







阅读收益预览
1、你将会了解到源码跟进的过程;
2、你将会看到问题分析的思路;
3、你可以解决 Requests 库关于编码猜测不准确的问题;
内容介绍
这一篇我们来观摩 Python 中的 Requests、Scrapy 库以及 Golang 中的 Charset 库对于网页编码的处理逻辑,并让你具备提高 Requests 库编码猜测准确性的能力。
乱码现象
近期在工程实践中发现了一个长期潜伏的网页文本乱码问题,也就是爬取网页后,打印出来的文本是乱码。如果你是 Python 工程师,你可以试试下面这段代码:
import requests
# GB2312
resp = requests.get("http://news.inewsweek.cn/society/2022-05-30/15753.shtml")
print(resp.text)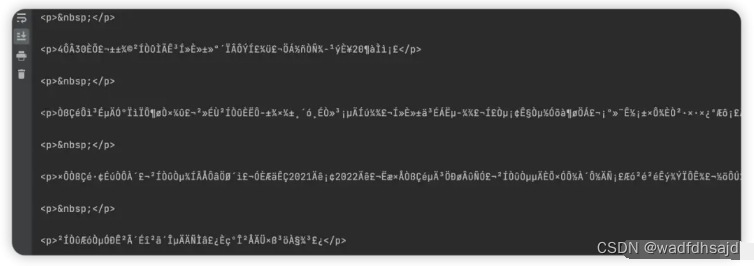
打印出来的网页文本,中文部分就是乱码,这真是令我狗头 🐶 变大。
你心里可能会有这样的疑问:“按理说,Python 的 Requests 库应该能够帮助我们自动识别编码,然后自动转换才对的”。“但事实却并不是那么回事,为什么?”
不仅仅是 Python 的 Requests 库有这样的症状,Golang 的 Charset
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 9143
9143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









