






在日常生活中,我们经常会碰到打开一个文件,但是文件内容乱码的问题,比如我想看《西游记》这部小说。
下载链接:https://m.ijjjxs.com/txt/dl-35-12585.html
点击TXT电子书下载,很快就会下载完成,但是使用电脑自带的TXT工具打开发现乱码,这个时候你是不是有种被骗的感觉?

文件内容乱码
其实网站并没有骗你,只是没有弄清楚字符编码的问题,那么什么是字符编码,如何尽量避免这种情况出现,接下来本文将详细讨论所有的细节,并使用代码实现Unicode字符集在计算机中的显示。
内容乱码的问题你可以选择带有多个字符编码的编辑器打开,具体到《西游记》这部小说中,
当我选择CLion打开文件之后,提示我"The file was loaded in a wrong encoding: 'UTF-8'",

加载或转换
当更换它的编码格式为GB2312时,文件内容能够正常显示,什么是GB2312,这中间计算机做了什么?
(一)计算机基础知识
二进制
1854年,英国数学家乔治·布尔发表了一篇里程碑式的论文,其中详细介绍了一种代数化的逻辑系统,后人称之为布尔代数。他提出的逻辑演算在后来的电子电路设计中起基础性作用。
1937年,克劳德·香农在麻省理工大学完成了其电气工程硕士学位论文《继电器与开关电路的符号分析》,用继电器和开关实现了布尔代数和二进制算术运算,其中香农的理论奠定了数字电路的理论基础。
二进制中每个数字称为一个比特(Bit,Binary digit 的缩写)。
加法:0+0=0,0+1=1,1+0=1,1+1=10
减法:0-0=0,1-0=1,1-1=0,10-1=1
乘法:0×0=0,0×1=0,1×0=0,1×1=1
除法:0÷1=0,1÷1=1
字节
通常以8个比特作为一个字节(Byte),日常生活中的计量单位:
1 Byte = 8 Bit
1KB = 1024 Byte
1MB = 1024 KB
1GB = 1024 MB
(二)ASCII编码
维基百科:字符编码
https://zh.wikipedia.org/zh-cn/%E5%AD%97%E7%AC%A6%E7%BC%96%E7%A0%81
令人尴尬的是当我想把维基百科关于字符编码的网址粘贴上来时,发现又出现乱码,这虽然不影响使用,但是极大地影响文章的美观性,它为什么不能显示成这样?
https://zh.wikipedia.org/zh-cn/字符编码
当我将带有中文的这个网址粘贴到浏览器上去,发现它竟然还是能访问到对应的网页,真是太让人匪夷所思?
查看“字”的字符编码
https://www.compart.com/en/unicode/U+5B57
UTF-8 Encoding: 0xE5 0xAD 0x97
神奇地发现这里的0xE5 0xAD 0x97和前面的网址%E5%AD%97是一一对应的,现在是迫切地需要知道什么是字符编码,才能解释刚刚所发生的事情。
在19世纪电报的发展彻底改变了信息的远距离传输方式之前,中国、埃及和希腊等古代文明使用鼓声、信号火或烟雾信号在遥远的点之间交换信息。
美国发明家萨缪尔·摩尔斯在1837年发明了电报,还发展出一套将字母及数字编码以便拍发的方法,称为摩斯电码。

国际摩斯电码
这应该是现代计算机字符编码的雏型,使用点和线表示26个英文字母以及10个数字。
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。第一版标准发布于1963年,最后一次更新则是在1986年,至今为止共定义了128个字元。
控制字符的编号范围是0 - 31和127,共33个字符。
可显示字符的编号范围是32 - 126,共95个字符,其中48 - 57为0到9十个阿拉伯数字,65 - 90为26个大写英文字母,97 - 122为26个小写英文字母,其余为一些标点符号、运算符号等。
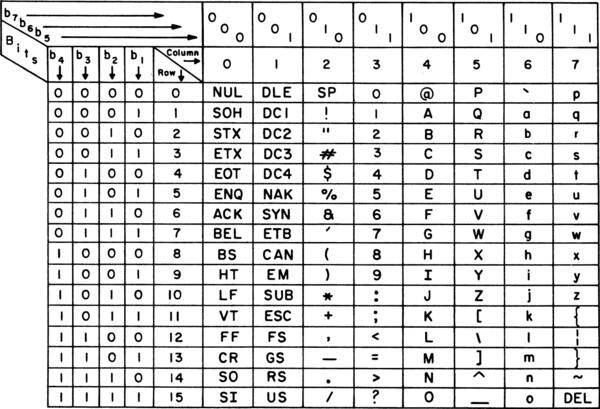
ASCII字符编码表
根据以上定义,可以将字符编码转换为二进制编码,使用Byte作为基础单位。
比如大写的字母A,它的十进制编码为65,它的二进制编码为
01000001 = 01000000 (十进制64) + 00000001 (十进制1)
如果要表示Hello这个单词,可以对应地查找字符表进行转换:
01001000 01100101 01101100 01101100 01101111
(三)Unicode编码
ASCII码非常简洁,完美地处理了美国的字符编码,但是它有个致命的缺陷,很多其它国家的字符它没有办法处理,比如日文的你好(こんにちは)。
此时很多国家各显神通。
中国发明GB/T 2312,全称《信息交换用汉字编码字符集·基本集》,标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个字符。
韩国发明KS X 1001,包含谚文2350字、汉字4888字、英文字母、数字和假名共8226字。
在GB/T 2312中每个汉字及符号的码位使用两个字节来表示,这样看上去也很简洁,只是比ASCII多一个字节的使用。
但是它存在很大的问题,比如想要输入缅甸语မင်္ဂလာပါ(你好),没有办法输入字符集中不存在的字符,它没法满足不同文化之间的交流。
就在此时Unicode横空出世,Unicode全称为Unicode标准(The Unicode Standard),其整理、编码了世界上大部分的文字系统,使得电脑能以通用划一的字符集来处理和显示文字,不但减轻在不同编码系统间切换和转换的困扰,更提供了一种跨平台的乱码问题解决方案。
Unicode广泛应用于电脑软件的国际化与本地化过程。
Unicode编码非常暴力, 在它的标准中
http://www.unicode.org/versions/Unicode8.0.0/appC.pdf
它定义了UCS-4 stands for “Universal Character Set coded in 4 octets.”去表示每个字符,也就是说它最大可以表示2^32次方 = 4294967296个字符。

Unicode字符集示例
可以看到“人”使用U+4EBA这个十六进制数表示,“雨伞”使用U+2602表示,用U+的方式表示所有它能够表示的字符。
到这里好像事情进入大结局,有个统一字符集,如果都采用它那就不会出现乱码问题呀?其实以上并没有讲述计算机是怎么表示它们的。接下来就会带你看到UTF8/UTF16/UTF32闪亮登台,一个驱魔乱舞的时代!














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









