc:74
void DispatchQueue::fast_dispatch(const ref_t<Message>& m)
{
uint64_t msize = pre_dispatch(m);
msgr->ms_fast_dispatch(m);
post_dispatch(m, msize);
}
uint64_t DispatchQueue::pre_dispatch(const ref_t<Message>& m)
{
//获取该消息需要占用的分发资源大小
uint64_t msize = m->get_dispatch_throttle_size();
//将其分发资源大小设置为 0,以便在requeue(重新排队)该消息时不会重复计算分发资源大小。
m->set_dispatch_throttle_size(0); // clear it out, in case we requeue this message.
//将占用的分发资源大小返回,以便后续进行分发资源的限制和控制
return msize;
}Messenger::ms_fast_dispatch(const boost::intrusive_ptr &) Messenger.h:685
void ms_fast_dispatch(const ceph::ref_t<Message> &m) {
//设置该消息的分发时间戳
m->set_dispatch_stamp(ceph_clock_now());
//遍历Messenger对象中注册的所有 Dispatcher,依次调用每个 Dispatcher的
//ms_can_fast_dispatch2()函数检查该消息是否可以被快速分发。
//如果找到一个可以处理该消息的Dispatcher,
//则调用该 Dispatcher的ms_fast_dispatch2()进行快速分发,并直接返回
for (const auto &dispatcher : fast_dispatchers) {
if (dispatcher->ms_can_fast_dispatch2(m)) {
dispatcher->ms_fast_dispatch2(m);
return;
}
}
//否则,调用ceph_abort()终止程序执行,表示没有找到能够处理该消息的Dispatcher
ceph_abort();
}通过fast_dispatch分发单个消息。会遍历Messenger对象中注册的所有 Dispatcher
Messenger::ms_fast_dispatch(const boost::intrusive_ptr &) Messenger.h:685
void ms_fast_dispatch(const ceph::ref_t<Message> &m) {
m->set_dispatch_stamp(ceph_clock_now());
for (const auto &dispatcher : fast_dispatchers) {
if (dispatcher->ms_can_fast_dispatch2(m)) {
dispatcher->ms_fast_dispatch2(m);
return;
}
}
ceph_abort();
}
Dispatcher.h
virtual bool ms_can_fast_dispatch(const Message *m) const { return false; }
virtual bool ms_can_fast_dispatch2(const MessageConstRef& m) const {
return ms_can_fast_dispatch(m.get());
}下面是几个ms_fast_dispatch实现
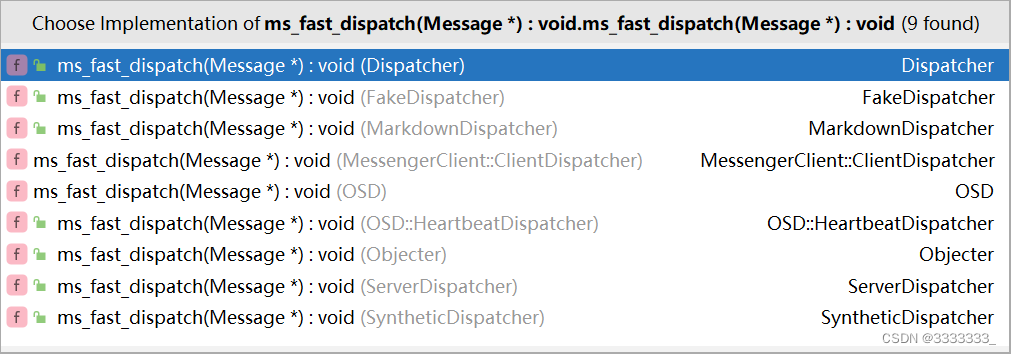
OSD::ms_fast_dispatch(Message *) OSD.cc:7313
void OSD::ms_fast_dispatch(Message *m)
{
如果当前 OSD 服务正在停止中,则直接释放该消息并返回。
if (service.is_stopping()) {
m->put();
return;
}
根据消息的类型进行不同的处理
// peering event?
switch (m->get_type()) {
case CEPH_MSG_PING: //直接释放该消息并返回
m->put();
return;
如果是 OSD 内部的 peering 事件(如 PG 创建、查询、通知、信息、删除等),则调用相应的处理函数进行处理
case MSG_OSD_FORCE_RECOVERY:
handle_fast_force_recovery(static_cast<MOSDForceRecovery*>(m));
return;
case MSG_OSD_SCRUB2:
handle_fast_scrub(static_cast<MOSDScrub2*>(m));
return;
case MSG_OSD_PG_CREATE2:
return handle_fast_pg_create(static_cast<MOSDPGCreate2*>(m));
case MSG_OSD_PG_QUERY:
return handle_fast_pg_query(static_cast<MOSDPGQuery*>(m));
case MSG_OSD_PG_NOTIFY:
return handle_fast_pg_notify(static_cast<MOSDPGNotify*>(m));
case MSG_OSD_PG_INFO:
return handle_fast_pg_info(static_cast<MOSDPGInfo*>(m));
case MSG_OSD_PG_REMOVE:
return handle_fast_pg_remove(static_cast<MOSDPGRemove*>(m));
如果是单个 PG 的操作消息(如 PG 日志、TRIM、通知、查询、信息、backfill、recovery等),
则将该消息的事件封装成 PGPeeringEventRef 对象并加入到 peering_evt_queue 队列中等待处理。
// these are single-pg messages that handle themselves
case MSG_OSD_PG_LOG:
case MSG_OSD_PG_TRIM:
case MSG_OSD_PG_NOTIFY2:
case MSG_OSD_PG_QUERY2:
case MSG_OSD_PG_INFO2:
case MSG_OSD_BACKFILL_RESERVE:
case MSG_OSD_RECOVERY_RESERVE:
case MSG_OSD_PG_LEASE:
case MSG_OSD_PG_LEASE_ACK:
{
MOSDPeeringOp *pm = static_cast<MOSDPeeringOp*>(m);
if (require_osd_peer(pm)) {
enqueue_peering_evt(pm->get_spg(),PGPeeringEventRef(pm->get_event()));
}
pm->put();
return;
}
}
创建一个 OpRequest 类型的请求 op,并将其添加到 op_tracker 中进行跟踪。
在跟踪时,根据请求的 reqid 输出相应的跟踪信息。
OpRequestRef op = op_tracker.create_request<OpRequest, Message*>(m);
{
#ifdef WITH_LTTNG
osd_reqid_t reqid = op->get_reqid();
#endif
tracepoint(osd, ms_fast_dispatch, reqid.name._type,
reqid.name._num, reqid.tid, reqid.inc);
}
#ifdef HAVE_JAEGER //Jaeger 分布式跟踪
op->set_osd_parent_span(dispatch_span);
if (op->osd_parent_span) {
auto op_req_span = jaeger_tracing::child_span("op-request-created", op->osd_parent_span);
op->set_osd_parent_span(op_req_span);
}
#endif
if (m->trace)
op->osd_trace.init("osd op", &trace_endpoint, &m->trace);
// note sender epoch, min req's epoch
//记录发送者的 epoch 和最小请求 epoch
op->sent_epoch = static_cast<MOSDFastDispatchOp*>(m)->get_map_epoch();
op->min_epoch = static_cast<MOSDFastDispatchOp*>(m)->get_min_epoch();
ceph_assert(op->min_epoch <= op->sent_epoch); // sanity check!
service.maybe_inject_dispatch_delay();
分发流程
//如果该OSD消息的连接支持重发特性或者该OSD消息不是CEPH_MSG_OSD_OP类型
if (m->get_connection()->has_features(CEPH_FEATUREMASK_RESEND_ON_SPLIT) ||
m->get_type() != CEPH_MSG_OSD_OP) {
// queue it directly
//则将该请求直接加入到 op_queue中,
这里的op_queue是一个有序队列,用于存储待分发的请求,
并按照请求的优先级进行有序处理。
enqueue_op(
static_cast<MOSDFastDispatchOp*>(m)->get_spg(),
std::move(op),
static_cast<MOSDFastDispatchOp*>(m)->get_map_epoch());
} else {
OSD消息m的连接不支持重发特性并且该OSD消息是MOSDOp类型的,
将该请求加入到该连接对应的会话的 waiting_on_map 队列中,
等待OSDMap更新后再进行分发。
注意:该函数只会在legacy client的MOSDOp类型的OSD消息中执行
// legacy client, and this is an MOSDOp (the *only* fast dispatch
// message that didn't have an explicit spg_t); we need to map
// them to an spg_t while preserving delivery order.
首先获取该 OSD 消息的连接的私有数据priv
然后将其转换为 Session 类型的指针 session
auto priv = m->get_connection()->get_priv();
if (auto session = static_cast<Session*>(priv.get()); session) {
如果session不为空,则加锁session的session_dispatch_lock
std::lock_guard l{session->session_dispatch_lock};
并通过op->get()将op的引用计数增加一
op->get();
将op添加到session的waiting_on_map队列中,等待OSDMap更新后再进行分发。
session->waiting_on_map.push_back(*op);
获取下一个OSDMap的引用,并将其保存到变量nextmap中
OSDMapRef nextmap = service.get_nextmap_reserved();
将session的waiting_on_map队列中待分发的请求进行处理
dispatch_session_waiting(session, nextmap);
释放 nextmap 引用
service.release_map(nextmap);
}
}
OID_EVENT_TRACE_WITH_MSG(m, "MS_FAST_DISPATCH_END", false);
}通过快速分发方式分发单个 OSD 消息,上面代码的put操作的作用是将该对象的引用计数减一,并在引用计数变为 0 时释放该对象
void RefCountedObject::put() const {
CephContext *local_cct = cct;
auto v = --nref;
if (local_cct) {
lsubdout(local_cct, refs, 1) << "RefCountedObject::put " << this << " "
<< (v + 1) << " -> " << v
<< dendl;
}
if (v == 0) {
ANNOTATE_HAPPENS_AFTER(&nref);
ANNOTATE_HAPPENS_BEFORE_FORGET_ALL(&nref);
delete this;
} else {
如果减一后的引用计数不为 0,
则通过ANNOTATE_HAPPENS_BEFORE()函数标记该对象的引用计数发生了变化,但不进行释放操作。
ANNOTATE_HAPPENS_BEFORE(&nref);
}
}RefCountedObject 类是一个基类,用于实现引用计数机制。其构造函数会将引用计数初始化为 1,表示对象被创建时有一个引用计数。当该对象被复制或传递引用时,其引用计数会增加;当该对象被释放或不再需要时,其引用计数会减少。当引用计数变为 0 时,表示该对象不再被任何其他对象引用,可以安全地释放其内存空间。
put() 函数会将该对象的引用计数减一,并将减一后的引用计数值赋给变量 v。如果 CephContext 对象的指针不为空,则输出日志记录该对象的引用计数变化。
如果减一后的引用计数变为 0,则通过 ANNOTATE_HAPPENS_AFTER() 和 ANNOTATE_HAPPENS_BEFORE_FORGET_ALL() 函数标记该对象的生命周期结束,然后释放该对象的内存空间
ANNOTATE_HAPPENS_AFTER() 和 ANNOTATE_HAPPENS_BEFORE_FORGET_ALL() 函数是 Google 开源工具 Annotate的一部分,用于帮助分析内存中的对象生命周期。它们的作用是标记对象的生命周期结束,以便在后续的内存泄漏检测中排除该对象。
void OSD::dispatch_session_waiting(const ceph::ref_t<Session>& session, OSDMapRef osdmap)
{
ceph_assert(ceph_mutex_is_locked(session->session_dispatch_lock));
从session的waiting_on_map队列中取出请求进行处理
auto i = session->waiting_on_map.begin();
while (i != session->waiting_on_map.end()) {
OpRequestRef op = &(*i);
对于每个请求,首先判断其是否可以进行快速分发
ceph_assert(ms_can_fast_dispatch(op->get_req()));
auto m = op->get_req<MOSDFastDispatchOp>();
如果请求的最小epoch大于当前的OSDMap的epoch,则跳过该请求
if (m->get_min_epoch() > osdmap->get_epoch()) {
break;
}
否则将其加入到相应的op_queue中等待分发
session->waiting_on_map.erase(i++);
op->put();
spg_t pgid;
如果该请求是MOSDOp类型的OSD消息
if (m->get_type() == CEPH_MSG_OSD_OP) {
将原始的 pg_t 转换为实际的 spg_t
pg_t actual_pgid = osdmap->raw_pg_to_pg(static_cast<const MOSDOp*>(m)->get_pg());
获取该spg_t对应的primary shard,并将其保存到变量pgid中
if (!osdmap->get_primary_shard(actual_pgid, &pgid)) {
continue;
}
} else {
pgid = m->get_spg();
}
将该请求加入到与 pgid对应的op_queue中等待分发。
enqueue_op(pgid, std::move(op), m->get_map_epoch());
}
if (session->waiting_on_map.empty()) {
clear_session_waiting_on_map(session);
} else {
register_session_waiting_on_map(session);
}
}处理会话中等待OSDMap的请求,注意:该函数只会在legacy client的 MOSDOp 类型的OSD消息中执行,而对于其他类型的 OSD 消息,则直接将其加入到 op_queue中等待分发。
OSD::ms_fast_dispatch(Message *) OSD.cc:7313
enqueue_op(
static_cast<MOSDFastDispatchOp*>(m)->get_spg(),
std::move(op),
static_cast<MOSDFastDispatchOp*>(m)->get_map_epoch());
将MOSDFastDispatchOp类型的OSD消息加入到相应的spg_t对应的op_queue中等待分发。
OSD::enqueue_op(spg_t, boost::intrusive_ptr &&, unsigned int) OSD.cc:9951
void OSD::enqueue_op(spg_t pg, OpRequestRef&& op, epoch_t epoch)
{
获取一些基本信息,如请求的接收时间、请求的优先级、
请求的成本、请求的来源OSD节点ID、请求的类型等。
const utime_t stamp = op->get_req()->get_recv_stamp();
const utime_t latency = ceph_clock_now() - stamp;
const unsigned priority = op->get_req()->get_priority();
const int cost = op->get_req()->get_cost();
const uint64_t owner = op->get_req()->get_source().num();
const int type = op->get_req()->get_type();
.....................
将OpRequest标记为已经在spg_t对应的op_queue中等待分发
op->mark_queued_for_pg();
通过调用op_shardedwq对象的queue()函数将OpRequest封装成OpSchedulerItem并
加入到相应的spg_t对应的op_queue中等待分发。
根据请求的类型判断是将请求加入到PGOpItem类型的op_queue中等待分发,
还是将请求加入到PGRecoveryMsg类型的op_queue中等待分发
if (type == MSG_OSD_PG_PUSH ||type == MSG_OSD_PG_PUSH_REPLY) {
PGRecoveryMsg类型的op_queue主要用于处理PG恢复相关的消息
op_shardedwq.queue(
OpSchedulerItem(
unique_ptr<OpSchedulerItem::OpQueueable>(new PGRecoveryMsg(pg, std::move(op))),
cost, priority, stamp, owner, epoch));
} else {
PGOpItem类型的op_queue主要用于处理OSD操作
op_shardedwq.queue(
OpSchedulerItem(
unique_ptr<OpSchedulerItem::OpQueueable>(new PGOpItem(pg, std::move(op))),
cost, priority, stamp, owner, epoch));
}
}ShardedThreadPool::ShardedWQ::queue(ceph::osd::scheduler::OpSchedulerItem &&) WorkQueue.h:616
void queue(T&& item) {
_enqueue(std::move(item));
}OSD::ShardedOpWQ::_enqueue(ceph::osd::scheduler::OpSchedulerItem &&) OSD.cc:11306
void OSD::ShardedOpWQ::_enqueue(OpSchedulerItem&& item) {
每个OSD分片都有自己的工作队列
//并且使用get_ordering_token方法确定应将该项加入到哪个分片的队列中
//调用hash_to_shard()方法并传入OSD集群中的分片数,以获取应将项加入的分片的索引
uint32_t shard_index =item.get_ordering_token().hash_to_shard(osd->shards.size());
//shards数组是OSD对象维护的一个包含所有分片的数组,每个元素代表一个分片的OSDShard对象。
OSDShard* sdata = osd->shards[shard_index];
assert (NULL != sdata);
bool empty = true;
{
std::lock_guard l{sdata->shard_lock};//在目标分片的工作队列上获取锁,避免多个线程同时访问该分片的工作队列
// 检查该分片的工作队列是否为空
empty = sdata->scheduler->empty();
//将OpSchedulerItem对象加入到该分片的工作队列中
避免不必要的拷贝,这里使用了std::move将item对象的所有权转移给enqueue方法
sdata->scheduler->enqueue(std::move(item));
}
{
std::lock_guard l{sdata->sdata_wait_lock};//在目标分片的等待队列上获取锁
//根据变量empty和sdata->waiting_threads的值来决定是否通知等待队列上的线程
if (empty) {
sdata->sdata_cond.notify_all();
} else if (sdata->waiting_threads) {//如果该分片的工作不为空,且有线程处于等待状态,
//因为此时工作队列中仍然有工作项等待处理,
//所以只需要通知等待队列上的一个线程即可。这样可以减少通知的开销,避免通知过多的等待线程。
//从而提高系统的性能。
sdata->sdata_cond.notify_one();
}
}
}负责将一个OpSchedulerItem对象加入一个由OSD维护的分片工作队列中。
上面核心代码举例理解
if (empty) {
sdata->sdata_cond.notify_all();
} else if (sdata->waiting_threads) {
sdata->sdata_cond.notify_one();
}假设有一个餐厅,有多个服务员在为客人服务。服务员们需要轮流地去厨房取餐,但厨房只能同时容纳一定数量的服务员。为了协调服务员们的取餐行为,餐厅引入了一个操作调度器,用于调度服务员们的取餐行为。
在这个例子中,每个服务员都相当于一个线程,厨房相当于一个分片,餐厅的操作调度器相当于Ceph中的ShardedOpWQ。服务员们需要轮流地去厨房取餐,而操作调度器则负责调度服务员们的取餐行为。
当一个服务员要去厨房取餐时,它会先尝试向操作调度器中加入一个取餐操作。如果操作调度器中对应的分片为空,即当前没有服务员在该分片上等待取餐,那么该服务员就可以直接去厨房取餐了。如果操作调度器中对应的分片不为空,即有其他服务员正在该分片上等待取餐,那么该服务员就需要先等待其他服务员取餐完成后再去厨房取餐。
在这个例子中,notify_all()函数可以理解为当厨房没有服务员等待取餐时,通知所有服务员可以去厨房取餐了;而notify_one()函数可以理解为当厨房有服务员等待取餐时,通知其中一个服务员可以去厨房取餐了。通过使用条件变量和锁,可以确保每个服务员能够公平地轮流去厨房取餐,避免了服务员之间的竞争和冲突,提高了餐厅的效率和服务质量。
ceph::osd::scheduler::ClassedOpQueueScheduler::enqueue(ceph::osd::scheduler::OpSchedulerItem &&) OpScheduler.h:105
void enqueue(OpSchedulerItem &&item) final {
unsigned priority = item.get_priority();
unsigned cost = item.get_cost();
根据当前操作调度器的cutoff值来判断是否需要进行严格的优先级调度
if (priority >= cutoff)
queue.enqueue_strict(item.get_owner(), priority, std::move(item));
else//加入到操作调度器的普通队列中。
queue.enqueue(item.get_owner(), priority, cost, std::move(item));
}将Op加入到操作调度器的队列中,会根据操作的优先级(priority)和成本(cost)将操作加入到操作调度器的不同队列中。
WeightedPriorityQueue::enqueue(unsigned long, unsigned int, unsigned int, ceph::osd::scheduler::OpSchedulerItem &&) WeightedPriorityQueue.h:324
void enqueue(K cl, unsigned p, unsigned cost, T&& item) final {
normal.insert(p, cl, cost, std::move(item));
}将Op加入到操作调度器的普通队列中,该队列是根据操作的成本(cost)来进行调度的
void insert(unsigned p, K cl, unsigned cost, T&& item, bool front = false) {
typename SubQueues::insert_commit_data insert_data;
//检查是否已经存在与该元素具有相同优先级的子队列,
//如果不存在,则调用insert_unique_commit()函数创建一个新的子队列。
std::pair<typename SubQueues::iterator, bool> ret =
queues.insert_unique_check(p, MapKey<SubQueue, unsigned>(), insert_data);
if (ret.second) {
ret.first = queues.insert_unique_commit(*new SubQueue(p), insert_data);
total_prio += p;
}
ret.first->insert(cl, cost, std::move(item), front);
if (cost > max_cost) {
max_cost = cost;
}
}
在插入元素时,该函数会将元素插入到子队列中,并计算该子队列中元素的总成本(total_cost)。同时,
该函数会记录整个队列中最大的成本(max_cost),以便后续可以快速地找到成本最大的元素。元素首先按照优先级进行分组,然后在每个子队列中按照成本进行排序。这样可以保证高优先级的元素能够优先得到处理,同时尽量避免成本较大的元素占用过多的系统资源,从而提高整个系统的资源利用率和负载均衡。
2、操作出队,进行处理
Thread::_entry_func(void *) Thread.cc:74
void *Thread::_entry_func(void *arg) {
void *r = ((Thread*)arg)->entry_wrapper();
return r;
}Thread::entry_wrapper() Thread.cc:87
void *Thread::entry_wrapper()
{
int p = ceph_gettid(); // may return -ENOSYS on other platforms
if (p > 0)
pid = p;
if (pid && cpuid >= 0)
_set_affinity(cpuid);
ceph_pthread_setname(pthread_self(), thread_name.c_str());
return entry();
}ShardedThreadPool::WorkThreadSharded::entry() WorkQueue.h:637
// threads
struct WorkThreadSharded : public Thread {
ShardedThreadPool *pool;
uint32_t thread_index;
WorkThreadSharded(ShardedThreadPool *p, uint32_t pthread_index): pool(p),
thread_index(pthread_index) {}
void *entry() override {
pool->shardedthreadpool_worker(thread_index);
return 0;
}
};ShardedThreadPool::shardedthreadpool_worker(unsigned int) WorkQueue.cc:313
//ShardedThreadPool线程池的一个工作线程函数
void ShardedThreadPool::shardedthreadpool_worker(uint32_t thread_index)
{
std::stringstream ss;
ss << name << " thread " << (void *)pthread_self();
auto hb = cct->get_heartbeat_map()->add_worker(ss.str(), pthread_self());
while (!stop_threads) {
if (pause_threads) {//如果线程池被暂停
std::unique_lock ul(shardedpool_lock);
++num_paused;
wait_cond.notify_all();
while (pause_threads) {
//在等待期间不断地重置心跳超时时间,以确保能够及时检测到线程池的状态变化
cct->get_heartbeat_map()->reset_timeout(
hb,
wq->timeout_interval,
wq->suicide_interval);
shardedpool_cond.wait_for(
ul,
std::chrono::seconds(cct->_conf->threadpool_empty_queue_max_wait));
}
--num_paused;
}
drain_threads是Ceph中ShardedThreadPool线程池的一个状态变量(bool类型),
用于控制线程池的停止或暂停操作。当drain_threads为true时,
表示线程池需要进行停止或暂停操作;当drain_threads为false时,表示线程池正常运行。
通过使用drain_threads状态和计数器num_drained,Ceph可以实现线程池的优雅停止和暂停。
当线程池被设置为drain_threads状态时,工作线程会等待所有操作调度器中的操作都被处理完
毕后再退出,从而保证操作的完整性和一致性。同时,通过使用计数器num_drained,
Ceph可以实现多个工作线程同时等待的功能,从而提高线程池的效率和性能。
if (drain_threads) {//如果drain_threads为真,也就是线程池被设置为drain_threads状态(需要进行停止或暂停操作)
std::unique_lock ul(shardedpool_lock);
//判断当前操作调度器是否为空
if (wq->is_shard_empty(thread_index)) {
++num_drained;//表示当前工作线程已经被暂停或停止。
//通知所有等待在wait_cond条件变量上的线程,表示当前工作线程已经被暂停或停止。
wait_cond.notify_all();
while (drain_threads) {
//重置当前工作线程的心跳机制超时时间。
cct->get_heartbeat_map()->reset_timeout(hb,wq->timeout_interval,wq->suicide_interval);
//在等待期间,该线程会释放shardedpool_lock锁并进入休眠状态。
shardedpool_cond.wait_for(
ul,std::chrono::seconds(cct->_conf->threadpool_empty_queue_max_wait));
}
//当线程从wait_for()函数中返回时,将计数器num_drained减1,
//表示当前工作线程已经重新开始工作。
--num_drained;
}
}
重置当前工作线程的心跳机制超时时间
cct->get_heartbeat_map()->reset_timeout(hb,wq->timeout_interval,
wq->suicide_interval);
处理下一个操作,thread_index表示当前工作线程的索引
wq->_process(thread_index, hb);
}
将当前工作线程从心跳机制中删除
cct->get_heartbeat_map()->remove_worker(hb);
心跳机制是Ceph中用于监控线程池和操作调度器状态的一种机制。
每个工作线程都会通过心跳机制向心跳对象汇报自己的状态信息,
心跳机制可以根据心跳对象的状态信息来判断线程池和操作调度器是否处于正常工作状态。
当一个工作线程结束工作时,需要将自己从心跳机制中删除,
以便心跳机制不再监控该工作线程的状态信息。
}用于执行操作调度器(ShardedOpWQ)中的操作,该函数会循环地从操作调度器中获取操作并执行,直到线程池被停止或暂停。
OSD::ShardedOpWQ::_process(unsigned int, ceph::heartbeat_handle_d *) OSD.cc:11277
这个方法代码有300多行
从工作队列中取出并处理工作项,大概进行下分析(代码在前,分析在后)
uint32_t shard_index = thread_index % osd->num_shards;
auto& sdata = osd->shards[shard_index];
首先确定当前线程被分配到哪个分片,然后锁定对应的分片数据结构。
bool is_smallest_thread_index = thread_index < osd->num_shards;
判断当前线程的线程ID是否小于分片数,用于判断是否需要处理oncommit回调。
// peek at spg_t
sdata->shard_lock.lock();
if (sdata->scheduler->empty() &&
(!is_smallest_thread_index || sdata->context_queue.empty())) {
// ...如果调度器为空,并且当前线程不是最小的线程ID,或者上下文队列也为空,
则线程需要等待工作项的到来
检查当前线程是否被竞争到了上下文队列的添加,如果是,则不需要等待。
if (is_smallest_thread_index && !sdata->context_queue.empty()) {
// we raced with a context_queue addition, don't wait
wait_lock.unlock();
} else if (!sdata->stop_waiting) {//OSD没有在关闭
等待期间,需要清除心跳超时hb,以防止在等待期间发生心跳超时
osd->cct->get_heartbeat_map()->clear_timeout(hb);
sdata->shard_lock.unlock();
//等待条件变量sdata_cond 直到其他线程添加了新的工作项
sdata->sdata_cond.wait(wait_lock);
wait_lock.unlock();
重新获取shard_lock锁,检查调度器是否为空
sdata->shard_lock.lock();
if (sdata->scheduler->empty() &&
!(is_smallest_thread_index && !sdata->context_queue.empty())) {
//如果调度器为空并且当前线程不需要处理 oncommit 回调
sdata->shard_lock.unlock();
return;
}
走到这表示不为空,则可以处理工作项,重新设置心跳超时
// found a work item; reapply default wq timeouts
osd->cct->get_heartbeat_map()->reset_timeout(hb,timeout_interval, suicide_interval);
} else {//OSD正在关闭,释放wait_lock和shard_lock 锁,并返回
wait_lock.unlock();
sdata->shard_lock.unlock();
return;
}
}
list<Context *> oncommits;
if (is_smallest_thread_index) {
sdata->context_queue.move_to(oncommits);
}
如果当前线程是最小线程ID,则需要将上下文队列中的所有oncommit回调移动到oncommits 列表中。
WorkItem work_item;
直到获取到一个OpSchedulerItem类型的工作项为止
while (!std::get_if<OpSchedulerItem>(&work_item)) {
if (sdata->scheduler->empty()) {//调度器为空
if (osd->is_stopping()) {//OSD是否正在关闭
sdata->shard_lock.unlock();
丢弃所有待处理的 oncommit 回调,然后返回
for (auto c : oncommits) {
delete c;
}
return; // OSD shutdown, discard.
}
sdata->shard_lock.unlock();
走到这表示OSD不是正在关闭,需要处理所有的oncommit回调,并返回。
handle_oncommits(oncommits);
return;
}
//从调度器中获取一个工作项
work_item = sdata->scheduler->dequeue();
if (osd->is_stopping()) {//如果OSD正在关闭
sdata->shard_lock.unlock();
for (auto c : oncommits) {//丢弃所有待处理的oncommit回调,然后返回
delete c;
}
return; // OSD shutdown, discard.
}
// If the work item is scheduled in the future, wait until
// the time returned in the dequeue response before retrying.
//检查获取到的工作项是否是一个未来的时间戳
if (auto when_ready = std::get_if<double>(&work_item)) {
//如果当前线程是最小线程ID,则需要处理所有的oncommit回调,并返回
if (is_smallest_thread_index) {
sdata->shard_lock.unlock();
handle_oncommits(oncommits);
return;
}
//需要等待到指定的时间点再重试。在等待期间,需要禁用心跳超时,以防止在等待期间发生心跳超时。
std::unique_lock wait_lock{sdata->sdata_wait_lock};
auto future_time = ceph::real_clock::from_double(*when_ready);
// Disable heartbeat timeout until we find a non-future work item to process.
osd->cct->get_heartbeat_map()->clear_timeout(hb);
sdata->shard_lock.unlock();
++sdata->waiting_threads;
sdata->sdata_cond.wait_until(wait_lock, future_time);
--sdata->waiting_threads;
wait_lock.unlock();
sdata->shard_lock.lock();
// Reapply default wq timeouts
osd->cct->get_heartbeat_map()->reset_timeout(hb,
timeout_interval, suicide_interval);
}
} // while
// Access the stored item
访问存储在work_item变量中的OpSchedulerItem类型的工作项,并将其移动到item变量中。
auto item = std::move(std::get<OpSchedulerItem>(work_item));
if (osd->is_stopping()) {//重复 同之前
sdata->shard_lock.unlock();
for (auto c : oncommits) {
delete c;
}
return; // OSD shutdown, discard.
}
const auto token = item.get_ordering_token();
auto r = sdata->pg_slots.emplace(token, nullptr);
if (r.second) {
r.first->second = make_unique<OSDShardPGSlot>();
}
OSDShardPGSlot *slot = r.first->second.get();
slot->to_process.push_back(std::move(item));
将工作项添加到OSDShardPGSlot的to_process列表中,以等待被处理
retry_pg:
PGRef pg = slot->pg;
// lock pg (if we have it)
如果PG对象存在,则需要先锁定PG对象,以确保不会有其他线程同时访问该对象
if (pg) {
// note the requeue seq now...
uint64_t requeue_seq = slot->requeue_seq;
++slot->num_running;
sdata->shard_lock.unlock();
osd->service.maybe_inject_dispatch_delay();
pg->lock();
osd->service.maybe_inject_dispatch_delay();
sdata->shard_lock.lock();
//查找存储token排序令牌的OSDShardPGSlot对象
auto q = sdata->pg_slots.find(token);
if (q == sdata->pg_slots.end()) {
//如果找不到则说明该对象已被删除,需要解锁PG对象并立即返回。
pg->unlock();
sdata->shard_lock.unlock();
handle_oncommits(oncommits);
return;
}
slot = q->second.get();
--slot->num_running;
if (slot->to_process.empty()) {
//检查to_process列表是否为空。如果列表为空,则说明工作项已被消费或已被清除,
需要解锁PG对象并立即返回。
// raced with _wake_pg_slot or consume_map
dout(20) << __func__ << " " << token
<< " nothing queued" << dendl;
pg->unlock();
sdata->shard_lock.unlock();
handle_oncommits(oncommits);
return;
}
如果to_process列表不为空,则需要检查重试序列号是否匹配
if (requeue_seq != slot->requeue_seq) {
如果不匹配,则说明在重试期间另一个线程已经修改了OSDShardPGSlot对象,
需要解锁PG对象并立即返回。
pg->unlock();
sdata->shard_lock.unlock();
handle_oncommits(oncommits);
return;
}
如果重试序列号匹配,则检查PG对象是否匹配
if (slot->pg != pg) {
//如果不匹配,则说明在重试期间另一个线程已经删除了PG对象,
需要解锁PG对象并使用goto语句跳转到retry_pg标签处,重新尝试获取PG对象
// this can happen if we race with pg removal.
pg->unlock();
goto retry_pg;
}
}
重试 OSDShardPGSlot 中的工作项
//用于处理后续的操作请求
ThreadPool::TPHandle tp_handle(osd->cct, hb, timeout_interval,suicide_interval);
// take next item
。。。。。。。
while (!pg) {//为了找到pg对象
// should this pg shard exist on this osd in this (or a later) epoch?
osdmap = sdata->shard_osdmap;
const PGCreateInfo *create_info = qi.creates_pg();
如果当前正在等待split操作,将当前槽的等待列表添加到_waiting_for_split列表中。
if (!slot->waiting_for_split.empty()) {
_add_slot_waiter(token, slot, std::move(qi));
} else if (qi.get_map_epoch() > osdmap->get_epoch()) {
//如果当前操作请求的epoch大于当前OSDMap的epoch,将当前槽的等待列表添加到_waiting_for_pg列表中。
_add_slot_waiter(token, slot, std::move(qi));
} else if (qi.is_peering()) {//如果当前操作请求是 peering 操作
//判断当前OSD是否应该创建PG
if (!qi.peering_requires_pg()) {
// for pg-less events, we run them under the ordering lock, since
// we don't have the pg lock to keep them ordered.
直接在ordering lock下运行该操作请求
qi.run(osd, sdata, pg, tp_handle);
} else if (osdmap->is_up_acting_osd_shard(token, osd->whoami)) {
当前OSD是PG的primary OSD
if (create_info) {//需要创建PG对象
//如果该PG对象是由monitor创建的,并且当前OSD不是该PG的primary OSD,则忽略该操作请求
if (create_info->by_mon &&
osdmap->get_pg_acting_primary(token.pgid) != osd->whoami) {
} else {
创建PG对象
pg = osd->handle_pg_create_info(osdmap, create_info);
if (pg) {//创建成功
// we created the pg! drop out and continue "normally"!
该PG对象添加到_pg_slots 中,并唤醒等待该PG的操作请求
sdata->_attach_pg(slot, pg.get());
sdata->_wake_pg_slot(token, slot);
// identify split children between create epoch and shard epoch.
找出在创建PG对象和当前OSDMap epoch之间分裂的子PG,将这些子PG添加到new_children变量中
osd->service.identify_splits_and_merges(pg->get_osdmap(), osdmap, pg->pg_id, &new_children, nullptr);
将这些子PG添加到列表中,并退出循环
sdata->_prime_splits(&new_children);
// distribute remaining split children to other shards below!
break;
}
}
} else {
}
} else {
}
} else if (osdmap->is_up_acting_osd_shard(token, osd->whoami)) {
//如果当前OSD是PG的primary OSD,但该PG对象还未创建完成
_add_slot_waiter(token, slot, std::move(qi));
} else {
// share map with client?
if (std::optional<OpRequestRef> _op = qi.maybe_get_op()) {
如果该操作请求中包含了需要分享OSDMap的请求,
则执行service.maybe_share_map()分享OSDMap
osd->service.maybe_share_map((*_op)->get_req()->get_connection().get(),
sdata->shard_osdmap,
(*_op)->sent_epoch);
}
//处理无法执行的peering操作请求时,如果该操作请求中包含了需要保留的推送数据,
则释放这些数据并退出
unsigned pushes_to_free = qi.get_reserved_pushes();
if (pushes_to_free > 0) {
sdata->shard_lock.unlock();
osd->service.release_reserved_pushes(pushes_to_free);
handle_oncommits(oncommits);
return;
}
}
sdata->shard_lock.unlock();
handle_oncommits(oncommits);
return;
}
if (qi.is_peering()) {//peering操作请求时
OSDMapRef osdmap = sdata->shard_osdmap;
if (qi.get_map_epoch() > osdmap->get_epoch()) {
如果当前OSDMap epoch已经更新,则将该操作请求添加到_wait_for_pg 列表中等待
_add_slot_waiter(token, slot, std::move(qi));
sdata->shard_lock.unlock();
pg->unlock();
handle_oncommits(oncommits);
return;
}
}
在创建新的PG对象后
if (!new_children.empty()) {//如果有需要添加的分裂的子PG
遍历所有OSD的shard对于每个shard,调用prime_splits函数将这些子PG添加
到_splitting_pgs 列表中。
for (auto shard : osd->shards) {
shard->prime_splits(osdmap, &new_children);
}
}
Formatter *f = Formatter::create("json");
f->open_object_section("q");
dump(f);
f->close_section();
f->flush(*_dout);
delete f;
qi.run(osd, sdata, pg, tp_handle);
handle_oncommits(oncommits);
处理一个操作请求完成后的操作,主要包括以下几个步骤:
记录日志信息,输出当前操作请求队列的状态。
调用qi.run()执行下一个操作请求。
如果 LTTNG 已经启用,则记录当前操作请求的 reqid。
调用handle_oncommits()处理提交的操作。
ceph::osd::scheduler::OpSchedulerItem::run(OSD *, OSDShard *, boost::intrusive_ptr &, ThreadPool::TPHandle &) OpSchedulerItem.h:148
void run(OSD *osd, OSDShard *sdata,PGRef& pg, ThreadPool::TPHandle &handle) {
qitem->run(osd, sdata, pg, handle);
}ceph::osd::scheduler::PGOpItem::run(OSD *, OSDShard *, boost::intrusive_ptr &, ThreadPool::TPHandle &) OpSchedulerItem.cc:32
void PGOpItem::run(
OSD *osd,
OSDShard *sdata,
PGRef& pg,
ThreadPool::TPHandle &handle)
{
osd->dequeue_op(pg, op, handle);
pg->unlock();
}OSD::dequeue_op(boost::intrusive_ptr, boost::intrusive_ptr, ThreadPool::TPHandle &) OSD.cc:10005
void OSD::dequeue_op(
PGRef pg, OpRequestRef op,
ThreadPool::TPHandle &handle)
{
记录操作请求的相关信息,包括请求的时间、优先级、成本、延迟等,并输出日志信息
。。。。。。。。。。。。。。。。。。
service.maybe_share_map(m->get_connection().get(),
pg->get_osdmap(),
op->sent_epoch);
if (pg->is_deleting())
果该操作请求所对应的PG正在被删除,则直接返回
return;
op->mark_reached_pg();//标记该操作请求已经到达PG对象。
op->osd_trace.event("dequeue_op");
pg->do_request(op, handle);//执行该操作请求。
}PrimaryLogPG::do_request(boost::intrusive_ptr &, ThreadPool::TPHandle &) PrimaryLogPG.cc:1831
void PrimaryLogPG::do_request(
OpRequestRef& op,
ThreadPool::TPHandle &handle)
{
。。。。。
// make sure we have a new enough map
确保OSD模块拥有最新的OSD map,并根据当前OSD map的情况来决
定是否需要等待OSD map的更新
auto p = waiting_for_map.find(op->get_source());
查找等待OSD map更新的操作列表waiting_for_map中是否已经存在该操作的源。
如果该源的操作列表已经存在,则该操作会被添加到该源的操作列表中,并且被标记为延迟执行。
if (p != waiting_for_map.end()) {
// preserve ordering
p->second.push_back(op);
// 标记op为延迟,原因是 "waiting_for_map 不为空"
op->mark_delayed("waiting_for_map not empty");
return;
}
如果该源的操作列表不存在,那么该代码会检查该操作的最小OSD map版本是否比当前
OSD map的版本还要新。如果该操作的最小OSD map版本比当前OSD map的版本还要新,
那么该操作必须等待OSD map的更新。在这种情况下,该操作将被添加到等待
OSD map更新的操作列表waiting_for_map中,并且该操作也被标记为延迟执行。
同时,该代码还会发送请求更新OSD map 的请求给 OSD,以便尽快获取最新的OSD map。
if (!have_same_or_newer_map(op->min_epoch)) {
waiting_for_map[op->get_source()].push_back(op);
op->mark_delayed("op must wait for map");
osd->request_osdmap_update(op->min_epoch);
return;
}
if (can_discard_request(op)) {
return;
}
在处理OSD操作时,检查是否需要对该操作进行backoff(暂停执行)
// pg-wide backoffs
const Message *m = op->get_req();//获取该操作对应的消息类型
int msg_type = m->get_type();
如果该连接支持backoff功能
if (m->get_connection()->has_feature(CEPH_FEATURE_RADOS_BACKOFF)) {
获取该操作对应的会话
auto session = ceph::ref_cast<Session>(m->get_connection()->get_priv());
if (!session)
return; // drop it.
if (msg_type == CEPH_MSG_OSD_OP) {
检查该操作是否需要进行 backoff
if (session->check_backoff(cct, info.pgid,
info.pgid.pgid.get_hobj_start(), m)) {
return;
}
如果OSD处于down或incomplete状态,或者OSD既不是active状态也不是peered状态,
则需要进行 backoff
bool backoff =is_down() ||is_incomplete() ||(!is_active() && is_peered());
如果配置项 osd_backoff_on_peering 为真,并且 OSD 正处于 peering 状态,则也需要进行 backoff
if (g_conf()->osd_backoff_on_peering && !backoff) {
if (is_peering()) {
backoff = true;
}
}
if (backoff) {
将该会话添加到 pg backoff 列表中,并且直接返回,不继续执行该操作。
add_pg_backoff(session);
return;
}
}
// pg backoff acks at pg-level
if (msg_type == CEPH_MSG_OSD_BACKOFF) {
如果收到的 backoff 消息不是结束消息,则需要处理 backoff,否则不做处理。
const MOSDBackoff *ba = static_cast<const MOSDBackoff*>(m);
if (ba->begin != ba->end) {
handle_backoff(op);
return;
}
}
}
if (!is_peered()) {
// Delay unless PGBackend says it's ok
if (pgbackend->can_handle_while_inactive(op)) {
如果 PGBackend 对象可以在 inactive 状态下处理该操作(即在 PG 还没有 peered 的情况下也可以处理该操作)
bool handled = pgbackend->handle_message(op);
ceph_assert(handled);
return;
} else {
将该操作添加到 waiting_for_peered 列表中,并且被标记为延迟执行
waiting_for_peered.push_back(op);
op->mark_delayed("waiting for peered");
return;
}
需要注意的是,如果PG还没有 peered,那么无论是处理该操作还是等待该操作,
都不会影响 PG 中的数据一致性,因为此时该 PG 中的所有 OSD 都处于 inactive 状态,
还没有开始处理该PG中的数据。只有在所有 OSD 都已经 peered 之后,才会开始正式处理该
PG 中的数据。
}
flush(即需要将数据写入到磁盘中)
if (recovery_state.needs_flush()) {
dout(20) << "waiting for flush on " << op << dendl;
waiting_for_flush.push_back(op);
op->mark_delayed("waiting for flush");
return;
}
ceph_assert(is_peered() && !recovery_state.needs_flush());
如果当前OSD所属的PG(Placement Group)已经peered 并且不需要 flush,
则直接调用PGBackend对象的handle_message方法来处理该操作。
if (pgbackend->handle_message(op))
return;
根据消息类型来分发OSD操作,并进行相应的处理
switch (msg_type) {
case CEPH_MSG_OSD_OP:
case CEPH_MSG_OSD_BACKOFF:
。。。。
switch (msg_type) {
case CEPH_MSG_OSD_OP: //这里是进此分支
。。。
do_op(op);
break;
case CEPH_MSG_OSD_BACKOFF:
// object-level backoff acks handled in osdop context
handle_backoff(op);
break;
}
break;
case MSG_OSD_PG_SCAN:
do_scan(op, handle);
break;
case MSG_OSD_PG_BACKFILL:
do_backfill(op);
break;
case MSG_OSD_PG_BACKFILL_REMOVE:
do_backfill_remove(op);
break;
case MSG_OSD_SCRUB_RESERVE:
{
if (!m_scrubber) {
osd->reply_op_error(op, -EAGAIN);
return;
}
auto m = op->get_req<MOSDScrubReserve>();
switch (m->type) {
case MOSDScrubReserve::REQUEST:
m_scrubber->handle_scrub_reserve_request(op);
break;
case MOSDScrubReserve::GRANT:
m_scrubber->handle_scrub_reserve_grant(op, m->from);
break;
case MOSDScrubReserve::REJECT:
m_scrubber->handle_scrub_reserve_reject(op, m->from);
break;
case MOSDScrubReserve::RELEASE:
m_scrubber->handle_scrub_reserve_release(op);
break;
}
}
break;
case MSG_OSD_REP_SCRUB:
replica_scrub(op, handle);
break;
case MSG_OSD_REP_SCRUBMAP:
do_replica_scrub_map(op);
break;
case MSG_OSD_PG_UPDATE_LOG_MISSING:
do_update_log_missing(op);
break;
case MSG_OSD_PG_UPDATE_LOG_MISSING_REPLY:
do_update_log_missing_reply(op);
break;
default:
ceph_abort_msg("bad message type in do_request");
}
}PrimaryLogPG::do_op(boost::intrusive_ptr &) PrimaryLogPG.cc:2413
这又是很多行的代码,400多行
该方法在执行前,PG 锁已经被获取,因此该方法是在 PG 锁的保护下执行的。但是,该方法并不会获取 osd_lock,因此在执行该方法时,osd_lock 可能被其他线程持有
检查该 OSD 操作的合法性,然后根据不同的情况来调用不同的处理方法。
检查 OSD 操作中涉及的对象名称和命名空间是否合法,以及操作是否被 blocklisted。如果存在任何问题,则会向客户端返回错误信息并退出操作。
检查 OSD 操作是否为写入操作,并对写入操作做一些限制。
检查是否存在缺失的对象、是否存在降级的对象、是否正在进行 scrub 以及是否存在已经被标记为正在进行的操作,并根据不同的情况采取相应的措施。
检查操作的对象是否存在以及当前 OSD 是否为 primary OSD。
查找对象的上下文信息,然后根据查找结果进行不同的处理。
处理对象缓存、HIT_SET、AGENT_STATE 等相关操作。
检查对象的 locator 是否一致,以及检查操作是否被阻塞。然后,创建 OpContext 对象,并检查是否需要获取读写锁。
处理错误返回值、忽略缓存标志、对象丢失、以及未找到对象等情况。
执行 OpContext 对象中封装的操作。
记录操作准备阶段的延迟时间,并根据操作类型更新不同的日志计数器
最后调用 maybe_force_recovery 函数以确保最旧的缺失对象能够及时恢复
PrimaryLogPG::do_op(boost::intrusive_ptr &) PrimaryLogPG.cc:2413
重置 OpContext 对象中的 obs 信息,并准备执行下一个操作。
重置 OpContext 对象中的操作事务,并设置 OpContext 对象中的 snapc、version 和 mtime 等属性。
处理操作准备阶段的结果,并根据操作类型生成 MOSDOpReply 响应消息。
注册 OpContext 对象在提交时执行的回调函数。回调函数用于记录操作的统计信息和发送 MOSDOpReply 响应消息。
注册 OpContext 对象在操作成功时执行的回调函数和完成时执行的回调函数。
生成副本写操作并发起副本写操作,以将写入操作同步到 OSD 副本。
PrimaryLogPG::execute_ctx(PrimaryLogPG::OpContext *) PrimaryLogPG.cc:4209
发起副本写操作,以将写入操作同步到 OSD 副本。
void PrimaryLogPG::issue_repop(RepGather *repop, OpContext *ctx)
{
FUNCTRACE(cct);
const hobject_t& soid = ctx->obs->oi.soid;
repop->v = ctx->at_version;
ctx->op_t->add_obc(ctx->obc);
if (ctx->clone_obc) {
ctx->op_t->add_obc(ctx->clone_obc);
}
if (ctx->head_obc) {
ctx->op_t->add_obc(ctx->head_obc);
}
Context *on_all_commit = new C_OSD_RepopCommit(this, repop);
if (!(ctx->log.empty())) {
ceph_assert(ctx->at_version >= projected_last_update);
projected_last_update = ctx->at_version;
}
for (auto &&entry: ctx->log) {
projected_log.add(entry);
}
recovery_state.pre_submit_op(
soid,
ctx->log,
ctx->at_version);
pgbackend->submit_transaction(
soid,
ctx->delta_stats,
ctx->at_version,
std::move(ctx->op_t),
recovery_state.get_pg_trim_to(),
recovery_state.get_min_last_complete_ondisk(),
std::move(ctx->log),
ctx->updated_hset_history,
on_all_commit,
repop->rep_tid,
ctx->reqid,
ctx->op);
}首先,获取对象的标识符 soid,并设置副本写操作的版本号 repop->v 为 OpContext 对象的 at_version。接着,将 OpContext 对象中的对象上下文 (obc) 添加到当前操作的事务 op_t 中。同时,如果存在克隆对象上下文或头对象上下文,则也将其添加到 op_t 中。
然后,创建一个 C_OSD_RepopCommit 回调函数对象 on_all_commit,用于在所有 OSD 副本写操作提交完成后执行。如果 OpContext 对象中存在更新,则将其添加到 projected_log 中,并更新 projected_last_update 的值。接着,调用 pgbackend->submit_transaction 函数提交副本写操作。该函数会根据 OSD 副本状态的不同选择不同的同步方式,例如同步写、异步写、无条件写等。
最后,副本写操作提交完成后,会调用 on_all_commit 回调函数对象执行。该回调函数对象会在所有 OSD 副本写操作提交完成后执行,并将 RepGather 对象传递给 C_OSD_RepopCommit 对象以进行后续处理。
总的来说,这段代码用于发起副本写操作,以将写入操作同步到 OSD 副本。这些操作都是异步执行的,可以通过回调函数的方式来处理。
上面代码中的submit_transaction有两个实现
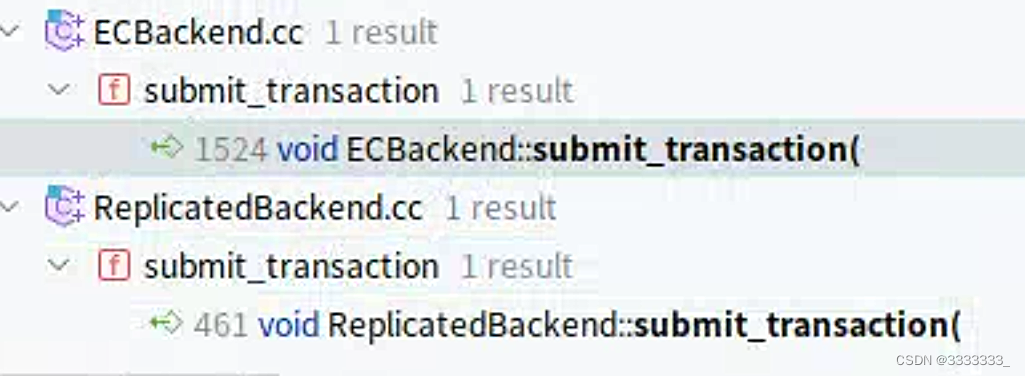
本次是进入ReplicatedBackend.cc
ReplicatedBackend::submit_transaction(const hobject_t &, const object_stat_sum_t &, const eversion_t &, std::unique_ptr &&, const eversion_t &, const eversion_t &, std::vector &&, std::optional &, Context *, unsigned long, osd_reqid_t, boost::intrusive_ptr) ReplicatedBackend.cc:545
将一个事务提交到对象存储后端,发起操作并将操作添加到 in_progress_ops 集合中进行跟踪。
parent->apply_stats 函数将对象的状态变化应用到对象的集合中。
生成一个 ObjectStore::Transaction 事务对象,并将其中添加或删除的对象添加到 added 和 removed 集合中。
generate_transaction 函数的作用是将 PGTransaction 对象 t 中的操作转换为 ObjectStore::Transaction 事务对象中的操作。具体来说,该函数会遍历 t 中的每个操作,例如写入、删除、修改等操作,然后将其转换为 ObjectStore::Transaction 事务对象中的操作,并将其中添加或删除的对象添加到 added 和 removed 集合中。在生成事务对象时,该函数还会检查操作的版本号,以便在需要时进行回滚。
将操作添加到 in_progress_ops 集合中进行跟踪。in_progress_ops 集合用于跟踪正在进行中的操作,以便在操作完成后进行回调。
将操作添加到 waiting_for_commit 集合中进行跟踪,waiting_for_commit 集合用于跟踪正在等待提交的操作,以便在操作提交完成后进行回调。
issue_op(
soid,
at_version,
tid,
reqid,
trim_to,
min_last_complete_ondisk,
added.size() ? *(added.begin()) : hobject_t(),
removed.size() ? *(removed.begin()) : hobject_t(),
log_entries,
hset_history,
&op,
op_t);
用于发起一个操作,并在 op_t 事务对象上注册一个回调函数,以在事务提交完成后执行。在 PG 日志中记录操作
将操作提交到 OSD 操作队列中进行异步执行
使用 op_t.register_on_commit 函数在 op_t 事务对象上注册一个回调函数。该回调函数将在事务提交完成后执行,并调用 C_OSD_OnOpCommit 类中的回调函数 finish_op,以通知操作已经完成。
接着,将 op_t 事务对象移动到一个 vector 对象 tls 中,并调用 parent->queue_transactions 函数将其添加到 OSD 操作队列中进行异步执行。该函数用于将一个或多个事务对象添加到 OSD 操作队列中进行异步执行
PrimaryLogPG::queue_transactions(std::vector &, boost::intrusive_ptr) PrimaryLogPG.h:349
void queue_transactions(std::vector<ObjectStore::Transaction>& tls,
OpRequestRef op) override {
osd->store->queue_transactions(ch, tls, op, NULL);
}
有4个实现,这里是进入BlueStore
BlueStore::queue_transactions(boost::intrusive_ptr &, std::vector &, boost::intrusive_ptr, ThreadPool::TPHandle *) BlueStore.cc:13068
int BlueStore::queue_transactions(
CollectionHandle& ch,
vector<Transaction>& tls,
TrackedOpRef op,
ThreadPool::TPHandle *handle)
{
list<Context *> on_applied, on_commit, on_applied_sync;
收集操作的回调函数列表,并将其保存到
on_applied、on_commit 和 on_applied_sync 三个列表中。
这些列表用于保存在操作应用、操作提交和操作应用同步完成时需要执行的回调函数。
ObjectStore::Transaction::collect_contexts(
tls, &on_applied, &on_commit, &on_applied_sync);
auto start = mono_clock::now();
获取一个对象集合的操作序列器
对象集合是对象的容器,用于管理对象的存储和访问。每个对象集合都有一个操作序列器,用于协调对该对象集合的并发访问
Collection *c = static_cast<Collection*>(ch.get());
OpSequencer *osr = c->osr.get();
创建一个事务上下文对象,并将操作添加到该事务中进行提交。
// prepare
创建一个事务上下文对象txc,并将对象集合和操作序列器作为参数传递
TransContext *txc = _txc_create(static_cast<Collection*>(ch.get()), osr,
&on_commit, op);
if (bdev->is_smr()) {//如果存储设备是SMR设备
SMR是一种特殊的磁盘存储技术,全称是“Shingled Magnetic Recording”,中文名为“重叠磁纹记录技术”。
SMR技术通过重叠磁道的方式,将磁道之间的空隙缩小,从而提高了磁盘的存储密度。相比传统的磁盘存储技术,
SMR技术可以提供更高的存储容量和更低的成本。
atomic_alloc_and_submit_lock.lock();//SMR 设备需要在写入数据之前先锁定存储设备的一些区域,并在完成所有写入之后释放这些区域。
}
遍历 tls 列表中的所有事务对象,并将它们添加到 txc 事务上下文对象中进行提交
for (vector<Transaction>::iterator p = tls.begin(); p != tls.end(); ++p) {
txc->bytes += (*p).get_num_bytes();
_txc_add_transaction(txc, &(*p));
}
_txc_calc_cost(txc);计算事务的成本
_txc_write_nodes(txc, txc->t);将事务中的所有操作写入到对象存储后端中,并在写入完成后执行回调函数
// journal deferred items
将事务中的延迟写入项写入到对象存储后端中
if (txc->deferred_txn) {检查事务中是否有延迟写入项
txc->deferred_txn->seq = ++deferred_seq;
bufferlist bl;
encode(*txc->deferred_txn, bl);序列化为二进制数据
string key;
get_deferred_key(txc->deferred_txn->seq, &key);
txc->t->set(PREFIX_DEFERRED, key, bl);并将其写入到对象存储后端中
}
_txc_finalize_kv(txc, txc->t);将所有的键值对写入到对象存储后端中。
if (handle)
handle->suspend_tp_timeout();
auto tstart = mono_clock::now();
if (!throttle.try_start_transaction(
*db,
*txc,
tstart)) {进行限流控制
// ensure we do not block here because of deferred writes
++deferred_aggressive;如果限流控制失败,则将计数器加 1
deferred_try_submit();尝试提交延迟写入项
{
// wake up any previously finished deferred events
std::lock_guard l(kv_lock);
if (!kv_sync_in_progress) {
kv_sync_in_progress = true;//设置为true,以便在后续的操作中跟踪写入操作的进度。
kv_cond.notify_one();
}
}
throttle.finish_start_transaction(*db, *txc, tstart);完成事务的启动
--deferred_aggressive;
}
执行事务并完成提交操作。
auto tend = mono_clock::now();获取当前时间
if (handle)如果有超时处理句柄
handle->reset_tp_timeout();重置超时处理计时器
// execute (start)
_txc_state_proc(txc);执行事务,并启动提交操作,在执行事务时,会根据操作的类型选择不同的执行路径。
对于写操作,会将数据写入对象存储后端中;对于删除操作,则会从对象存储后端中删除数据。
if (bdev->is_smr()) {
atomic_alloc_and_submit_lock.unlock();如果存储设备是SMR设备,它在写入数据完成之后需要释放该锁。
},
// we're immediately readable (unlike FileStore)
将所有同步回调函数on_applied_sync中的回调函数设置为完成状态,并将所有异步回调函数on_applied 添加到提交队列中
for (auto c : on_applied_sync) {
c->complete(0);
}
if (!on_applied.empty()) {
if (c->commit_queue) {如果对象集合的提交队列不为空
c->commit_queue->queue(on_applied);将异步回调函数添加到该队列中
} else {
finisher.queue(on_applied);将异步回调函数添加到finisher 对象的队列中。
}
}
。。。。。。。
return 0;
}















 3610
3610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









