







0 背景
之前学习过d2l课程,在反向传播那块过的比较快,后面训练了很多的神经网络,但总是感觉有些困顿迷茫,所以重新过了一遍基础知识
1 Back propagation
为什么训练需要比推理占用更多的显存呢?这是因为反向传播需要用到前向传播过程中很多的值,所以在前向传播的时候,需要将一些中间激活函数的值给存储起来,主要用到的有下面三种:
- 输入值(input)
- 权重值(weights)
- 激活函数的输出,这里以sigmoid函数为例,sigmoid函数求导之后的值为f(x)(1-f(x))所以需要用到f(x)之前的值
2 Lec 7 结合李宏毅的课程阐述
公式
∂
L
(
θ
)
∂
w
=
∑
∂
C
n
(
θ
)
∂
w
\frac{\partial{L(\theta)}}{\partial{w}} = \sum{\frac{\partial{C^n(\theta)}}{\partial{w}}}
∂w∂L(θ)=∑∂w∂Cn(θ)用于求解最后的损失函数对于某个参数
w
w
w的梯度,其中
C
n
(
θ
)
C^n(\theta)
Cn(θ)为所有样本的真实值和预测值之间的差距
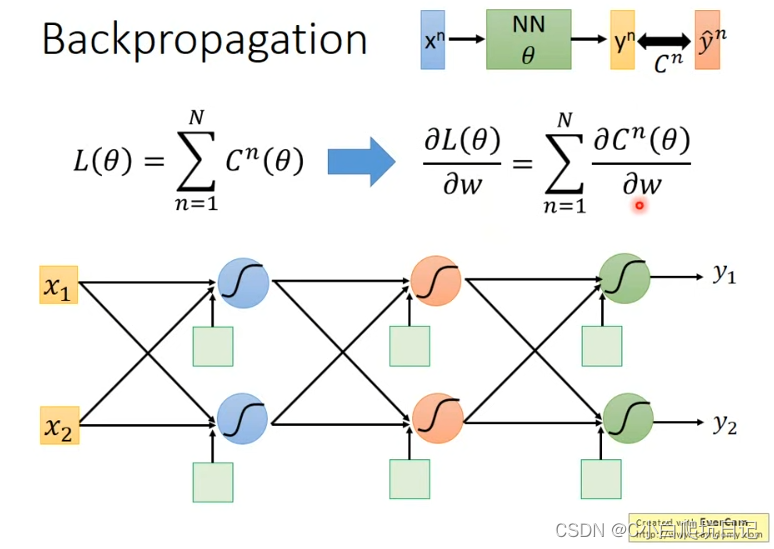
当遇到第一个激活函数的时候,可以按照链式求导法则对其进行拆分为激活函数左边和右边两个部分,左边的部分为
∂
Z
∂
w
\frac{\partial{Z}}{\partial{w}}
∂w∂Z,这部分结果就是激活函数左侧的输入,而
∂
C
∂
z
\frac{\partial{C}}{\partial{z}}
∂z∂C则是神经元右侧的结果
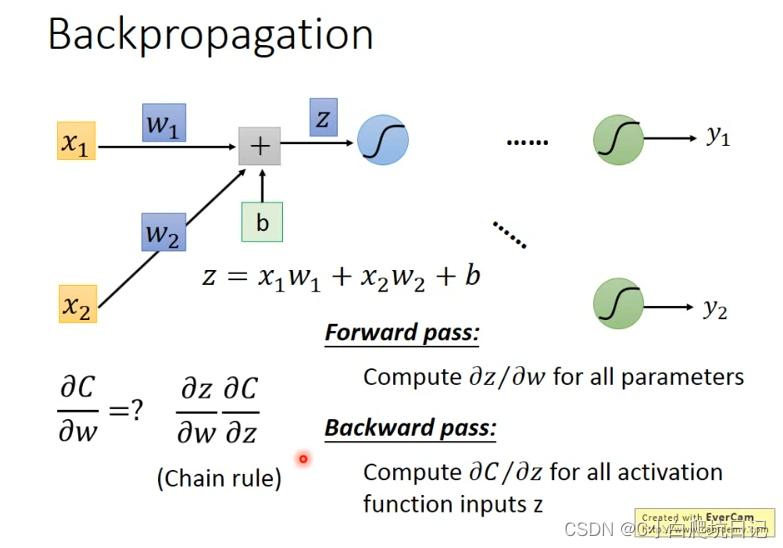
逆向的时候是直接用
∂
z
\partial{z}
∂z乘以后面的结果,所以这里的
∂
z
\partial{z}
∂z是一个常数值
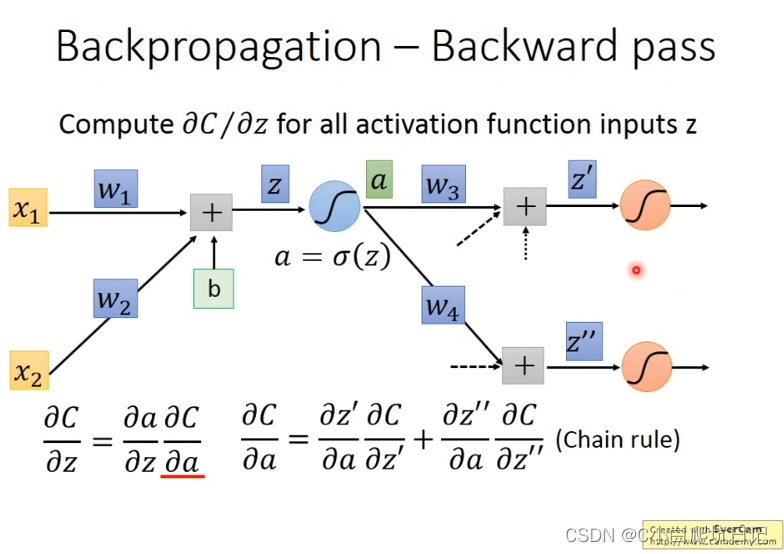
∂
′
z
\partial'{z}
∂′z需要用到结果a是因为假设激活函数为sigmoid函数,那么它的导数形式为f(x)(1-f(x),所以在前向计算过程当中得到的值要保存下来以供后向传播时候使用

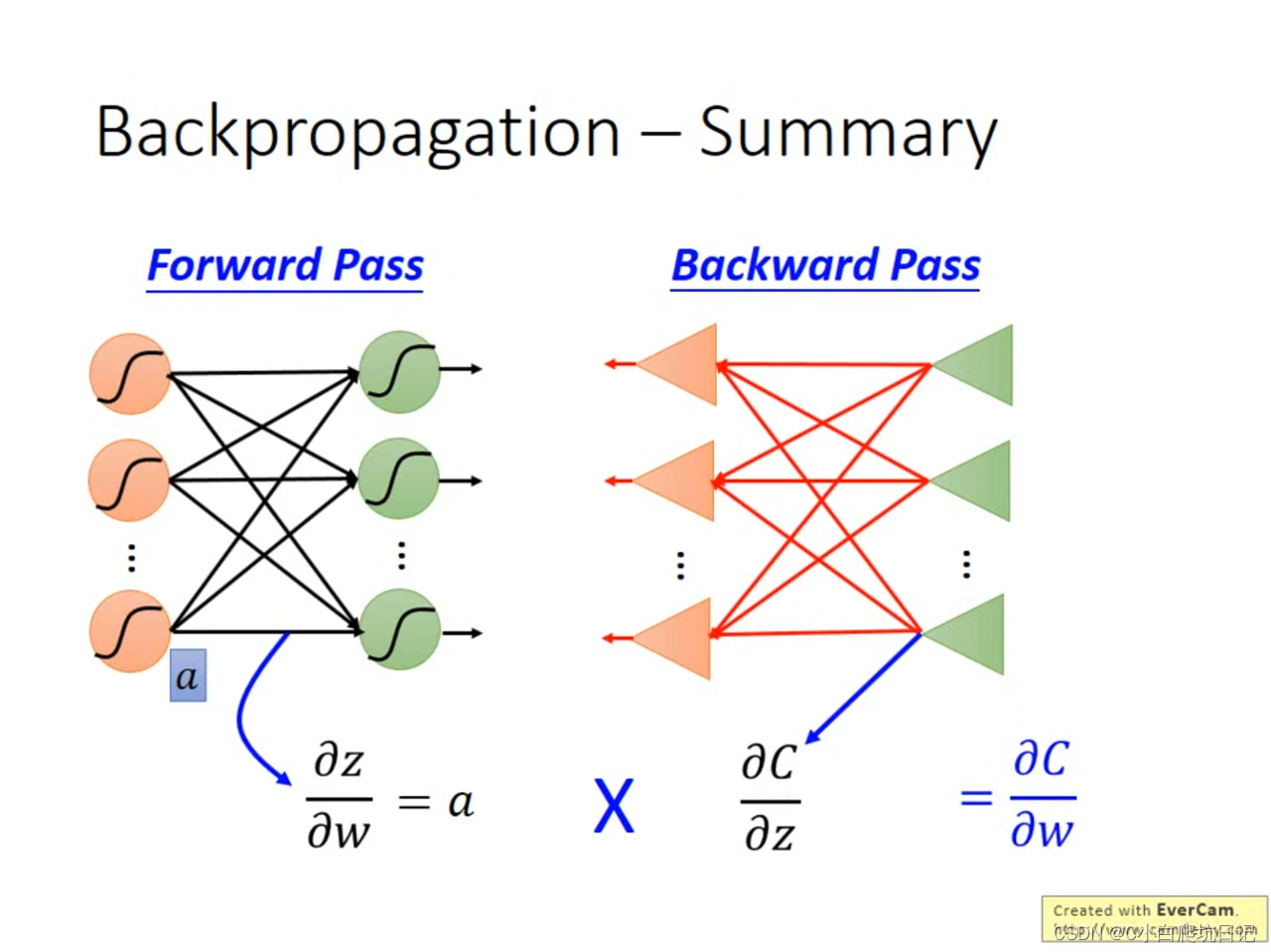
上述过程可以堪称是建立一个反向的nerul network,反向的nerul network只有在正向完成计算之后才有机会算的出来















 1433
1433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









