







目录
3.为什么要用flex布局,align-items和justify-content的区别
4.BFC(Block Formatting Context) 是什么?应用?
13、css3中transform、transition、animation的区别
6.javascript 代码中的"use strict";是什么意思 ? 使用它区别是什么?
9.怎么定义vue-router的动态路由?怎么获取传过来的值?
CSS面试题
1.盒模型
盒模型有标准盒模型(W3C)和IE的盒模型:
1、一个元素占有空间的大小由几个部分构成,其中包括元素的内容(content),元素的内边距(padding),内容与边框之间的距离元素的边框(border),元素的外边距(margin),边框与外部元素之间的距离四个部分,这四个部分一起构成了盒子模型。
2、区别:标准盒模型的内容大小是content的大小,而IE的则是content + padding +border 总的大小
2.如何让一个盒子水平垂直居中?
1、绝对定位,父相子绝,子元素:left:50%,top:50%,transform:translateX(-50%) translateY(-50%)
2、绝对定位,父相子绝,子元素:left:0,right:0,top:0,bottom:0,margin:auto
3、flex布局,父元素:display:flex,aligin-items:center,justify-content:center
3.为什么要用flex布局,align-items和justify-content的区别
1、传统布局基于盒模型,非常依赖 display属性 、position属性 、float属性。而flex布局更灵活,可以简便、完整、响应式地实现各种页面布局,比如水平垂直居中。
2、align-items:定义在侧轴(纵轴)方向上的对齐方式;
3、justify-content:定义在主轴(横轴)方向上的对齐方式。
4.BFC(Block Formatting Context) 是什么?应用?
1、BFC块级格式上下文,属于定位方案中的普通流。
具有BFC特性的元素可以看作是隔了的独立容器,容器里的元素不会在布局上影响到外面的元素。简单的说:可以理解BFC是要给封闭的大箱子,箱子内的元素无论如何交换,都不会影响到外面的元素。
2、触发条件:
①body根元素;
②浮动元素float的值不为none;
③绝对定位元素:positon(absolute、fixed);
④display的值为:display(block、inline-block、inltable-cell、table-caption、table、inline-table、flex、inline-flex、grid、inline-grid);
⑤overflow:除了visible以外的值;(hidden、scroll、auto);
3、应用场景:
①防止margin重叠;②清除内部浮动;③自适应多栏布局
5.请描述一下 cookies,sessionStorage 和 localStorage 的区别?
1、相同点:都会在浏览器端保存,有大小和同源限制。
2、不同点:
①cookie会随请求发送到服务器,作为会话表示,服务器可修改cookie。web storage不会随请求发送到服务器。
②cookie有path的概念,子路径可以访问父路径的cookie,父路径不可以访问子路径的cookie。
③有效期:cookie在设置的有效期内有效,默认为浏览器关闭消失。sessionStorage在会话窗口关闭后失效,localStorage长期有效,需主动删除。
④sessionStorage不能共享,localStorage在同源文档之间可以共享,cookie在同源且符合path规则的文档之间可以共享。
⑤localStorage的修改会触发其他文档的update事件。
⑥cooie有secure属性要求HTTPS传输。
⑦浏览器不能保存超过300个cookie,单个服务器不能超过20个,每个cookie不能超过4k。webStorage可以支持5M的存储。
6.px和em,rem的区别
1、em的值并不是固定的;em会继承父级元素的字体大小。
2、任意浏览器的默认字体高都是16px。所有未经调整的浏览器都符合: 1em=16px。那么12px=0.75em,10px=0.625em。为了简化font-size的换算,需要在css中的body选择器中声明Font-size=62.5%,这就使em值变为 16px*62.5%=10px, 这样12px=1.2em, 10px=1em, 也就是说只需要将你的原来的px数值除以10,然后换上em作为单位就行了
3、使用rem为元素设定字体大小时,仍然是相对大小,但相对的只是HTML根元素。这个单位可谓集相对大小和绝对大小的优点于一身,通过它既可以做到只修改根元素就成比例地调整所有字体大小,又可以避免字体大小逐层复合的连锁反应。目前,除了IE8及更早版本外,所有浏览器均已支持rem。对于不支持它的浏览器,应对方法也很简单,就是多写一个绝对单位的声明。这些浏览器会忽略用rem设定的字体大小。
7.解释下浮动和它的工作原理,清除浮动的方法?
1、浮动(float)也是大家平常在网页开发中经常使用的属性,(主要是为了让一些标签并排显示)
2、浮动元素脱离文档流,不占据空间。浮动元素碰到包含它的边框或者浮动元素的边框停留。
3、使用空标签清除浮动。给包含浮动元素的父标签添加overflow属性。使用after伪对象清除浮动(该方法只适用于非IE浏览器。使用中需注意以下几点。一、该方法中必须为需要清除浮动元素的伪对象中设置 height:0,否则该元素会比实际高出若干像素;)。
8.如何实现浏览器内多个标签页之间的通信?
1、使用本地存储器localStorage
使用localStorage.setItem(key,value);添加内容
使用storage事件监听添加、修改、删除的动作
2、使用cookie+setInterval
9.CSS隐藏元素的几种方法
1、opacity:0; 占位
2、visibility:hidden;占位
3、display:none;不占位
4、height:0;overflow:hidden; 不占位
5、position:absolute;left:-9999px;top:-9999px.;
10.css 优先级确定
1、最近的祖先样式比其他祖先样式优先级高。
2、"直接样式"比"祖先样式"优先级高。
3、内联样式 > ID 选择器 > 类选择器 = 属性选择器 = 伪类选择器 > 标签选择器 = 伪元素选择器
4、计算选择符中 ID 选择器的个数(a),计算选择符中类选择器、属性选择器以及伪类选择器的个数之和(b),计算选择符中标签选择器和伪元素选择器的个数
之和(c)。按 a、b、c 的顺序依次比较大小,大的则优先级高,相等则比较下一个。若最后两个的选择符中 a、b、c 都相等,则按照"就近原则"来判断。
5、属性后插有 !important 的属性拥有最高优先级。若同时插有 !important,则再利用规则 3、4 判断优先级。
11.简述下CSS的元素分类
1、替换和不可替换元素
2、块级元素和行内元素
12.重绘和回流
重绘:不会影响页面布局的操作,比如更改颜色。
回流:布局的改变导致需要重新构建,就是回流。
13、css3中transform、transition、animation的区别
1、transform:描述了元素的静态样式,本身不会呈现动画效果,可以对元素进行 旋转rotate、扭曲skew、缩放scale和移动translate以及矩阵变形matrix。transition和animation两者都能实现动画效果 transform常常配合transition和animation使用
2、transition样式过渡,从一种效果逐渐改变为另一种效果
transition:transition-property transition-duration transition-timing-function transition-delay 从左到右分别是:css属性、过渡效果花费时间、速度曲线、过渡开始的延迟时间
①transform仅描述元素的静态样式,常常配合transition和animation使用。
②transition通常和hover等事件配合使用,animation是自发的,立即播放。
③animation可设置循环次数 。
④animation可设置每一帧的样式和时间,transition只能设置头尾。
⑤transition可与js配合使用,js设定要变化的样式,transition负责动画效果,如:animation属性类似于transition,他们都是随着时间改变元素的属性值,其主要区别在于:transition需要触发一个事件才会随着时间改变其CSS属性;
animation在不需要触发任何事件的情况下,也可以显式的随时间变化来改变元素CSS属性,达到一种动画的效果
1)动画不需要事件触发,过渡需要。
2)过渡只有一组(两个:开始-结束) 关键帧,动画可以设置多个。3、animation属性类似于transition,他们都是随着时间改变元素的属性值。
14.link与@import 导入 css的区别
1、link属于XHTML标签,除了加载CSS外,还能用于定义RSS, 定义rel连接属性等作用;而@import是CSS提供的,只能用于加载CSS;
2、页面被加载的时,link会同时被加载,而@import引用的CSS会等到页面被加载完再加载; import是CSS2.1 提出的,只在IE5以上才能被识别,而link是XHTML标签,无兼容问题;
JavaScript基础面试题
1.js有哪些数据类型
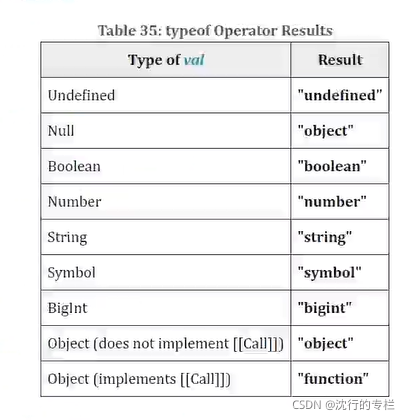
1、基本数据类型有7种:String、Number、Boolean、Undefined、Null、Symbol、Bigint
2、引用数据类型 Object(Data、Function、Array等)
2.栈和堆的区别?
①堆是应用程序在运行时候请求操作系统分配给自己的内存。
②栈中一般存放局部变量,队中一般存放创建的对象和数组。
2.Javascript实现继承的几种方式?
1、原型链继承
3.Javascript创建对象的几种方式?
//第一种:字面量(语法糖)
const user1={
name:'xiaoming'
}
//第二种:new Object()和第二种基本一样
const user2=new Object({name:'xiaoming'})
//第三种:通过构造函数
const User=function (name) {
this.name=nme;
}
const user3=new User('xiaoming')
//第四种:Object.create()
const user ={name:'xiaoming'}
const user4=Object.create(user)
//第五种:通过es6方式,也就是工厂模式(其实也是构造方式)
class User{
constructor(name){
this.name=name
this.getName = function(){
return "姓名是" + this.name
}
}
}
let user4 = new User('xiaoming')
console.log(user4)
//{name: 'xiaoming', getName: ƒ}4.Javascript作用链域
5.什么是闭包(closure),为什么要用它?
1、闭包就是能够读取其他函数内部变量的函数、定义在一个函数内部的函数。
6.javascript 代码中的"use strict";是什么意思 ? 使用它区别是什么?
将”use strict”放在脚本文件的第一行,则整个脚本都将以”严格模式”运行。
1、消除Javascript语法的一些不合理、不严谨之处,减少一些怪异行为;
2、消除代码运行的一些不安全之处,保证代码运行的安全;
3、提高编译器效率,增加运行速度;
7.深拷贝和浅拷贝
前端中的深拷贝和浅拷贝及相应注意事项_沈行的博客-CSDN博客
8.JS延迟加载的方式有哪些?
1、defer 属性
2、async 属性
3、动态创建DOM方式
4、使用jQuery的getScript方法
5、使用setTimeout延迟方法
6、让JS最后加载
9.什么是跨域问题 ,如何解决跨域问题?
1、Jsonp:网页通过动态添加一个 script 元素,向服务器请求数据; 服务器收到请求后,将数据放在一个指定名字的回调函数里传回来。但只支持get请求。
2、设置跨域资源共享(CORS),不过需要浏览器和服务器同时支持,设置4项:
①允许请求带有验证信息
②允许访问的客户端域名
③允许服务端访问的客户端请求头
④允许访问的方法名,GET POST等3、document.domain: 此方案仅限主域相同,子域不同的跨域应用场景
4、webpack配置proxyTable设置开发环境跨域
5、nginx反向代理
跨域原理: 同源策略是浏览器的安全策略,不是HTTP协议的一部分。服务器端调用HTTP接口只是使用HTTP协议,不会执行JS脚本,不需要同源策略,也就不存在跨越问题。
实现思路:通过nginx配置一个代理服务器(域名与domain1相同,端口不同)做跳板机,反向代理访问domain2接口,并且可以顺便修改cookie中domain信息,方便当前域cookie写入,实现跨域登录。6、iframe跨域
7、postMessage:这种方式通常用于获取嵌入页面中的第三方页面数据。一个页面发送消息,另一个页面判断来源并接收消息
11.DOM操作
js是由三部分组成,分别为js 的语法核心 ECMAScript,还有文档对象模型 DOM,以及浏览器对象模型 BOM。
1、创建新节点
createDocumentFragment() // 创建一个DOM片段 createElement() // 创建一个具体的元素 createTextNode() // 创建一个文本节点2、添加、移除、替换、插入
appendChild() removeChild() replaceChild() insertBefore() // 在已有的子节点前插入一个新的子节点3、查找
getElementsByTagName() // 通过标签名称 // 通过元素的Name属性的值(IE容错能力较强,会得到一个数组,其中包括id等于name值的) getElementsByName() getElementById() // 通过元素Id,唯一性
12.什么是Cookie 隔离?
或者说:请求资源的时候不要让它带cookie怎么做
1、如果静态文件都放在主域名下,那静态文件请求的时候都带有的cookie的数据提交给server的,非常浪费流量,所以不如隔离开。
2、因为cookie有域的限制,因此不能跨域提交请求,故使用非主要域名的时候,请求头中就不会带有cookie数据,这样可以降低请求头的大小,降低请求时间,从而达到降低整体请求延时的目的。
同时这种方式不会将cookie传入Web Server,也减少了Web Server对cookie的处理分析环节,提高了webserver的http请求的解析速度。
16.箭头函数和普通函数的区别
1、箭头函数相当于匿名函数,并且简化了函数定义,不能作为构造函数,不能使用new这种方式。
2、箭头函数不绑定arguments,取而代之用rest参数...解决。
3、箭头函数不绑定this,会捕获其所在的上下文的this值,作为自己的this值。
4、箭头函数通过 call() 或 apply() 方法调用一个函数时,只传入了一个参数,对 this 并没有影响。
5、箭头函数没有原型属性。
6、箭头函数不能当做Generator函数,不能使用yield关键字。
17. typeof 和 instanceof 的区别
1、typeof是用于判断数据类型,返回值为6个字符串,分别为string、boolean、number、function、object、undefined
2、typeof在判断null、array、object 以及 函数实例(new + 函数)时,得到的都是object。这使得在判断这几类数据类型时,得不到真实的数据类型。
3、instanceof中文翻译为实例,因此instanceof的含义也就不言而喻,判断该对象是谁的实例,instance是属于对象运算符。
4、instanceof判断实例牵扯到对象的继承,它的判断是根据原型链进行搜寻,在对象obj1的原型链上如果存在另一个对象obj2的原型属性,那么表达式(obj1 instanceof obj2)返回值为true,否则返回false。
Vue框架面试题
1.对于MVVM的理解?
1、模型(Model): 数据保存—存放着各种数据,有的是固定写死的,大多数是从后端返回的数据。
2、视图 (View):用户界面,也就是DOM。
3、视图模型(View-Model):连接View和Model的桥梁,当数据变化时,ViewModel够监听到数据的变化(通过Data Bindings),自动更新视图,而当用户操作视图,ViewModel也能监听到视图的变化(通过DOM Listeners),然后通知数据做改动,这就实现了数据的双向绑定。
2.Vue的生命周期
常用的主要有8个:beforeCreate、created、beforeMount、mounted、beforeUpdate、updated、beforeDestroy、destroyed
3.Vue实现数据双向绑定的原理
数据发生变化,页面会重新渲染,数据的vue响应式
1、侦测数据的变化 -----------》数据劫持/数据代理(使
Object.defineProperty和ES6的Proxy)2、收集视图看下哪些依赖于这些有变化的数据 -----------》依赖收集(watcher,在getter中收集依赖,在setter中触发依赖)
3、数据变化时,自动通知需要更新的视图部分,并进行更新 -----------》发布订阅模式(update更新视图)
4.vue路由的钩子函数
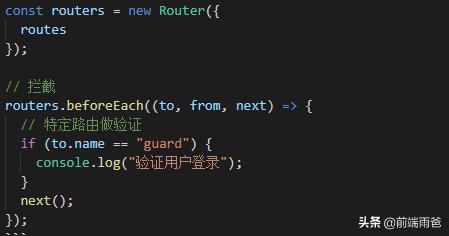
1、全局钩子:beforeEach函数有三个参数:
to:router即将进入的路由对象
from:当前导航即将离开的路由
next:Function,进行管道中的一个钩子,如果执行完了,则导航的状态就是 confirmed (确认的);否则为false,终止导航。
afterEach函数不用传next()函数
这类钩子主要作用于全局,一般用来判断权限,以及以及页面丢失时候需要执行的操作。例如//使用钩子函数对路由进行权限跳转
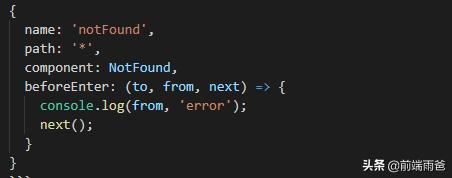
2、单个路由里面的钩子
主要用于写某个指定路由跳转时需要执行的逻辑。3、组件路由
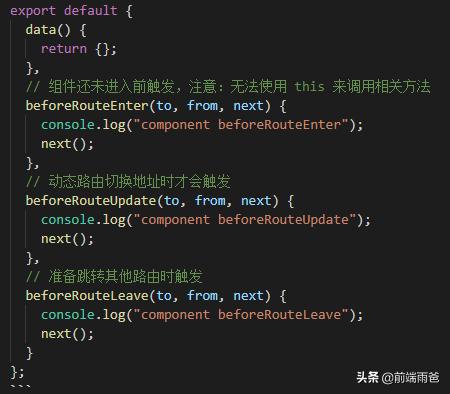
主要包括 beforeRouteEnter和beforeRouteUpdate ,beforeRouteLeave,这几个钩子都是写在组件里面也可以传三个参数(to,from,next),作用与前面类似.
5.for in和for of的区别
for in是ES5标准,遍历得到的是key,更适合遍历对象。
for of是ES6引入,遍历value,更适合遍历数组。
6.v-if 和 v-show 有什么区别?
1、v-if本质是向Dom树内添加或者删除Dom元素,v-show类似于display:none
2、如果频繁切换就用v-show,不频繁切换就用v-if
7.对于Vue是一套渐进式框架的理解(此为vue的核心)
Vue渐进式-先使用Vue的核心库,再根据你的需要的功能再去逐渐增加加相应的插件。
1、数据驱动专注于View 层。它让开发者省去了操作DOM的过程,只需要改变数据。
2、组件响应原理数据(model)改变驱动视图(view)自动更新
3、组件化扩展HTML元素,封装可重用的代码。
8.Vue 组件间通信有哪几种方式?
1、props / $emit()
2、provide / inject 祖孙组件传值,注意:传递参数为值类型(基本类型),接受参数的组件中不能进行修改,若是传递对象或者数组,可以直接进行修改,并且可以影响祖先级组件。
3、vuex
4、$parent / $children & ref
5、$emit / $on
6、$attrs / $listeners
9.怎么定义vue-router的动态路由?怎么获取传过来的值?
params刷新会消失。。。query则不会
1、params的类型(参数刷新会消失,另相当于post请求)
2、query的类型(刷新参数不会消失,另相当于get请求,参数在地址栏显示)
10.vue-router的路由模式有哪些?
vue-router 有 3 种路由模式:hash、history、abstract:
1、hash: 原理: 在 url 中的 # 之后对应的是 hash 值, 其原理是通过hashChange() 事件监听hash值的变化, 根据路由表对应的hash值来判断加载对应的路由加载对应的组件。支持所有浏览器,包括不支持 HTML5 History Api 的浏览器;
2、history : 依赖 HTML5 History API 和服务器配置。具体可以查看 HTML5 History 模式;
3、abstract : 支持所有 JavaScript 运行环境,如 Node.js 服务器端。如果发现没有浏览器的 API,路由会自动强制进入这个模式;
11.vue-router有哪几种路由守卫?
1、全局前置守卫beforeEach
2、全局后置路由守卫afterEach
3、全局解析守卫beforeResolve
4、路由独享守卫beforeEnter
5、组件内的守卫beforeRouteXXX(beforeRouteEnter)


12.vuex有哪几种属性?
1、state:vuex的基本数据,用来存储变量(后四个属性都是用来操作state里面储存的变量的)。
2、getters:是对state里面的变量进行过滤的。
3、mutation:提交更新数据的方法,必须是同步的(如果需要异步使用action)。
4、action:和mutation的功能大致相同,不同之处在于:
1.Action提交的是mutation,而不是直接变更状态。 也就是action是用来修改mutation并提交的,而mutation是通过修改state
2.Action可以包含任意异步操作。(一般比较复杂的数据都在action中操作)
3.action先会执行异步操作再去调用mutation,随后才跟新state
5、modules:项目特别复杂的时候,可以让每一个模块拥有自己的state、mutation、action、getters,使得结构非常清晰,方便管理。
13.vue中常用修饰符
1、v-model修饰符
①.lazy:
输入框改变,这个数据就会改变,lazy这个修饰符会在光标离开input框才会更新数据:<input type="text" v-model.lazy="value">②.trim:
输入框过滤首尾的空格:<input type="text" v-model.trim="value">③.number:
先输入数字就会限制输入只能是数字,先字符串就相当于没有加number,注意,不是输入框不能输入字符串,是这个数据是数字:<input type="text" v-model.number="value">
2、事件修饰符
④.stop:
阻止事件冒泡,相当于调用了event.stopPropagation()方法:<button @click.stop="test">test</button>⑤.prevent:
阻止默认行为,相当于调用了event.preventDefault()方法,比如表单的提交、a标签的跳转就是默认事件:<a @click.prevent="test">test</a>⑥.self:
只有元素本身触发时才触发方法,就是只有点击元素本身才会触发。比如一个div里面有个按钮,div和按钮都有事件,我们点击按钮,div绑定的方法也会触发,如果div的click加上self,只有点击到div的时候才会触发,变相的算是阻止冒泡:<div @click.self="test"></div>⑦.once:
事件只能用一次,无论点击几次,执行一次之后都不会再执行<div @click.once="test"></div>⑧.capture:
事件的完整机制是捕获-目标-冒泡,事件触发是目标往外冒泡⑨.sync
对prop进行双向绑定
⑩.keyCode:监听按键的指令,具体可以查看vue的键码对应表
14.vue等单页面应用及其优缺点
优点
Vue 的目标是通过尽可能简单的 API 实现响应的数据绑定和组合的视图组件,核心是一个响应的数据绑定系统。
数据驱动、组件化、轻量、简洁、高效、模块友好、页面切换快
缺点
不支持低版本的浏览器,最低只支持到IE9;
不利于SEO的优化(如果要支持SEO,建议通过服务端来进行渲染组件);
首屏加载耗时相对长一些;
不可以使用浏览器的导航按钮需要自行实现前进、后退。
浏览器面试题
1.页面刷新不出来,可能是有哪些方面问题
可以从 URL输入到页面显示的步骤进行分析,大概是:
1、域名不存在,或者ip地址错误
2、网络问题,不能建立正常的tcp连接
3、服务器找不到正确的资源
2.浏览器架构
3.浏览器下事件循环(Event Loop)
Task:(宏任务)
1.setTimeout
2.setInterval
3.setImmediate (Node独有)
4.requestAnimationFrame (浏览器独有)
5.I/O
6.UI rendering (浏览器独有)
7.script标签
MicroTask:(微任务)
1.process.nextTick (Node独有)
2.Promise
3.MutationObserver
执行顺序:先是同步任务、再是该同步任务下的微任务,再是宏任务,之后宏任务下的微任务,再是宏任务...
任务队列先进先出,执行栈先进后出。
4.从输入 url 到展示的过程
1、DNS服务器解析域名,找到对应服务器的IP地址;
2、和服务器建立TCP三次握手连接;
3、发送HTTP请求,服务器会根据HTTP请求到数据服务器取出相应的资源,并返回给浏览器;
4、浏览器处理响应
①加载:浏览器对一个html页面的加载顺序是从上而下的。当加载到外部css文件、图片等资源,浏览器会再发起一次http请求,来获取外部资源。当加载到js文件,html文档会挂起渲染(加载解析渲染同步)的线程,等待js文件加载、解析完毕才可以恢复html文档的渲染线程。②解析:解析DOM树和CSSDOM树。
③渲染:构建渲染树,将DOM树进行可视化表示,将页面呈现给用户。
6.存储
7.Web Worker
8.GC垃圾回收机制
1、垃圾回收机制(GC:Garbage Collection),执行环境负责管理代码执行过程中使用的内存。浏览器会在浏览器渲染的空闲时间内清除内存。
2、在V8中,主要将内存分为新生代和老生代,新生代的对象为存活时间较短的对象,老生代中的对象为存活时间较长或常驻内存的对象。
3、栈内存的回收,栈内存在调用栈上下文切换后就会被回收。
4、堆内存的回收
①新生代内存回收机制:新生代内存容量小,默认下,64位系统下仅有32M
②晋升:如果新生代的变量经过复制依然依然存活时,那么就会被放入老生代内存中。晋升有两个条件:
(1)是否经历过新生代的回收
(2)To空间内存占比超过限制
③老生代内存回收机制
(1)V8在老生代中主要采用Mark-Sweep和Mark-Compact相结合的方式进行垃圾回收。主要使用Mark-Sweep,在空间不足以对新生代中晋升过来的对象进行分配时才使用Mark-Compact。
(2)Mark-Sweep:在标记阶段遍历所有堆中的所有对象,并标记活着的对象,在清除阶段清除没有标记的对象。
(3)Mark-Compact:在Mark-Sweep的基础上演变而来,差别在于在标记死亡后,在整理过程中会将活着的对象往一端移动,移动后,直接清理掉边界外的内存,解决Mark-Sweep的内存碎片问题。
9.内存泄露
服务端与网络
1.http/https 协议
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
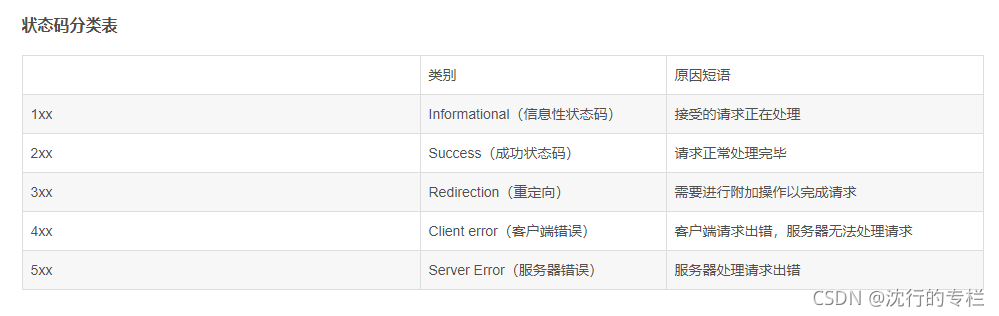
2.常见状态码
3.get/ post的区别
1、GET在浏览器回退是无害的,而POST会再次提交请求
2、GET产生的URL地址可以被收藏,而POST不可以
3、GET请求会被浏览器主动缓存,而POST不会,除非手动设置
4、GET请求只能进行url编码,而POST支持多种编码形式5、GET请求参数会被完整保留在浏览器历史记录里,而post中的参数不会被保留
6、GET请求在url中传递的参数是有长度限制的,而POST没有
7、对参数的数据类型,GET只接受ASCII类型,而POST没有限制
8、GET比POST更不安全,因为参数直接暴露在url上,所以不能用传递敏感信息
9、GET参数通过url传递,POST放在Request body报文体中
4.Websocket
1、webSocket是一种通信协议,是一项可以让服务器将数据主动推送给客户端的技术。
2、基于TCP传输协议,并复用HTTP的握手通道(握手阶段),和http协议同属于应用层,默认端口也是 80 和 443 ,能通过各种 HTTP 代理服务器。
3、数据格式比较轻量,性能开销小,通信高效。
4、可以发送文本,也可以发送二进制数据。
5、没有同源限制,客户端可以与任意服务器通信。
6、协议标识符是ws(如果加密,则是wss),请求的地址就是后端支持websocket的API。
5.TCP 三次握手
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
6.TCP 四次挥手
1、客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
2、服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
3、客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
4、服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
5、客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
6、服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
7.Node 的 Event Loop: 6 个阶段
1、timer阶段:执行到期的setTimeout / setInterval 队列回调;
2、I/O阶段:执行上轮残留的callback
3、idle,prepare:这个阶段仅在内部使用,可以不必理会
4、poll阶段:等待回调。a:执行回调,b:执行定时器(如果遇到setTimeout / setInterval ,则返回到timer阶段。如果遇到setImmediate,则前往check阶段。)
5、check阶段:执行setImmediate()的回调函数。
6、close callbacks阶段:例如:socket.on(‘close’, …)这种close事件的回调。
8.http报文的组成部分
1、请求报文(请求行、请求头、空行、请求体)
2、响应报文(状态行、响应头、空行、响应体)
9.HTTP和HTTP2的区别
1,二进制传输
http2采用二级制传输,相对于http1的文本传输安全性要高2,多路复用
http一个链接只能提交一个请求,而http2能同时处理无数个请求,可以降低连接的数量,提高网络的吞吐量。3,头部压缩
http2通过gzip与compress对头部进行压缩,并且在客户端与服务端各维护了一份头部索引表,只需要根据索引id就可以进行头部信息的传输,缩小了头部容量,间接提升了传输效率。4,服务端推送
http2可以主动推送资源到客户端,避免客户端花过多时间逐个请求,降低相应时间
10.什么是持久连接
1.HTTP(1.1版本才支持)协议采用"请求-应答"模式,当使用普通模式时,即非 "keep-alive" 模式时,每个请求/应答客户和服务器都要新建一个连接,完成之后立即断开连接(HTTP协议为无连接的协议)。
2.当使用keep-alive模式(又称持久连接、连接重用)时,keep-alive功能使客户端到服务端的连接持续有效,当出现对服务器的后继请求时,keep-alive功能避免了建立或者重新建立连接。
11.什么是管线化
HTTP管线化:是将多个HTTP请求(request)整批提交的技术,而在发送过程中不需先等待伺服端的回应。管线化机制通过持久连接,且只有Get和Post支持,Post有所限制
1.在使用持久连接的情况下,某个连接上消息的传递类似于
请求1->响应1->请求2->响应2->请求3->响应3
2.某个连接上的消息变成了类似这样(管线化)
请求1->请求2->请求3->响应1->响应2->响应3
12.http协议的主要特点
1、简单快速,2、灵活,3、无连接,4、无状态
Webpack 相关
1.原理简述
把所有依赖打包成一个 bundle.js 文件,通过代码分割成单元片段并按需加载。
2.Loader
loader用于加载某些资源文件。因为webpack本身只能打包common.js规范的js文件,对于其他资源如css,img等,是没有办法加载的,这时就需要对应的loader将资源转化,从而进行加载。
3.Plugin
plugin用于扩展webpack的功能。不同于loader,plugin的功能更加丰富,比如压缩打包,优化,不只局限于资源的加载。
4.编译优化
1、减小代码体积,可以使用CDN引入一些npm包。局部引入一些类库,避免无用的文件的引入。
2、在使用loader的时候,使用exclude和include,减少loader遍历的目录范围,加快webpack的构建速度。
3、在resolve中配置alias,减少检索路径。
4、使用dllPlugin或者allReferencePlugin 进行预先构建,把改变频率比较小的第三方库等依赖单独构建。
5.Chunk
Chunk是Webpack打包过程中,一堆module的集合。我们知道Webpack的打包是从一个入口文件开始,也可以说是入口模块,入口模块引用这其他模块,模块再引用模块。Webpack通过引用关系逐个打包模块,这些module就形成了一个Chunk。
6.Frefetch 这段代码告诉浏览器,这段资源将会在未来某个导航或者功能要⽤到,但是本资源的下载顺序权重⽐较低。也就是说prefetch通常⽤于加速下被标记为prefetch的资源,将会被浏览器在空闲时间加载
7.Preload 通常⽤于本页⾯要⽤到的关键资源,包括关键js、字体、css⽂件。preload将会把资源得下载顺序权重提⾼,使得关键数据提前下载好,优化页⾯打开速度。
算法
1.五大算法
2.基础排序算法
3.高级排序算法
4.递归运用(斐波那契数列): 爬楼梯问题
5.数据树
6.天平找次品
进阶知识
React框架
1.Fiber
2.生命周期
3.setState
4.HOC(高阶组件)
5.Redux
6.React Hooks
7.SSR 服务端渲染
8.函数式编程















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









