







pandas可视化
pandas 可视化
绘图的目的是数据的可视化,数据的可视化是数据操作的重要方案。
特别是面对庞大众多的数据,尽管分组聚合还是其他什么方法能够得到数据的总体概览,但是都不能直观地显示出来。
绘图使得可视化就是要:展示数据的变化规律或是关联性,以及实际需求的一些特性表现情况。
图表可视化
限于篇幅,这里尽可能全面地包含图表可视化的众多方案。更多请参阅表格数据的可视化部分。
标准地引用 matplotlib API,后面的 plt 表意皆为此:
import matplotlib.pyplot as plt
plt.close("all")
基本绘图 - 两大构型的 plot 方法
Series 和 DataFrame 上的 plot 方法只是一个基于 plt.plot() 的简单封装。
下面引用两个实例简要说明:
Series.plot()
ts1 = pd.Series(np.random.randn(500), index=pd.date_range("20200101", periods=500))
ts1 = ts.cumsum() # 累和
ts1.plot()

- 如果索引由日期组成,它会调用
gcf().autofmt_xdate()格式化 x 轴。
DataFrame.plot()
DataFrame.plot() 可以很轻便地绘制所有列:
df2 = pd.DataFrame(np.random.randn(500, 4), index=ts1.index, columns=list("ABCD"))
df2 = df2.cumsum()
plt.figure();
df.plot();

- 可以使用
DataFrame中的某行作为横坐标,通过参数x指定.; - 也可以通过参数
y指定需要绘制的列,如下。
df3 = pd.DataFrame(np.random.randn(500, 4), index=ts.index, columns=list("ABCD"))
df3["range"] = pd.Series(list(range(500)), index=df3.index)
df3.plot(x="range", y=["A", "C"])

更多格式化和样式选择,参阅 Python 数据分析4:pandas绘图6(图表格式化)。
注意:
- 基本的图形,两大数据构型的方法都能够进行绘制;一些特别的如散点图,只有阵列结构的
DataFrame才能绘制。 - 绘制的方法和样式是复杂多样的。
更多图型绘制
DataFrame.plot() 可以传入多个关键字参数,可以实现复杂的绘制(各类图形、子图、分图等等)。
其中 kind 参数可以选择绘图图的类型,默认是 ‘line’,即线型图。
- ‘bar’ or ‘barh’ - 条形图
- ‘hist’ - 直方图
- ‘box’ - 盒式图
- ‘kde’ or ‘density’ - 密度图
- ‘area’ 平面图
- ‘scatter’ - 散点图
- ‘hexbin’ - 六边形图
- ‘pie’ - 扇形图
另一种方案是: DataFrame.plot.kind(),其中 kind 是可以作为 kind 参数的任意值。所以下面两句话是等价的。
df3.iloc[5].plot(kind="bar")
df3.iloc[5].plot.bar()
在 pandas.plotting 中还有一些绘制的函数,它们以 Series or DataFrame 作为数据参数传入,包括但不限于:
- scatter_matrix - 散点阵列图
- andrews_curves - 安德鲁斯曲线图
- parallel_coordinates - 平行坐标图
- lag_plot - 序列图
- autocorrelation_plot - 自相关图
- bootstrap_plot - Bootstrap 图
- radviz - 多维数据发布图
bar - 条形图
基本绘制:
- 对于一条
Series数据:
df3.iloc[5, 0:4].plot(kind="bar") # df3.iloc[5, 0:4].plot.bar()

- 对于
DataFrame,只是变得多条而已:
df4 = pd.DataFrame(np.random.randn(10, 4), columns=list("ABCD"))
df4.iloc[:, 0:4].plot.bar()

- 一个常见的简单格式:堆叠。通过设置参数
stacked=True实现。
df4.iloc[:, 0:4].plot.bar(stacked=True);

barh - 水平条形图
就是由垂直视图变到水平:
df4.iloc[:, 0:4].plot.barh(stacked=True);

histograms - 直方图
直方图也称分布图。
- 基本绘制
df5 = pd.DataFrame(
{
"a": np.random.randn(1000) + 1,
"b": np.random.randn(1000) - 1,
},
columns=["a", "b"],
)
df5.plot.hist(alpha=0.6)

- 条形的宽度(带宽):通过
bins参数进行设置。
df5.plot.hist(alpha=0.6, bins=20, stacked=True)

- 另一种绘制直方图的方案:
DataFrame.hist()。
df.hist()
df["a"].hist() # 单画一个 Series

box - 箱线图
箱线图(Box-plot)又称为盒须图、盒式图,用作显示一组数据分散情况资料,因形状如箱子而得名,常见于品质管理。主要用于反映原始数据分布的特征。

- 基本绘制
使用 Series.plot.box() 、 DataFrame.plot.box() 或 DataFrame.boxplot() 可视化:每列内的值分布。
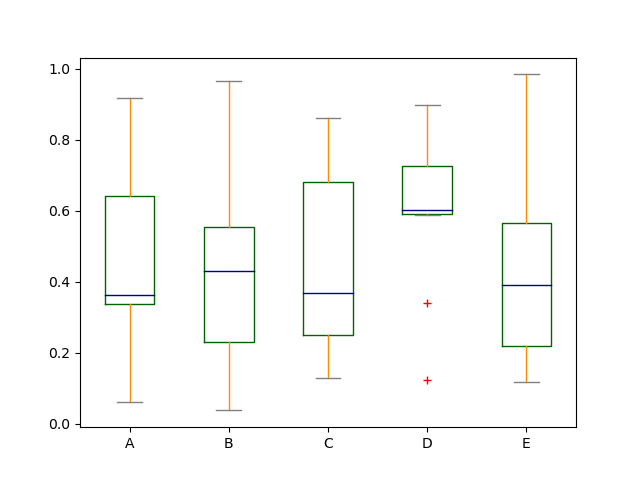
下面一个实例,使用箱线图展示了,五次 [0,1) 上的 10 个随机变量获取情况。
df6 = pd.DataFrame(np.random.rand(10, 5), columns=["A", "B", "C", "D", "E"])
df6.plot.box()
# df6.boxplot() # 默认有水平线

- 通过设置
color改变线条颜色。线条大致四种,即boxes、whiskers、medians、caps,所以color作为一个字典传入。 - 通过设置 `sym`` 参数改变异常数据的样式。
color = {
"boxes": "DarkGreen", # 箱子轮廓线
"whiskers": "DarkOrange", # 胡须线
"medians": "DarkBlue", # 中线
"caps": "Gray", # 帽子线
}
df6.plot.box(color=color, sym="r+");
- 通过参数
vert=False设置水平视图;通过参数positions=[1, 4, 5, 6, 8]设置位置与间隔。
df6.plot.box(vert=False, positions=[1, 4, 5, 6, 8])

area - 面积图
- 基本绘制
df7 = pd.DataFrame(np.random.rand(10, 4), columns=["a", "b", "c", "d"])
df7.plot.area()

NaN自动被 0 填充,如果需要,可以提前使用Dataframe.dropna()orDataframe.fillna()进行销毁或者填值。- 面积图默认
stacked=True,即默认堆叠。
- 设置不堆叠时,参数
alpha默认是 0.5。
df7.plot.area(stacked=False) # alpha default value is 0.5

scatter - 散点图
- 基本绘制
散点图常表示两条(一对)数据的关联性,只有阵列结构的 DataFrame 有绘制接口。横纵轴必须是两列数字类型,使用参数 x 和 y 进行设置。
df8 = pd.DataFrame(np.random.rand(50, 4), columns=["a", "b", "c", "d"])
df8.plot.scatter(x="a", y="b")

- 在一张坐标纸上绘制多对数据的散点图:绘制第 N 对时,通过设置参数
ax修改。
ax = df.plot.scatter(x="a", y="b", color="DarkBlue", label="Group 1")
df.plot.scatter(x="c", y="d", color="DarkGreen", label="Group 2", ax=ax)

- 颜色条:通过参数
c进行配置 - 散点大小:通过参数
s进行修改。
df8["species"] = pd.Categorical(
["setosa"] * 20 + ["versicolor"] * 20 + ["virginica"] * 10
)
df8.plot.scatter(x="a", y="b", c="c", s=50)
# df8.plot.scatter(x="a", y="b", c="species", s=50) # 离散颜色条

hexbin - 六边形图
Hexagonal bin plots.
- 基本绘制
df9 = pd.DataFrame(
{
"A": pd.Series(np.random.rand(1000)),
"B": pd.Series(np.arange(1000)),
}
)
df9.plot.hexbin(x="A", y="B", gridsize=25)

- 如果您的数据过于密集,以至于无法单独绘制每个点,那么 Hexbin 图可以成为散点图的有用替代方法。
- 和散点图一样,只有
DataFrame才有接口。
- 控制网格大小的参数
gridsize:控制格子数,默认值是 100,值越大,格子越多且越小。
df9.plot.hexbin(x="A", y="B", gridsize=125)

pie - 扇形图
- 基本绘制
series = pd.Series(3 * np.random.rand(4), index=["a", "b", "c", "d"], name="series")
series.plot.pie(figsize=(6, 6))

- 数据中的
NaN自动用 0 进行填充。 - 数据中有负数报错
ValueError。 - 最好选择方形的画布。
DataFrame绘制扇形图时,每列都能绘制一个:把子图参数设置subplot=True。- 通过设置
legend=False把旁边的图例隐藏。
df10 = pd.DataFrame(
3 * np.random.rand(4, 2), index=["a", "b", "c", "d"], columns=["A", "B"]
)
df10.plot.pie(subplots=True, figsize=(8, 4))
# df10.plot.pie(subplots=True, figsize=(8, 4), legend=False)
















 5802
5802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









