








在开始讲述scrub和repair之前仍然以一些问题作为引子。也是因为以下真实的问题才促使去了解ceph的scrub和repair。

一、问题的由来
?
Q1:Scrub是什么?为什么要用scrub?
Q2:scrub在哪里触发,以什么为单位,在哪个副本上运行?如果是三副本,三个都运行吗?
Q3:scrub比对哪些文件内容?
Q4:Light scrub和deep scrub的区别?
Q5:如果主osd上的副本损坏,怎么修复,是拉取其他副本吗?具体拉取哪一个?
Q6:如果从osd上的副本损坏,是否直接拉取主osd上的副本?
Q7:Light scrub一天做一次,如果当天的没有完成怎么办?第二天会继续吗?
Q8:如果设置一天内1点到5点做scrub,Deep scrub如果一周之内还没有做完,超过5点之后会继续做吗?
Q9:Scrub影响数据的读写吗?是否设置相关的锁机制?怎么锁?锁整个pg,还是锁osd?
二、Scrub机制
关于scrub调用关系,见下图。

图1
Scrub的触发分为手动触发和默认的自动触发。自动触发如上图1,在osd启动(init)时就会调用。上述是scrub的整个流程的函数调用逻辑,如果对其感兴趣的话,可以继续往下看哦,如果只是相对其流程有个简单的了解的话,上述流程图已经够用了。以下会花大多篇幅讲述手动触发scrub。scrub处理流程中是以PG为单位,在每个PG上的主osd进行。回答了Q2.
一个pg对应一个scrubmap,类似于元数据信息摘要的数据结构。包括 object size, attr 和omap attr, 历史版本信息。Scrub的对比就是从scrubmap结构开始,下面给出scrubmap的结构示意图。本文假设副本数为3,纠删码暂不做讨论,下图中pg对应的osd为[0,3,10]
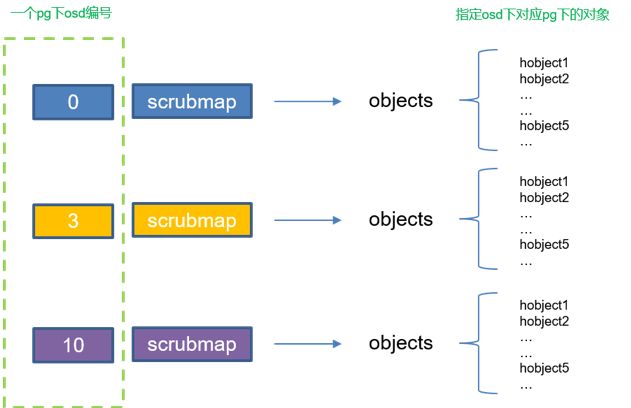
图2
1.1获取scrub任务队列
1.1.1 手动触发scrub
手动触发scrub需要发送相应的消息,同时osd需要接受对应的消息。这里是把需要处理的scrub信息加入到处理队列中(自动的osd scrub也需要加入队列中)。等待osd scrub进程进行处理获取。对于scrub的消息处理主要分为mon的消息发送,以及osd的消息处理。以下会简述两个过程。
1.1.2 Mon消息发送
1) 手动输入ceph osd scrub [osd序号],那么OSDMonitor::preprocess_query会进行消息发送
2) 对于mon过来的命令,调用preprocess_command进行处理,继续调用try_send_message发送scrub处理消息。
1.1.3 Osd消息处理
Osd接受mon发过来的scrub消息。
1) OSD::ms_dispatch接收mon发来的消息进行处理
1. bool OSD::ms_dispatch(Message *m)//接收消息
2. {
3. …
4. osd_lock.Lock();//osd加锁
5. if (is_stopping()) {
6. osd_lock.Unlock();
7. m->put();
8. return true;
9. }
10. do_waiters();
11. _dispatch(m);//任务处理的入口函数
12. osd_lock.Unlock();//osd解锁
13. return true;
14.}
Line4任务处理期间osd会进行加锁,line12任务处理完成会对osd解锁。
2)调用OSD::_dispatch根据消息类型(MSG_OSD_SCRUB)调用handle_scrub处理scrub任务。
3) OSD::handle_scrub处理scrub,列出主要代码逻辑。
1. void OSD::handle_scrub(MOSDScrub *m)
2. {
3. …
4. for (auto pgid : spgs) {//对于每个pg,入队发送scrub请求
5. enqueue_peering_evt(
6. pgid,
7. PGPeeringEventRef(
8. std::make_shared(
9. get_osdmap_epoch(),
10. get_osdmap_epoch(),
11. PG::RequestScrub(m->deep, m->repair))));
12. }
13.
14. m->put();
15.}
在handle_scrub中可以看出来,针对每个pg,调用enqueue_peering_evt将scrub任务以一个事件的形式入队列进行scrub处理。从上述代码可以看出scrub的处理时以pg为单位的。查看pgid的数据结构。
1. struct spg_t {
pg_t pgid;//pg id
shard_id_t shard;// osd在osd 列表中的序号
…
}1.1.3.1 Scrub任务同步事件入队
OSD::enqueue_peering_evt将scrub任务放入执行的工作队列op_shardedwq。
1. void OSD::enqueue_peering_evt(spg_t pgid, PGPeeringEventRef evt)
2. {
3. dout(15) <" " <" " <get_desc() <
4. op_shardedwq.queue(
5. OpQueueItem(
6. unique_ptr<:opqueueable>(new PGPeeringItem(pgid, evt)),
7. 10,
8. cct->_conf->osd_peering_op_priority,
9. utime_t(),
10. 0,
11. evt->get_epoch_sent()));
12.}
1.1.3.2 PG的同步进程处理队列事件
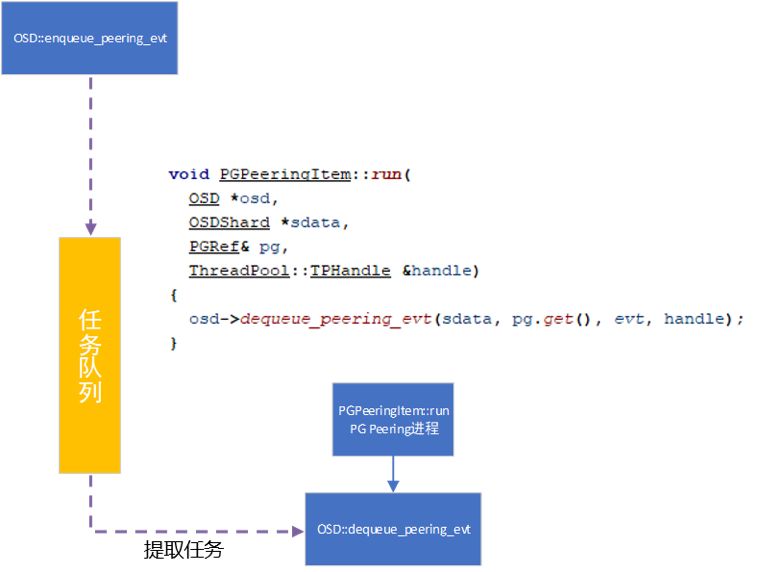
图3
1) 图3中PGPeering是一个进程,来处理osd上积压的同步时间。
2) OSD::dequeue_peering_evt采用 Ceph的状态机调用dispatch_context_transaction实现状态变化,根据handle_scrub中找到进入队列的scrub请求,最后找到对应的react。
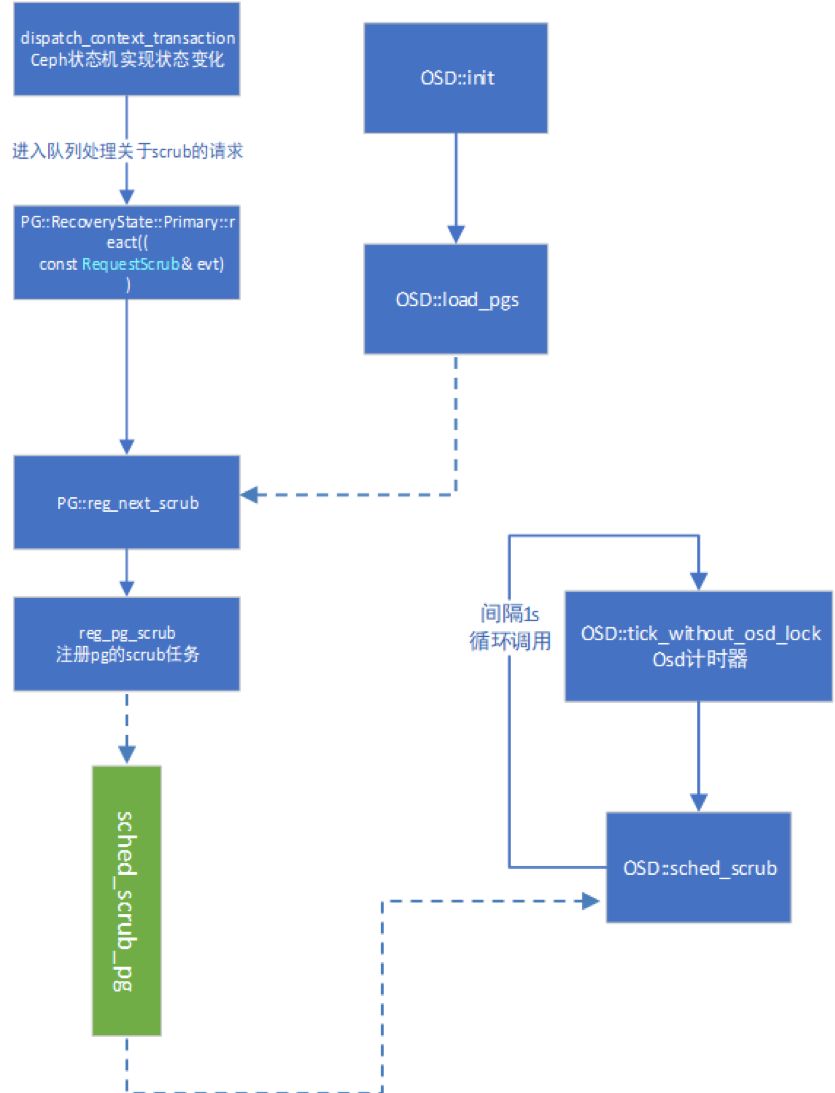
图4
3) PG::RecoveryState::Primary::react调用PG::reg_next_scrub。
1. void PG::reg_next_scrub()
2. {
3. if (!is_primary())
4. return;
5. utime_t reg_stamp;//时间戳
6. bool must = false;
7. …
8. scrubber.scrub_reg_stamp = osd->reg_pg_scrub(info.pgid,
9. reg_stamp,
10. scrub_min_interval,
11. scrub_max_interval,
12. must);//注册scrub任务,并带入时间戳,返回sched_time
13.}
调用reg_pg_scrub注册需要scrub的pg。这里读入scrub的两个时间间隔的配置:"osd_scrub_min_interval"(scrub最小间隔时间)和"osd_scrub_max_interval"(scrub最大间隔时间)。一般环境前者为86400s(24h)当ceph集群的负载比较低,执行scrub的最小时间间隔;后者为604800s(7day)执行scrub的最大时间间隔,无视负载。同时在注册scrub任务时,会带入时间戳,返回sched_time。
4) reg_pg_scrub注册pg的scrub任务。对ScrubJob进行实例化,传入时间戳t。
1. utime_t reg_pg_scrub(spg_t pgid, utime_t t, double pool_scrub_min_interval,
2. double pool_scrub_max_interval, bool must) {
3. ScrubJob scrub(cct, pgid, t, pool_scrub_min_interval, pool_scrub_max_interval,
4. must);
5. Mutex::Locker l(sched_scrub_lock);
6. sched_scrub_pg.insert(scrub);
7. return scrub.sched_time;
8. }
将需要scrub的pg加入到sched_scrub_pg中,后续从sched_scrub_pg中获取scrub进行scrub。相当于把所有需要的scrub任务都插入到变量sched_scrub_pg中,等待处理。
查看scrubjob的构造函数。
OSDService::ScrubJob::ScrubJob(…)
: cct(cct),
pgid(pg),
sched_time(timestamp),
deadline(timestamp)
{
…
sched_time += scrub_min_interval;
double r = rand() / (double)RAND_MAX;//[0,1]随机数
sched_time +=
scrub_min_interval * cct->_conf->osd_scrub_interval_randomize_ratio * r;// sched_time(传进来的时间戳)+[1.1.5]*scrub_min_interval的随机数
if (scrub_max_interval == 0) {
deadline = utime_t();
} else {
deadline += scrub_max_interval;
}
}
}上述构造函数中涉及到ceph.conf中的几个配置,作下说明:
"osd_scrub_min_interval":"86400" //24h;
"osd_scrub_max_interval":"604800" //7day。
对应到函数中是变量scrub_min_interval和scrub_max_interval。
sched_time = timestamp(生成scrubjob的时间) +scrub_min_interval + scrub_min_interval *cct->_conf->osd_scrub_interval_randomize_ratio * r;// sched_time(传进来的时间戳)+[1.1.5]*scrub_min_interval的随机数
简单的说:
1) 轮到执行scrub的时间,即两次scrubjob间隔至少过这么多时间。
sched_time = rand[timestamp + scrub_min_interval,timestamp + scrub_min_interval*1.5]之间的随机数,一般scrub_min_interval取值为1天。
2) 一个scrub最长的周期,即两次scrubjob间隔最多过这么多时间。
deadline = timestamp(生成scrubjob的时间) + scrub_max_interval,一般scrub_max_interval取值为7天。
1.2 Scrub处理任务队列
1.2.1进入scrub任务队列
Ceph调用计时器触发scrub任务,进入任务队列。
1. void OSD::tick_without_osd_lock()
2. {
3. …
4. if (is_active()) {
5. if (!scrub_random_backoff()) {
6. sched_scrub();
7. }
8. …
9. }
10.
11. mgrc.update_daemon_health(get_health_metrics());
12. service.kick_recovery_queue();
13. tick_timer_without_osd_lock.add_event_after(OSD_TICK_INTERVAL, new C_Tick_WithoutOSDLock(this));//OSD_TICK_INTERVAL=1s,之后再次调用该函数
14.}
Line13过OSD_TICK_INTERVAL之后再次调用自身。这个函数循环调用OSD::sched_scrub。
1.2.1.1 OSD::sched_scrub按照计划处理scrub。
1. void OSD::sched_scrub()
2. {
3. …
4.
5. utime_t now = ceph_clock_now();
6. bool time_permit = scrub_time_permit(now);//进行判断日常scrub是否在1点和5点之间
7. bool load_is_low = scrub_load_below_threshold();//cpu是否低于负载阈值,低于说明可以调度scrub
8. dout(20) <"sched_scrub load_is_low=" <int)load_is_low <
9.
10. OSDService::ScrubJob scrub;
11. if (service.first_scrub_stamp(&scrub)) {//从sched_scrub_pg队列中获取pg用于scrub
12. do {
13. dout(30) <"sched_scrub examine " <" at " <
14.
15. if (scrub.sched_time > now) {
16. // save ourselves some effort
17. dout(10) <"sched_scrub " <" scheduled at " <
18. <" > " <
19. break;
20. }
21.//一般不会进下面条件,如果一个scrub在一个周期内没结束,即现在时间超过scrub计划时间:scrub.deadline ,在非scrub时间,time_permit=false,也不会进入下面判断。所以会继续调用pg->sched_scrub
22. if ((scrub.deadline.is_zero() || scrub.deadline >= now) && !(time_permit && load_is_low)) {
23. dout(10) <" not scheduling scrub for " <" due to "
24. <"time not permit" : "high load") <
25. continue;
26. }
27.
28. PGRef pg = _lookup_lock_pg(scrub.pgid);//pg加锁
29. if (!pg)
30. continue;
31. dout(10) <"sched_scrub scrubbing " <" at " <
32. <get_must_scrub() ? ", explicitly requested" :
33. (load_is_low ? ", load_is_low" : " deadline ))
34. <
35. if (pg->sched_scrub()) {//调用PG::sched_scrub,如果返回true就退出循环
36. pg->unlock();//成功将pg送入scrub_wq后,释放锁,线程从队列获取pg,开始做scrub的时候会继续拿锁
37. break; //一次调度一个pg做scrub,下一次time继续调度
38. }
39. pg->unlock();
40. } while (service.next_scrub_stamp(scrub, &scrub));//查找当前结束的scrub的后一个作为新的scrub,,排在前面的pg可能状态不是active,所以这里继续循环寻找下一个pg
41. }
42. dout(20) <"sched_scrub done" <
43.}
上述代码主要传递了如下信息,特别是对于何时开始scrub,何时停止scrub进行了说明。主要分为两方面:一是时间段是否允许;二是物理机系统负载是否符合要求。
a) 如果对line6osd scrub开始时间和结束时间进行如下配置:
"osd_scrub_begin_hour": "1",
"osd_scrub_end_hour": "5"。那么调用scrub_time_permit来检查现在是否在1点到5点之间。
b) 上述代码line7用scrub_load_below_threshold来查看cpu的负载。如下:
1. bool OSD::scrub_load_below_threshold()
2. {
3. double loadavgs[3];
4. if (getloadavg(loadavgs, 3) != 3) {//获取系统平均负载的个数,系统规定所能获取的样本数目最多为3个,分别是1分钟,5分钟,15分钟的平均负载。
5. dout(10) <" couldn't read loadavgs\n" <
6. return false;
7. }
8.
9. // allow scrub if below configured threshold
10. long cpus = sysconf(_SC_NPROCESSORS_ONLN);//系统当前可用的核数
11. double loadavg_per_cpu = cpus > 0 ? loadavgs[0] / cpus : loadavgs[0];//每个cpu的负载
12. if (loadavg_per_cpu _conf->osd_scrub_load_threshold) {//当cpu的负载超过阈值,默认是50%,不再调度scrub
13.…
14. return true;
15. }
16.
17. // allow scrub if below daily avg and currently decreasing
18. if (loadavgs[0] //如果超过50%,并且满足这个条件(cpu一分钟的负载,低于日常负载,也低于15分钟内负载,说明在降级),也可以scrub
19.…
20. return true;
21. }
22.…
23. return false;
24.}
上述调用系统函数getloadavg来获取系统负载。
c) Line35中调用pg->sched_scrub进行处理,如果scrub被启动,返回true。由于由定时服务启动,所以队列里面任务可以执行结束。
d) 如果deep scrub在一个周期(7day)内没结束,表示现在时间超过scrub的计划时间(scrub.deadline < now),在非scrub时间(time_permit=false)不会进入代码中的判断语句line22,会继续调用pg->sched_scrub,直到把sched_scrub_pg执行完。这个原理也就解释了为什么线上会看到白天还在做deep scrub,因为数据太多了。回答了Q8.
e) 如果light scrub在一个周期(24h)内没有结束(scrub.deadline >=now),在非scrub时间time_permit=false),会进入判断line22,停止执行。等待下个周期(第二天),接着执行。当然,在规定时间到达后,不会立即退出,会把正在执行scrub的任务执行完。回答了Q7。
1.2.1.2 PG::sched_scrub
1. // 如果scrub已经被启动了,就返回true
2. bool PG::sched_scrub()
3. {
4. bool nodeep_scrub = false;
5. assert(is_locked());//pg需要被锁住
6. if (!(is_primary() && is_active() && is_clean() && !is_scrubbing())) {
7. return false; //不是主osd,或者pg没有active,或者pg不是clean,或者pg已经在做scrub,直接退出
8. }
9.
10. double deep_scrub_interval = 0;
11. pool.info.opts.get(pool_opts_t::DEEP_SCRUB_INTERVAL, &deep_scrub_interval);//7天
12. if (deep_scrub_interval <= 0) {
13. deep_scrub_interval = cct->_conf->osd_deep_scrub_interval;//7天
14. }
15. bool time_for_deep = ceph_clock_now() >=
16. info.history.last_deep_scrub_stamp + deep_scrub_interval;//现在的时间点大于deep的一个周期,表示轮到deep
17.
18. bool deep_coin_flip = false;
19. // Only add random deep scrubs when NOT user initiated scrub
20. if (!scrubber.must_scrub)
21. deep_coin_flip = (rand() % 100) _conf->osd_deep_scrub_randomize_ratio * 100;//15%随机触发deep scrub概率
22. dout(20) <": time_for_deep=" <" deep_coin_flip=" <
23.
24. time_for_deep = (time_for_deep || deep_coin_flip);
25.
26. //NODEEP_SCRUB so ignore time initiated deep-scrub
27. if (osd->osd->get_osdmap()->test_flag(CEPH_OSDMAP_NODEEP_SCRUB) ||
28. pool.info.has_flag(pg_pool_t::FLAG_NODEEP_SCRUB)) {
29. time_for_deep = false;
30. nodeep_scrub = true;
31. }//是否设置了no deep scrub,设置了就不做deep
32.…
33. bool ret = true;
34. if (!scrubber.reserved) {//将pg本身加入peers,并且向副本发送scrub消息,让副本预留slot
35..第一次调用,reserve为false
36. assert(scrubber.reserved_peers.empty());//peers也为空集合
37. if ((cct->_conf->osd_scrub_during_recovery || !osd->is_recovery_active()) &&
38. osd->inc_scrubs_pending()) {//为自己预留slot
39. dout(20) <": reserved locally, reserving replicas" <
40. scrubber.reserved = true;
41. scrubber.reserved_peers.insert(pg_whoami); //将pg本身加入peers集合,一起计数
42. scrub_reserve_replicas();//发送消息让副本预留slot
43. } else {
44. dout(20) <": failed to reserve locally" <
45. ret = false;
46. }
47. }
48. if (scrubber.reserved) {//检查slot信息
49. if (scrubber.reserve_failed) {// 还没收到副本的消息,或者副本预留成功,reserve_failed为false
50. dout(20) <"sched_scrub: failed, a peer declined" <
51. clear_scrub_reserved();
52. scrub_unreserve_replicas();
53. ret = false;
54. } else if (scrubber.reserved_peers.size() == acting.size()) {//预留的副本数,和osd正常的副本数一致,判断是否所有副本都预留成功了
55. dout(20) <"sched_scrub: success, reserved self and replicas" <
56. if (time_for_deep) {
57. dout(10) <"sched_scrub: scrub will be deep" <
58. state_set(PG_STATE_DEEP_SCRUB); //如果到达一个deep scrub的执行周期,则pg状态会设置成deep
59. } else if (!scrubber.must_deep_scrub && info.stats.stats.sum.num_deep_scrub_errors) {
60. …
61. }
62. queue_scrub();//调度scrub
63. } else {//等待副本的消息
64. // none declined, since scrubber.reserved is set
65. dout(20) <"sched_scrub: reserved " <", waiting for replicas" <
66. }
67. }
68.
69. return ret;
70.}
Line18deep_coin_flip表示触发deep scrub的概率,有15%的可能性将普通scrub转为deep scrub;
Line16time_for_deep一般为true,现在的时间点大于deep的一个周期,表示轮到deep。Scrub的预留的副本数与副本数一致会执行queue_scrub()。
a) 上述第一个判断line7说明了要在主osd上才能执行scrub。
b)这个函数会申请scrub slot line38,只有当所有副本均申请成功后line54, 才会排队进行scrub, 所以对于同一个pg,一般情况下会有两次tick周期调度到这里(两个if),才会真正进行queue_scrub。
正常情况下,如果副本也预留slot成功,就会执行函数queue_scrub再调用OSDService::queue_for_scrub,它的操作就是将pg放入scrub_wq队列,并且设置较高处理的优先级。最后调用OSDService::queue_for_scrub进入PGScrub任务队列。如下图:
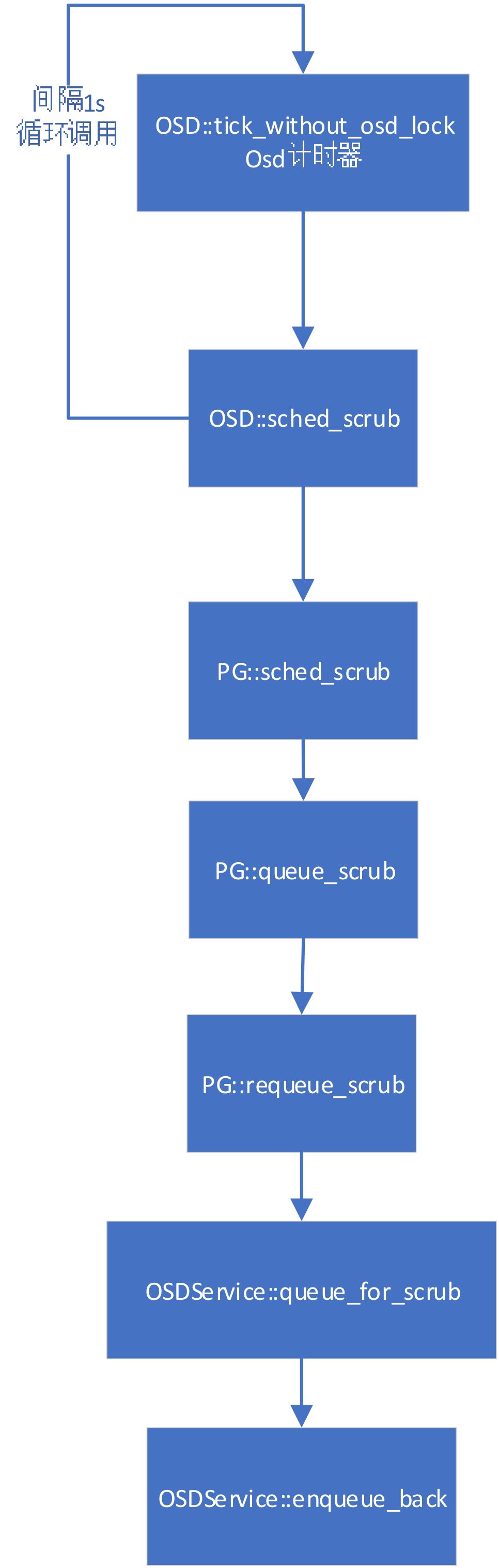
图5
1.2.2 获取队列进行scrub处理
PGScrub进程在跑,获取队列信息,PGScrub::run调用pg->scrub。
1. void PG::scrub(epoch_t queued, ThreadPool::TPHandle &handle)
2. {
3. …
4. // for the replica
5. if (!is_primary() &&
6. scrubber.state == PG::Scrubber::BUILD_MAP_REPLICA) {
7. chunky_scrub(handle); //非主副本调用chunky_scrub
8. return;
9. }
10. …
11.
12. chunky_scrub(handle);
13.}
上述函数有两处调用了chunky_scrub。Line7处是如果从副本scrub的状态为Scrubber::BUILD_MAP_REPLICA,会调用chunky_scrub。并进行对应的状态机处理。主副本scrub会调用line12处。
其实ceph在出现chunky_scrub之前,用的是classic scrub。chunky_scrub针对原来的scrub做了一些改进。比如,chunky_scrub每次都是对pg中某一范围内的对象做scrub处理,这样之后这些部分对象会被锁住,相比于原来的机制来说pg内对象锁的粒度变小了,这样提升了IO性能。
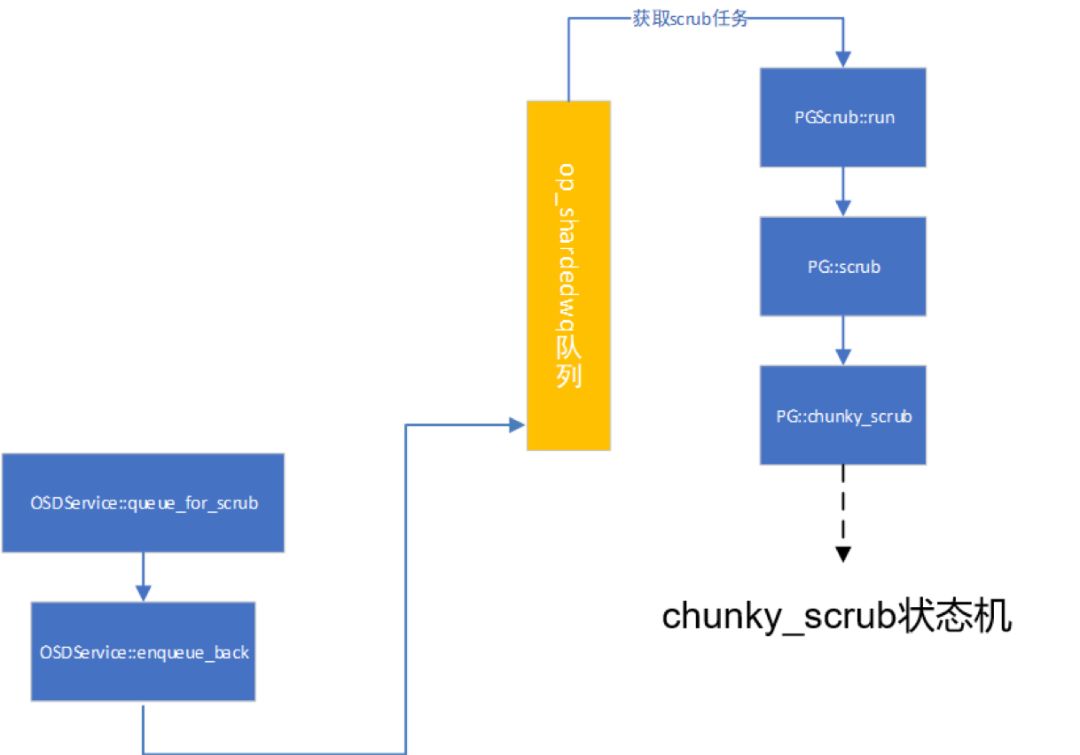
图6
未完待续
往期精选
【干货分享】| 基于智能网卡(Smart Nic)的Open vSwitch卸载方案简介
【干货分享】| OVN的负载均衡器功能介绍
















 6144
6144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









