







前言:
这里附上一个很全面的人脸识别发展综述文章
《人脸识别的最新进展以及工业级大规模人脸识别实践探讨》
https://blog.csdn.net/valada/article/details/80892724
并行训练的方式:
- 1.nn.DataParallel数据并行。将一个batchsize中的数据分给多个GPU并行训练。
- 2.模型并行。将FC层拆分给多个GPU进行并行训练。
- 3.partial_fc。(抽样fc层)
一、模型并行
目前处理大规模(数据多、类别大)数据集的方法:
混合并行:即backbone使用数据并行,分类层使用模型并行;
该方法具备两个优点:
- 1)缓解了 W 的存储压力。将W划分为k个子矩阵w;
- 2)将 W 梯度的通信转换成了所有GPU的特征 X 与 softmax 局部分母的通信,大大降低了数据并行带来的通信开销。
模型并行的结构图:
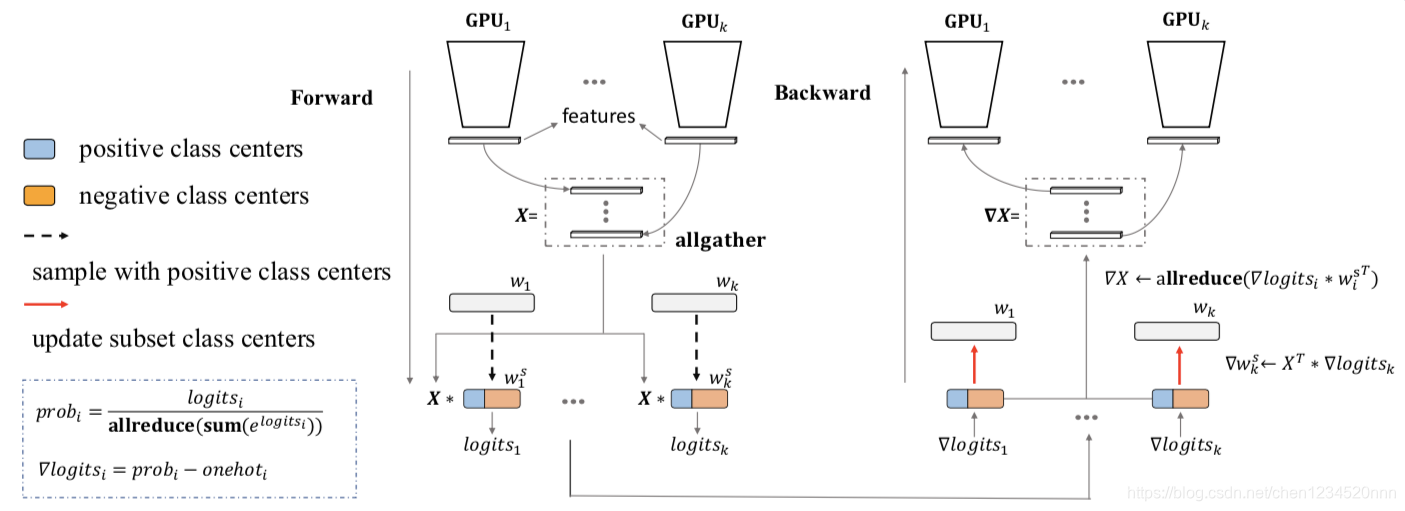
模型并行方法的弊端:
模型并行的方式理论上看似能无限增加类别数(只要增加GPU数量即可),但是实际上大家在尝试更大规模、更多机器的时候,会发现显存不够用了,好像增加类别数的同时增加机器,单个GPU的显存还在增长?其实我们忽略了另外一个占据显存的张量:predicted logits的存储会受到总批大小的增加的影响。logits(预计日志的存储会受到总批大小的增加的影响)。
首先定义 logits = X_w,其中 w 为存储在每张GPU上的子矩阵,X 为经过集合通信 Allgaher 收集到的全局特征,d 为特征的维度大小,C 为总的类别数,k 为GPU的个数。其中每块GPU中 w 占用的显存为:
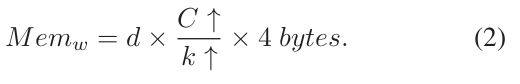
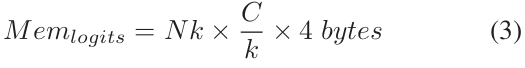
结论:当我们不停的增加GPU数量时,logits占用的内存也会增大,当GPU数量K大到一定量时,内存就会溢出了。
二、Partial FC(FC抽样)

该研究对此提出了一个简单的解决方案:
在实现混合并行时,不仅同步每张卡的特征,同时也同步每张卡的标签,这样每张卡都具备所有卡的完整特征和标签。假设总的批次大小为 kN,则至多会有 kN 个正类中心随机分布在所有的GPU中,让每个正类中心所属的GPU将该正类采样出来即可,每张GPU正类采出来后,再随机用负类补齐到约定的采样率。这样每张GPU采样到的类中心一样多,实现负载均衡。后续的过程就是分类层的模型并行部分了,需要注意的是,只有采样出来的类中心的权重和动量会更新。
partial_fc论文博客:
https://jishuin.proginn.com/p/763bfbd2fee4
https://blog.csdn.net/weixin_43152063/article/details/115307938
https://blog.51cto.com/u_15282017/2974039















 4993
4993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









