







进程号和相关函数
每个进程都由一个进程号来标识,其类型为 pid_t(整型),进程号的范围:0~32767。进程号总是唯一的,但进程号可以重用。当一个进程终止后,其进程号就可以再次使用。
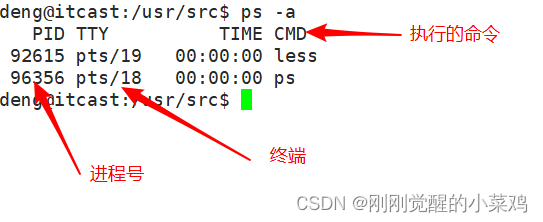
进程号(PID):
标识进程的一个非负整型数。
父进程号(PPID):
任何进程( 除 init 进程)都是由另一个进程创建,该进程称为被创建进程的父进程,对应的进程号称为父进程号(PPID)。如,A 进程创建了 B 进程,A 的进程号就是 B 进程的父进程号。
进程组号(PGID):
进程组是一个或多个进程的集合。他们之间相互关联,进程组可以接收同一终端的各种信号,关联的进程有一个进程组号(PGID) 。这个过程有点类似于 QQ 群,组相当于 QQ 群,各个进程相当于各个好友,把各个好友都拉入这个 QQ 群里,主要是方便管理,特别是通知某些事时,只要在群里吼一声,所有人都收到,简单粗暴。但是,这个进程组号和 QQ 群号是有点区别的,默认的情况下,当前的进程号会当做当前的进程组号。
getpid函数
#include <sys/types.h> #include <unistd.h> pid_t getpid(void); 功能: 获取本进程号(PID) 参数: 无 返回值: 本进程号
getppid函数
#include <sys/types.h> #include <unistd.h> pid_t getppid(void); 功能: 获取调用此函数的进程的父进程号(PPID) 参数: 无 返回值: 调用此函数的进程的父进程号(PPID)
getpgid函数
#include <sys/types.h> #include <unistd.h> pid_t getpgid(pid_t pid); 功能: 获取进程组号(PGID) 参数: pid:进程号 返回值: 参数为 0 时返回当前进程组号,否则返回参数指定的进程的进程组号
示例:
int main()
{
pid_t pid, ppid, pgid;
pid = getpid();
printf("pid = %d\n", pid);
ppid = getppid();
printf("ppid = %d\n", ppid);
pgid = getpgid(pid);
printf("pgid = %d\n", pgid);
return 0;
}
进程的创建
系统允许一个进程创建新进程,新进程即为子进程,子进程还可以创建新的子进程,形成进程树结构模型。
#include <sys/types.h> #include <unistd.h> pid_t fork(void); 功能: 用于从一个已存在的进程中创建一个新进程,新进程称为子进程,原进程称为父进程。 参数: 无 返回值: 成功:子进程中返回 0,父进程中返回子进程 ID。pid_t,为整型。 失败:返回-1。 失败的两个主要原因是: 1)当前的进程数已经达到了系统规定的上限,这时 errno 的值被设置为 EAGAIN。 2)系统内存不足,这时 errno 的值被设置为 ENOMEM。
int main()
{
fork();
printf("id ==== %d\n", getpid()); // 获取进程号
return 0;
}
运行结果如下:
从运行结果,我们可以看出,fork() 之后的打印函数打印了两次,而且打印了两个进程号,这说明,fork() 之后确实创建了一个新的进程,新进程为子进程,原来的进程为父进程。
父子进程关系
使用 fork() 函数得到的子进程是父进程的一个复制品,它从父进程处继承了整个进程的地址空间:包括进程上下文(进程执行活动全过程的静态描述)、进程堆栈、打开的文件描述符、信号控制设定、进程优先级、进程组号等。
子进程所独有的只有它的进程号,计时器等(只有小量信息)。因此,使用 fork() 函数的代价是很大的。
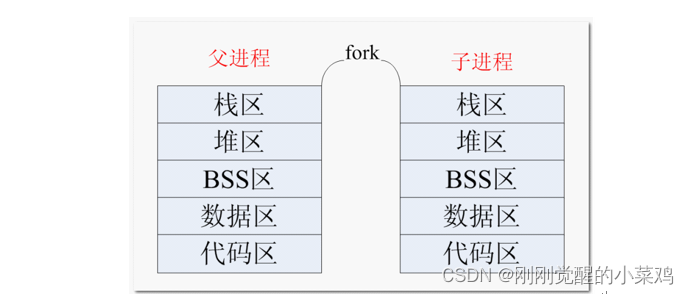
一个进程调用 fork() 函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。相当于克隆了一个自己。
实际上,更准确来说,Linux 的 fork() 使用是通过写时拷贝 (copy- on-write) 实现。写时拷贝是一种可以推迟甚至避免拷贝数据的技术。内核此时并不复制整个进程的地址空间,而是让父子进程共享同一个地址空间。只用在需要写入的时候才会复制地址空间,从而使各个进行拥有各自的地址空间。也就是说,资源的复制是在需要写入的时候才会进行,在此之前,只有以只读方式共享。
注意:fork之后父子进程共享文件,fork产生的子进程与父进程相同的文件文件描述符指向相同的文件表,引用计数增加,共享文件文件偏移指针。
区分父子进程
fork的结果,子进程返回0,父进程返回子进程的pid
int main()
{
pid_t pid;
pid = fork();
if (pid < 0)
{ // 没有创建成功
perror("fork");
return 0;
}
if (0 == pid)
{ // 子进程
while (1)
{
printf("I am son\n");
sleep(1);
}
}
else if (pid > 0)
{ // 父进程
while (1)
{
printf("I am father\n");
sleep(1);
}
}
return 0;
}父子进程地址空间
父子进程各自的地址空间是独立的
在子进程修改变量 a,b 的值,并不影响到父进程 a,b 的值。
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<sys/stat.h>
int a = 20;
int main()
{
int b = 10;
pid_t pid;
pid = fork();
if (pid < 0)
{ // 没有创建成功
perror("fork");
return 0;
}
if (0 == pid)
{ // 子进程
a = 30,b=30;
printf("child\n");
printf("a:%d, b:%d\n",a,b);
}
else if (pid > 0)
{ // 父进程
a = 40,b=40;
sleep(1);
printf("father\n");
printf("a:%d, b:%d\n",a,b);
}
return 0;
}child
a:30, b:30
father
a:40, b:40
GDB调试多进程
使用gdb调试的时候,gdb只能跟踪一个进程。可以在fork函数调用之前,通过指令设置gdb调试工具跟踪父进程或者是跟踪子进程。默认跟踪父进程。
-
set follow-fork-mode child 设置gdb在fork之后跟踪子进程。
-
set follow-fork-mode parent 设置跟踪父进程(默认)。
注意,一定要在fork函数调用之前设置才有效。
进程退出函数
#include <stdlib.h> void exit(int status); #include <unistd.h> void _exit(int status); 功能: 结束调用此函数的进程。 参数: status:返回给父进程的参数(低 8 位有效),至于这个参数是多少根据需要来填写。 返回值: 无
exit() 和 _exit() 函数功能和用法是一样的,无非时所包含的头文件不一样,还有的区别就是:exit()属于标准库函数,_exit()属于系统调用函数。
#include<stdio.h>
#include<unistd.h>
int main(){
printf("hello,world");
//_exit(0)等价于_Exit(0);
//exit(0);
//return 0 等价于exit(0);
fflush(stdout); //加了这个也会刷新
_exit(0); //不会打印hello,world出来,不刷新缓冲区直接关闭,
}
等待子进程退出函数
在每个进程退出的时候,内核释放该进程所有的资源、包括打开的文件、占用的内存等。但是仍然为其保留一定的信息,这些信息主要主要指进程控制块PCB的信息(包括进程号、退出状态、运行时间等)。
父进程可以通过调用wait或waitpid得到它的退出状态同时彻底清除掉这个进程。
wait() 和 waitpid() 函数的功能一样,区别在于,wait() 函数会阻塞,waitpid() 可以设置不阻塞,waitpid() 还可以指定等待哪个子进程结束。
注意:一次wait或waitpid调用只能清理一个子进程,清理多个子进程应使用循环。
wait函数
#include <sys/types.h> #include <sys/wait.h> pid_t wait(int *status); 功能: 等待任意一个子进程结束,如果任意一个子进程结束了,此函数会回收该子进程的资源。 参数: status : 进程退出时的状态信息。 返回值: 成功:已经结束子进程的进程号 失败: -1
调用 wait() 函数的进程会挂起(阻塞),直到它的一个子进程退出或收到一个不能被忽视的信号时才被唤醒(相当于继续往下执行)。
若调用进程没有子进程,该函数立即返回;若它的子进程已经结束,该函数同样会立即返回,并且会回收那个早已结束进程的资源。
所以,wait()函数的主要功能为回收已经结束子进程的资源。
如果参数 status 的值不是 NULL,wait() 就会把子进程退出时的状态取出并存入其中,这是一个整数值(int),指出了子进程是正常退出还是被非正常结束的。
int status; wait(&status);
这个退出信息在一个 int 中包含了多个字段,直接使用这个值是没有意义的,我们需要用宏定义取出其中的每个字段。
宏函数可分为如下三组:
\1) WIFEXITED(status)
为非0 → 进程正常结束
WEXITSTATUS(status)
如上宏为真,使用此宏 → 获取进程退出状态 (exit的参数)
\2) WIFSIGNALED(status)
为非0 → 进程异常终止
WTERMSIG(status)
如上宏为真,使用此宏 → 取得使进程终止的那个信号的编号。
\3) WIFSTOPPED(status)
为非0 → 进程处于暂停状态
WSTOPSIG(status)
如上宏为真,使用此宏 → 取得使进程暂停的那个信号的编号。
WIFCONTINUED(status)
为真 → 进程暂停后已经继续运行
waitpid函数
#include <sys/types.h> #include <sys/wait.h> pid_t waitpid(pid_t pid, int *status, int options); 功能: 等待子进程终止,如果子进程终止了,此函数会回收子进程的资源。 参数: pid : 参数 pid 的值有以下几种类型: pid > 0 等待进程 ID 等于 pid 的子进程。 pid = 0 等待同一个进程组中的任何子进程,如果子进程已经加入了别的进程组,waitpid 不会等待它。 pid = -1 等待任一子进程,此时 waitpid 和 wait 作用一样。 pid < -1 等待指定进程组中的任何子进程,这个进程组的 ID 等于 pid 的绝对值。 status : 进程退出时的状态信息。和 wait() 用法一样。 options : options 提供了一些额外的选项来控制 waitpid()。 0:同 wait(),阻塞父进程,等待子进程退出。 WNOHANG:没有任何已经结束的子进程,则立即返回。 WUNTRACED:如果子进程暂停了则此函数马上返回,并且不予以理会子进程的结束状态。(由于涉及到一些跟踪调试方面的知识,加之极少用到) 返回值: waitpid() 的返回值比 wait() 稍微复杂一些,一共有 3 种情况: 1) 当正常返回的时候,waitpid() 返回收集到的已经回收子进程的进程号; 2) 如果设置了选项 WNOHANG,而调用中 waitpid() 发现没有已退出的子进程可等待,则返回 0; 3) 如果调用中出错,则返回-1,这时 errno 会被设置成相应的值以指示错误所在,如:当 pid 所对应的子进程不存在,或此进程存在,但不是调用进程的子进程,waitpid() 就会出错返回,这时 errno 被设置为 ECHILD;
孤儿进程
父进程运行结束,但子进程还在运行(未运行结束)的子进程就称为孤儿进程(Orphan Process)。
每当出现一个孤儿进程的时候,内核就把孤儿进程的父进程设置为 init ,而 init 进程会循环地 wait() 它的已经退出的子进程。这样,当一个孤儿进程凄凉地结束了其生命周期的时候,init 进程就会代表党和政府出面处理它的一切善后工作。
因此孤儿进程并不会有什么危害。
僵尸进程
进程终止,父进程尚未回收,子进程残留资源(PCB)存放于内核中,变成僵尸(Zombie)进程。
这样就会导致一个问题,如果进程不调用wait() 或 waitpid() 的话, 那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵尸进程,将因为没有可用的进程号而导致系统不能产生新的进程,此即为僵尸进程的危害,应当避免。
进程替换
在 Windows 平台下,我们可以通过双击运行可执行程序,让这个可执行程序成为一个进程;而在 Linux 平台,我们可以通过 ./ 运行,让一个可执行程序成为一个进程。
但是,如果我们本来就运行着一个程序(进程),我们如何在这个进程内部启动一个外部程序,由内核将这个外部程序读入内存,使其执行起来成为一个进程呢?这里我们通过 exec 函数族实现。
exec 函数族,顾名思义,就是一簇函数,在 Linux 中,并不存在 exec() 函数,exec 指的是一组函数,一共有 6 个:
#include <unistd.h> extern char **environ; //...表示变参 int execl(const char *path, const char *arg, .../* (char *) NULL */); int execlp(const char *file, const char *arg, ... /* (char *) NULL */); int execle(const char *path, const char *arg, .../*, (char *) NULL, char * const envp[] */); int execv(const char *path, char *const argv[]); int execvp(const char *file, char *const argv[]); int execvpe(const char *file, char *const argv[], char *const envp[]); int execve(const char *filename, char *const argv[], char *const envp[]);
其中只有 execve() 是真正意义上的系统调用,其它都是在此基础上经过包装的库函数。
exec 函数族的作用是根据指定的文件名或目录名找到可执行文件,并用它来取代调用进程的内容,换句话说,就是在调用进程内部执行一个可执行文件。
进程调用一种 exec 函数时,该进程完全由新程序替换,而新程序则从其 main 函数开始执行。因为调用 exec 并不创建新进程,所以前后的进程 ID (当然还有父进程号、进程组号、当前工作目录……)并未改变。exec 只是用另一个新程序替换了当前进程的正文、数据、堆和栈段(进程替换)。
exec 函数族使用说明
exec 函数族的 6 个函数看起来似乎很复杂,但实际上无论是作用还是用法都非常相似,只有很微小的差别。
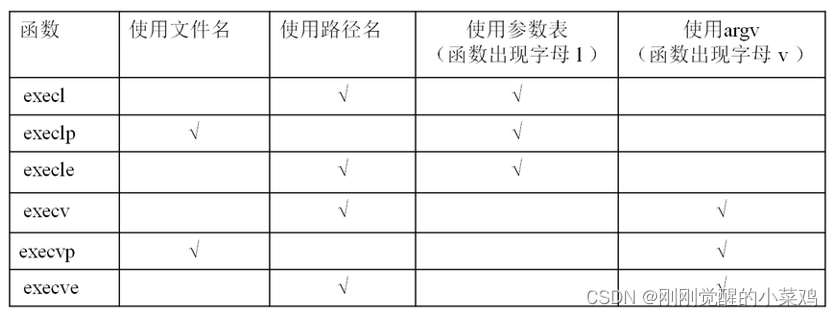
补充说明:
| l(list) | 参数地址列表,以空指针结尾 |
|---|---|
| v(vector) | 存有各参数地址的指针数组的地址 |
| p(path) | 按 PATH 环境变量指定的目录搜索可执行文件 |
| e(environment) | 存有环境变量字符串地址的指针数组的地址 |
exec 函数族与一般的函数不同,exec 函数族中的函数执行成功后不会返回,而且,exec 函数族下面的代码执行不到。只有调用失败了,它们才会返回 -1,失败后从原程序的调用点接着往下执行。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









