







自从node这一运行在服务端的 JavaScript横空出世以后,赋予了前端开发工程师强大的力量。文件I/O操作,连数据库写接口接口等等。我在刚开始学习的node的时候,尝试着爬了一个比较小的相亲网站2000多条交友信息,包括网名,年龄,图片,学历,工资等。今天在网上看了一个关于用Python爬取世纪佳缘的博客,兴趣使然,决定用node也试试效果。
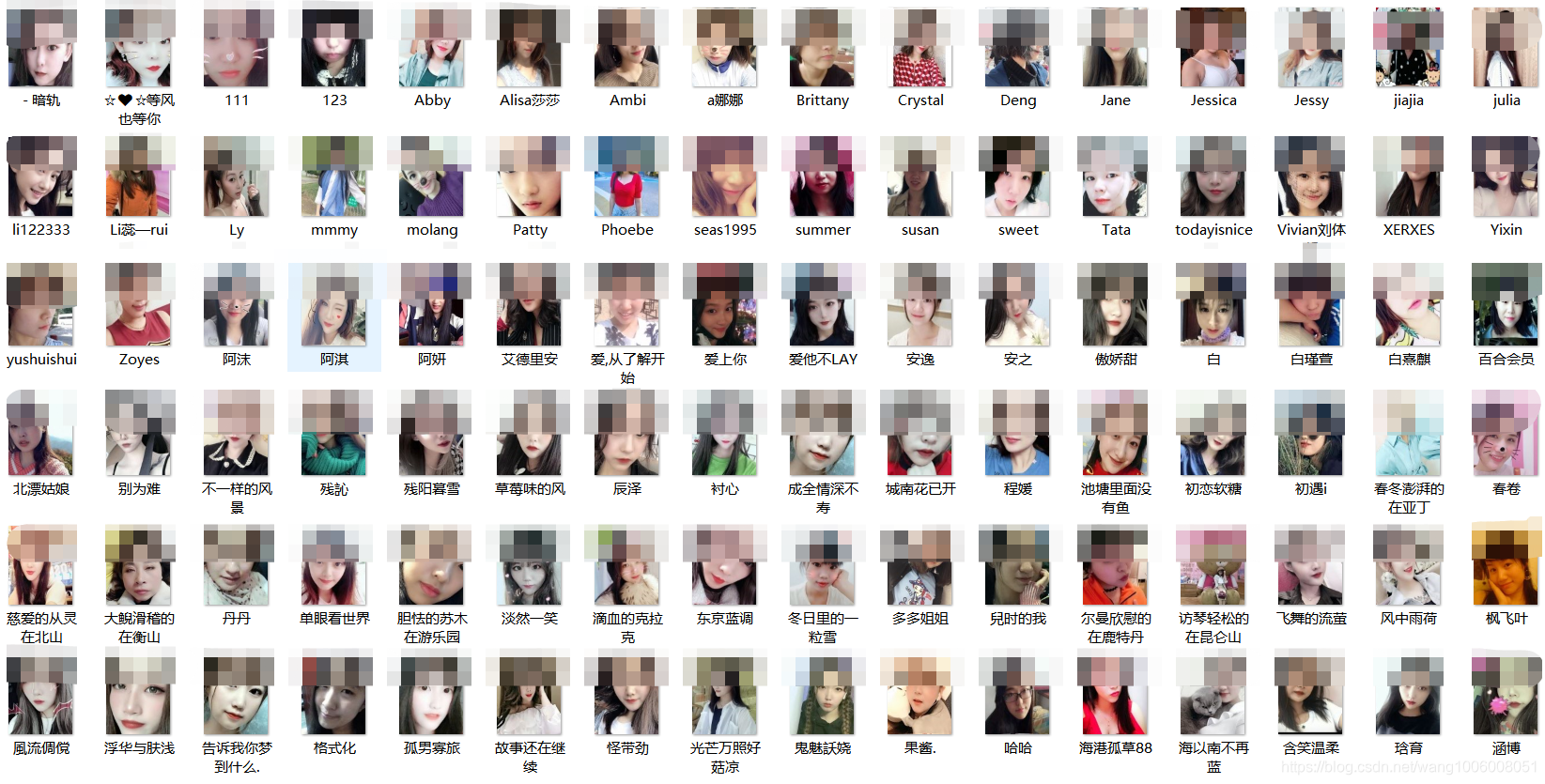
爬取的战果
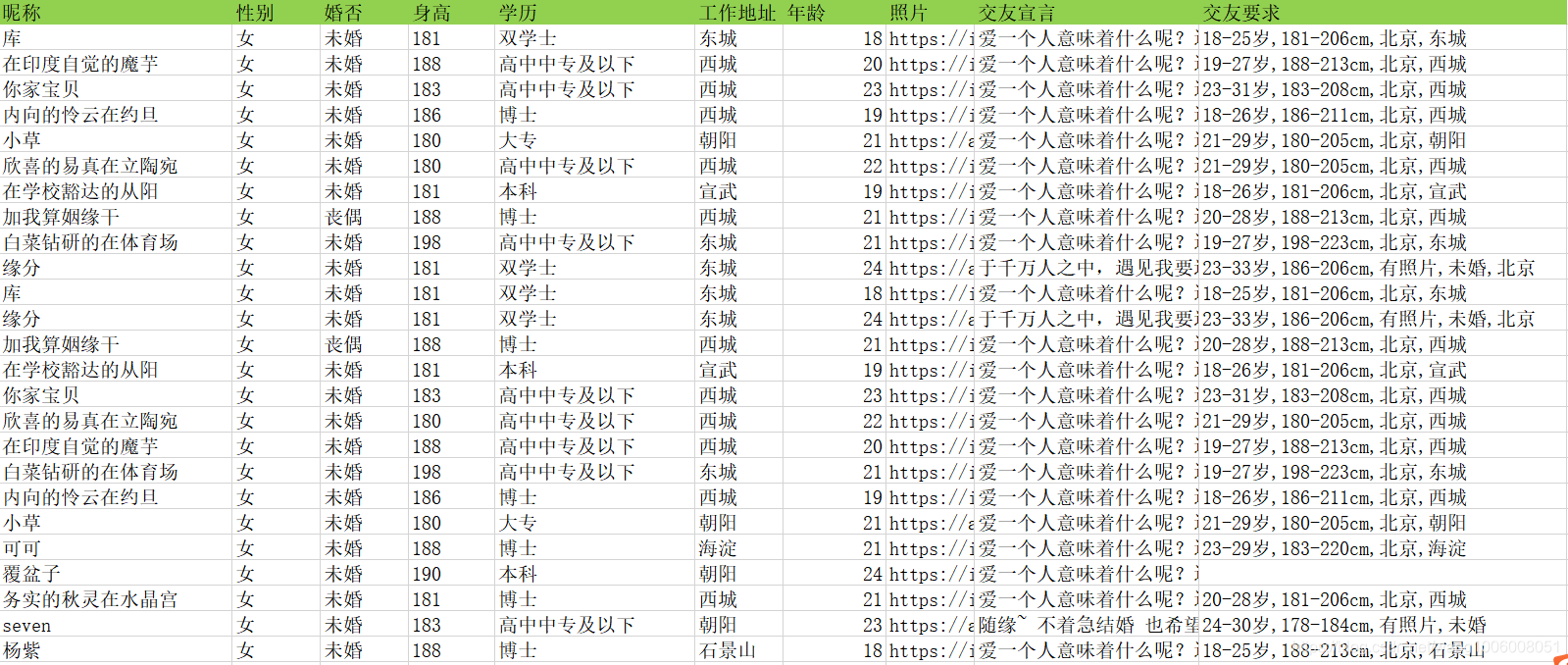
爬取的信息包括名称、身高、年龄、工作、照片、交友宣言、对另一半的要求等,结果用excel导出。照片以文件的形式写入到文件夹中。这里我没有使用数据库存储结果,如果自己有需要的话,可以把结果存入到Mysql或者Mongodb里,再对结果进行分析。
爬虫登场
爬虫部分四步:分析目标网页,获取网页内容,提取关键信息,输出保存。
首先分析目标网页
按F12召唤开发者工具页面,切换到Network选项,然后在翻页的时候抓包,成功截获请求URL和请求参数。
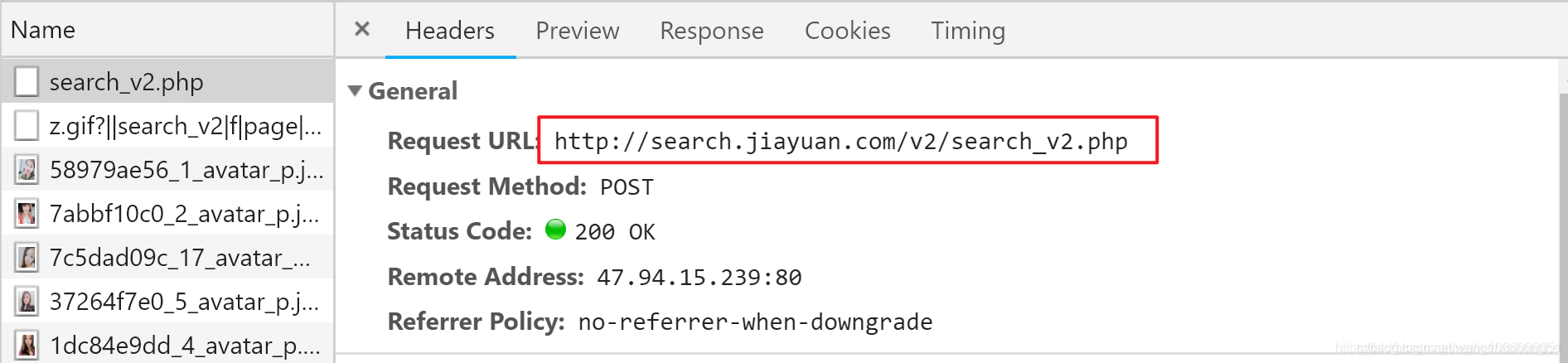
然后找到对应的请求信息:
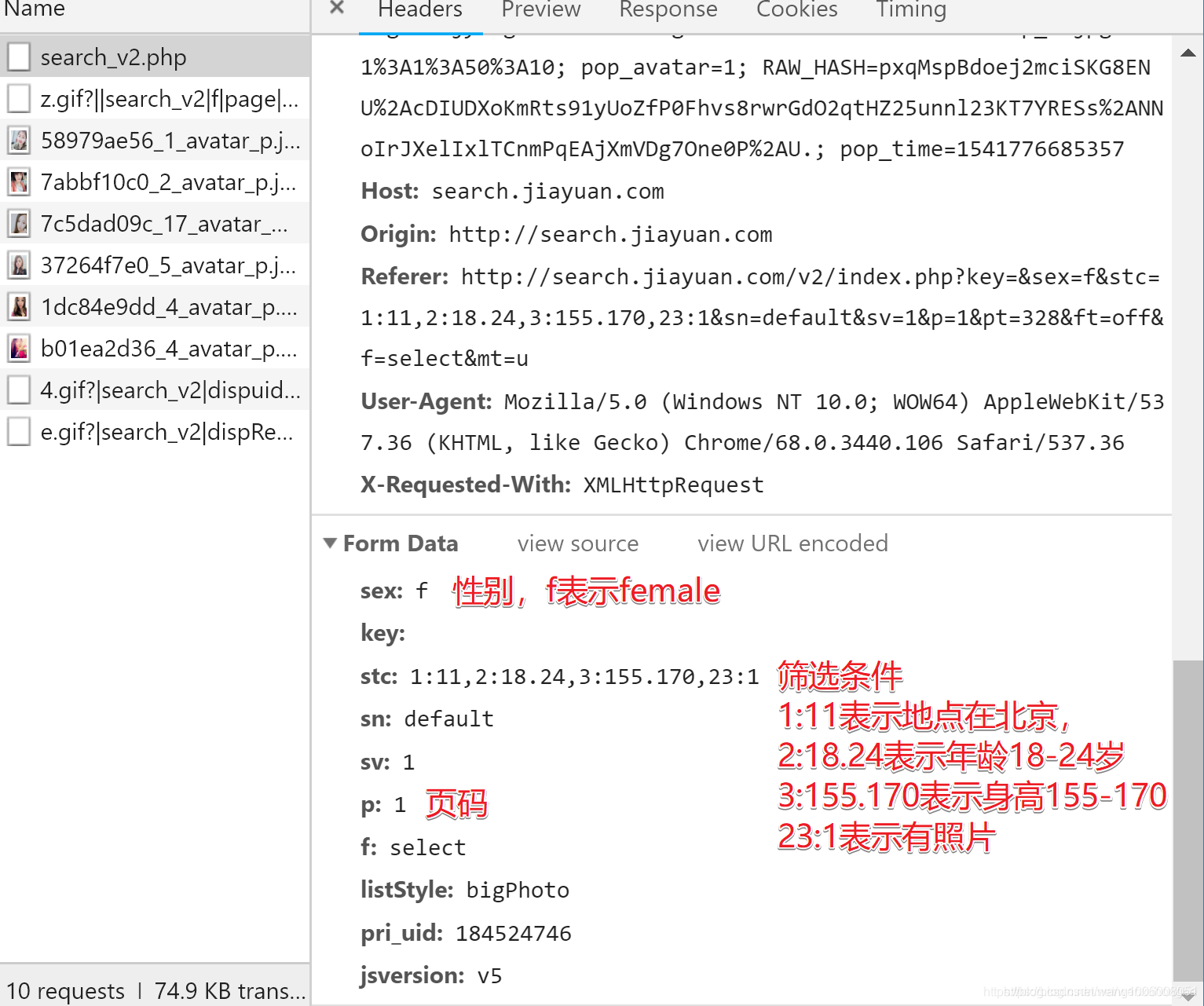
更多筛选条件及其对应的编号
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
| 地区 | 年龄 | 身高 | 学历 | 月薪 | 婚史 | 购房 | 购车 | 籍贯 | 户口 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 22 | 23 |
| 民族 | 宗教信仰 | 有无子女 | 职业 | 公司类型 | 生肖 | 星座 | 血型 | 诚信等级 | 照片 |
构造完整的请求的 URL
http://search.jiayuan.com/v2/search_v2.phpkey=&sex=f&stc=1:11,2:18.24,3:155.170,23:1&sn=default&sv=1&p=1&f=select
直接访问没有问题,改变p值访问也是OK的。
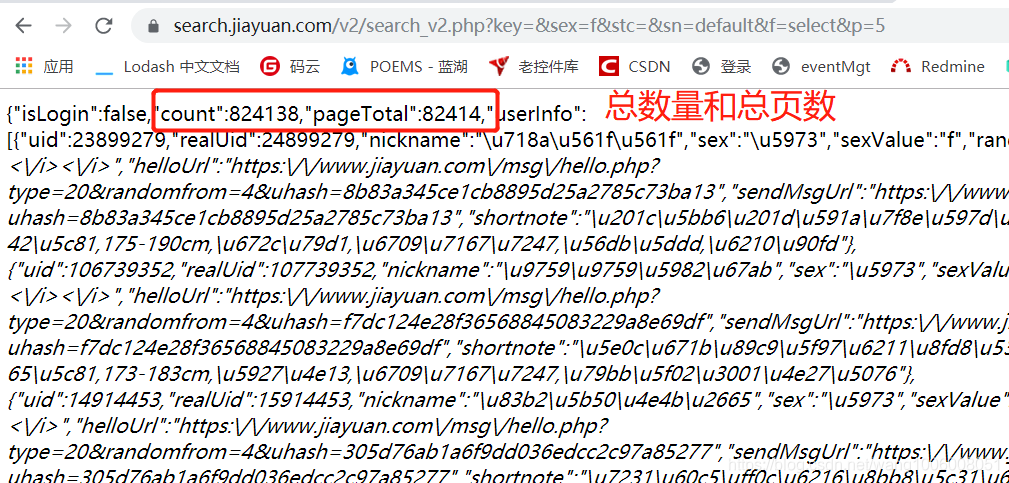
获取网页内容
有了请求地址,接下来就可以通过发送请求来获取网页内容了,这里我使用的是axios模块,当然了也可以使用request模块或者node自带的http模块。
const axios = require('axios');
axios.get(`http://search.jiayuan.com/v2/search_v2.phpkey=&sex=f&stc=1:11,2:18.24,3:155.170,23:1&sn=default&sv=1&p=1&f=select`).then(res => {
if (res.data.count && res.data.userInfo && res.data.userInfo.length) {
console.info('\x1B[36m%s\x1B[0m', `一共找到${res.data.count}个符合你的要求的交友信息!`);
}
}).catch(err => {
console.error('\x1B[31m', err);
})
为了方便参数更改、获取信息的更改,把参数配置和获取信息的配置提取出来。参数解析引入了qs模块。
const qs = require("qs");
const axios = require('axios');
/** 要爬取信息的条件 **/
searchParasm = {
sex: 'f', //f(女),m(男),
key: '', //关键词
stc: '1:11,2:18.24,3:155.170,23:11', //1:11表示地点北京, 2:18.24表示年龄18到24岁, 3:155.170表示身高在155到170, 23:11表示有照片,stc说明及更多信息请查看README
};
/**要获取的交友信息参数(不需要的信息注释即可)**/
const getInfoParams = {
nickname: '昵称',
sex: '性别',
marriage: '婚否',
height: '身高',
education: '学历',
work_location: '工作地址',
age: '年龄',
image: '照片',
// online: '是否在线',
// helloUrl: '打招呼地址',
// sendMsgUrl: '发消息地址',
shortnote: '交友宣言',
matchCondition: '交友要求'
}
/**
* 获取信息函数
* **/
let pageNow = 1; //当前页面
let pageTotal = 0; //总数量
let tableHeardValue = Object.values(getInfoParams); //表格头部信息
let tableHeardKeys = Object.keys(getInfoParams); //表格头部信息
let tableData = []; //表格数据信息
getInfoHttp = async(p) => {
await axios.get(`https://search.jiayuan.com/v2/search_v2.php?${qs.stringify(Object.assign(searchParasm,{p}))}`).then(res => {
if (res.data.count && res.data.userInfo && res.data.userInfo.length) {
pageTotal ? '' : pageTotal = res.data.pageTotal;
res.data.userInfo.map(item => {
// 异步下载头像
item.image.includes('images1.') ? '' : downImg(item);
// 过滤数据,存入到表格数组中
let middle = []
Object.entries(item).forEach(n => {
tableHeardKeys.includes(n[0]) ? middle.push(n[1]) : ''
})
tableData.push(middle);
});
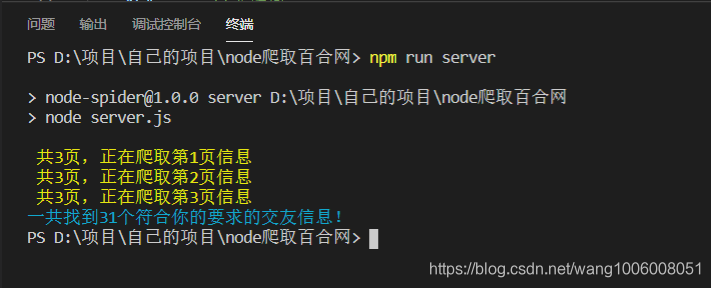
console.log('\x1B[33m', `共${pageTotal}页,正在爬取第${pageNow}页信息`);
if (pageNow < pageTotal) {
getInfoHttp(pageNow++);
} else {
writeXls('交友信息', [tableHeardValue].concat(tableData));
console.info('\x1B[36m%s\x1B[0m', `一共找到${tableData.length+1}个符合你的要求的交友信息!`);
}
}
}).catch(err => {
console.error('\x1B[31m', err);
})
};
仔细看上面的代码你可能会发现,使用两个函数 writeXls为表格写入函数及downImg图片下载函数,代码如下
const fs = require("fs");
const path = require("path");
const xlsx = require('node-xlsx');
/**
* 写入信息到表格中
* @param {string} name 表名称
* @param {array} data 表格数据
*/
writeXls = (name, data) => {
let buffer = xlsx.build([{
name,
data
}]);
fs.writeFileSync('info.xlsx', buffer, { 'flag': 'w' }); //生成excel
};
/**
* 下载图片函数
* **/
downImg = (params) => {
axios({
url: params.image,
responseType: 'arraybuffer'
}).then(res => {
fs.writeFile(path.join(__dirname, './imgs/') + `/${params.nickname}.png`, res.data, { encoding: "binary" }, () => {});
})
};
大功告成,输入自己心仪的的条件,执行getInfoHttp函数即可找到自己想要的交友啦!
github地址:https://github.com/1006008051/node-spider.git, 欢迎start














 5560
5560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









