






一、基本介绍
1、SQL是一种超高级的非过程化语言。
2、SQL语句以 ; 结束。MySQL中的命令不区分大小写。
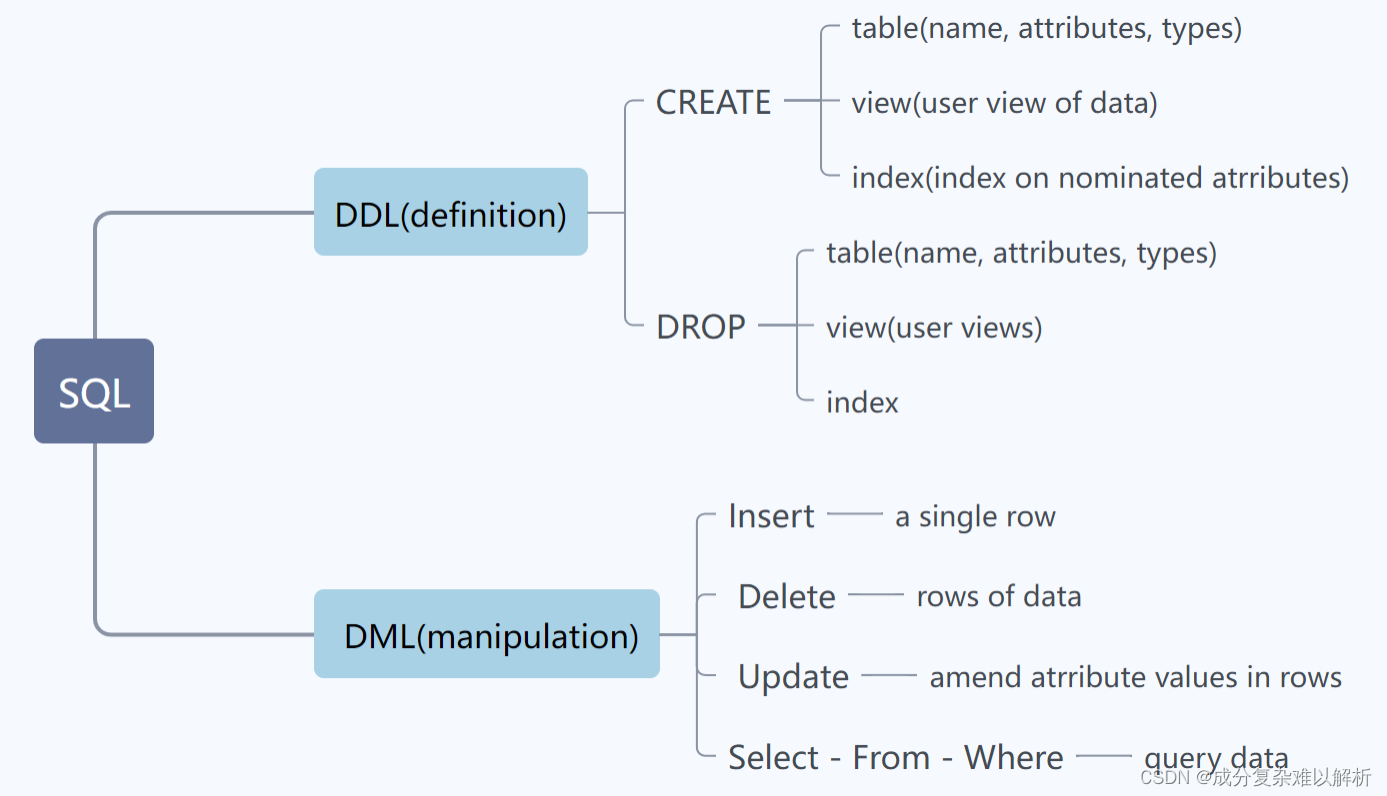
3、分类
4、基本数据类型
- char(n)
- varchar(n)
- int
- smallint
- numeric(p, d)
- real
- double precision
字符串数据在插入表中时需要加单引号
5、定义数据库
CREATE DATABASE IF NOT EXISTS BarDrink
DEFAULT CHARACTER SET utf8
DEFAULT COLLATE utf8_general_ci;
show databases;6、定义/修改关系模式并向表中插入数据
use bardrink;
-- CREATE TABLE name (list of elements);
CREATE TABLE sells(
bar CHAR(20),
beer VARCHAR(20),
price REAL,
PRIMARY KEY(bar, beer)
);
-- ALTER TABLE <table_name> ADD <attr_name> <attr_type>
ALTER TABLE Bars ADD phone CHAR(16) DEFAULT 'unlisted';
-- ALTER TABLE <table_name> DROP COLUMN <attr_name>
ALTER TABLE Bars DROP COLUMN license;
show tables;
insert into sells values("Siz", "Bud", 13);
select * from sells;
7、DROP Objects
DROP DATABASE <datebase_name>
DROP TABLE <table_name>
DROP VIEW
DROP INDEX
DROP TRIGGER
delete from <table_name>二、完整性约束(Integrity Constrains)
1、主键Primary Key
注意,MySQL不支持将PRIMARY KRY写在属性的声明后,必须写成单独的语句。
-- within the declaration of an attribute
CREATE TABLE Beers (
name CHAR(20) PRIMARY KEY,
manf CHAR(20)
);
-- as an element of the schema
-- more than one attr in one PRIMARY KEY
CREATE TABLE sells(
bar CHAR(20),
beer VARCHAR(20),
price REAL,
PRIMARY KEY(bar, beer)
);
/*
[PRIMARY KEY(bar, beer)] is not same with
[bar CHAR(20) PRIMARY KEY, beer VARCHAR(20) PRIMARY KEY,]
*/2、唯一键Unique
-- within the declaration of an attribute
CREATE TABLE Beers (
name CHAR(20) UNIQUE,
manf CHAR(20)
);
-- as an element of the schema
-- more than one attr in one UNIQUE
CREATE TABLE sells(
bar CHAR(20),
beer VARCHAR(20),
price REAL,
UNIQUE(bar, beer)
);
/*
[UNIQUE(bar, beer)] is not same with
[bar CHAR(20) UNIQUE, beer VARCHAR(20) UNIQUE,]
*/3、主键与唯一键的区别和联系
| 主键 | 唯一键 |
| 不能有空值 | 可以有一个空值(视为特殊值) |
| 一个关系只能有一个主键 | 一个关系可能有多个唯一键 |
P.S. 一些DBMS会为主键自动创建索引并进行优化,但唯一键不会。
4、外键Foreign Key
被参照的属性一定被声明为主键或唯一键。
- REFERENCES <relation> (<attr>)
- FOREIGN KEY (<list of attrs>) REFERENCES <relation> (<attrs>)
-- within the declaration of an attribute
CREATE TABLE Sells (
bar CHAR(20),
beer CHAR(20) REFERENCES Beers(name),
price REAL );
-- as element
CREATE TABLE Sells (
bar CHAR(20),
beer CHAR(20),
price REAL,
FOREIGN KEY(beer) REFERENCES Beers(name));当外键参考的是被参照表的主键,并且两表中属性名相同,可以只写被参照表的表名、省略属性,默认参考被参照表的主键。
5、发生违反外键约束的修改的处理
(1)如果参照表中的修改违反了外键约束?
修改被拒绝。
(2)如果被参照表中的修改导致参照表中出现违反外键约束的记录?
- Default(默认拒绝)
- Cascade(级联:删除参照表对应元组,或修改参照表中数据项为被参照表中新的名称)
- Set NUll(将不符合外键约束的数据项设置为空值)
被参照表中的修改导致参照表中出现违反外键约束的记录有两种情况:删除某元组或修改对应地主键/唯一键(中的一个属性)的名称。因此在建表时需要预设解决方案,没有预设则为默认方案。
CREATE TABLE Sells (
bar CHAR(20),
beer CHAR(20),
price REAL,
FOREIGN KEY(beer) REFERENCES Beers(name)
// ON DELETE CASCADE 被参照表删除某一项 -> 参照表中也删除
// ON UPDATE CASCADE 被参照表修改某一项 -> 参照表中也修改
// ON DELETE SET NULL 被参照表删除某一项 -> 参照表中设为空值
// ON UPDATE SET NULL 被参照表修改某一项 -> 参照表中设为空值
//仅可以写不超过一个DELETE和UPDATE
);6、NOT NULL & DEFAULT
属性数值非空。
CREATE TABLE Sells (
bar CHAR(20),
beer VARCHAR(20) DEFAULT 'HouseBeer',
price REAL NOT NULL,
PRIMARY KEY (bar,beer)
);
insert into Sells(bar,price) values("JOE", 10); --SUCCESS!!!
insert into Sells(bar) values("JOE"); --ERROR!!!7、CHECK
(1)基于属性的CHECK约束
CREATE TABLE Sells (
bar CHAR(20),
beer CHAR(20) CHECK (beer IN (SELECT name FROM Beers)),
price REAL CHECK (price <= 5.00)
);与外键的区别:
外键是两张表的事,任何会导致违反外键约束的修改都会使外键约束生效;
但CHECK只在被声明的那个元素发生修改的时刻起作用,也就是修改参照表的时候发挥作用,但修改被参照表时不会起作用,因此CHECK不能保证该条件一直被满足。
(2)基于元组的CHECK约束
--作为建表语句的一部分
CREATE TABLE Sells (
bar CHAR(20),
beer CHAR(20),
price REAL,
CHECK (bar = 'Joe''s Bar' OR price <= 5.00)
);
--创建完表后,通过ALTER TABLE增加的约束
ALTER TABLE Sells ADD CHECK (bar='Joe’s Bar' or beer <> 'Miller');三、查询(SQLQueries)
1、SELECT FROM WHERE
SELECT <attr_list or *>
FROM <table_name>
WHERE <condition_list>
-- Note: no WHERE clause is OK.
-- Conditions in WHERE clause can use logical operators.(AND, OR, NOT)
-- Comparison operators: =, <>, <, >, <=, >=
SELECT price
FROM Sells
WHERE bar = 'Joe''s Bar' AND beer = 'Bud';
-- 注意写法:'Joe''s Bar'表达的字符串其实是Joe's Bar2、AS(输出列重命名)
-- 任何有意义的表达都可以作为SELECT的内容
SELECT bar, beer, price*120 AS priceInYen
FROM Sells;
-- 输出时price->priceInYen 【bar beer priceInYen】
-- an answer with a particular string in each row
-- Likes(drinker, beer)
SELECT drinker, 'likes Bud' AS whoLikesBud
FROM Likes
WHERE beer = 'Bud';
--【drinker whoLikesBud】
3、SQL Injection
--表示单行注释
--已知系统中已有一个Admin的管理者帐号
--method1
--输入Admin'--
select * from member where UID ='Admin'-- ' And Passwd =' '
--method2
--输入'or 1=1 --
select * from member where UID =''or 1=1 --And Passwd =' '4、LIKE 模式匹配:Patterns
(1)SQL可以使用LIKE关键字进行模式比较,当属性的字符串与模式相匹配时,LIKE为真。
(2)%表示任意字符串,_表示任意一个字符。
select *
from employee
where empname like '李%';
-- 李姓员工的所有信息5、NULL 空值规则:三值逻辑
(1)空值的含义
- Unknown:不知道
- Inappliance:不适用的属性列
(2)三值(TRUE, FALSE, UNKNOWN)逻辑
- 任意值与空值比较 -> unknown
- 只有当where子句中的条件为true时,满足所有where子句中的条件的元组才会返回,false或unknown都不会
| true | 1 | and | 求min |
| unknown | 1/2 | or | 求max |
| false | 0 | not(x) | 求(1-x)即取反 |
SELECT bar
FROM Sells
WHERE price IS NOT NULL;6、Order By 输出排序
ORDER BY <attr> <rank>
- ASC (升序,默认值)
- DESC (降序)
SELECT empname
FROM Employee
WHERE deptno='d2'
ORDER BY empno DESC;7、Multi-relation Queries 多表连接查询
SQL支持在多个关系表中查询,可以将涉及的表全部写在FROM中。
出现重名属性时消除歧义的方法:relation.attribute
(1)普通连接
SELECT beer
FROM Frequents, Likes
WHERE bar = 'Joe''s Bar' AND Frequents.drinker = Likes.drinker;(2)自然连接
对于两个关系中,具有相同名称与数值的属性做连接,并且两个等值属性有一个出现在结果集中。
-- 工作地在天津的所有雇员和部门信息
select *
from employee natural join department
where location='天津';
-- 对比普通连接
select *
from employee, department
where location='天津'and department.deptno=employee.deptno;8、Explicit Tuple Variables(显式元组变量)
有时需要引用一个关系的两个或更多部分,这时可以用元组变量作为关系的别名,也就是把数据表/属性进行拷贝并重命名。
SELECT b1.name, b2.name
FROM Beers b1, Beers b2
-- 对Beers的两个副本进行重命名,然后在副本上进行查询
WHERE b1.manf = b2.manf AND b1.name < b2.name;
-- b1.name < b2.name作用是避免返回结果冗余
四、子查询(Subqueries)
1、概念
一个查询结果集可以出现在另一个where子句中。
SELECT bar
FROM Sells
WHERE beer = 'Miller' AND price =
(SELECT price FROM Sells WHERE bar = 'Joe''s Bar' AND beer = 'Bud');
-- price后面能用=是因为已知该子查询结果一定只有一个2、IN(元组在关系中)
-- 子查询
SELECT *
FROM Beers
WHERE name IN (SELECT beer FROM Likes WHERE drinker = 'Fred');
-- 这里用IN而不用=!因为不知道子查询结果有多少
-- 多表查询
SELECT name, manf
FROM Beers, Likes
WHERE drinker='Fred' AND beer=name;有些SQL运算符可以作用在关系上,但这些关系只能是子查询不能是关系本身。
子查询:存储效率较高(先装载子查询并保存结果再装载Beers),查询效率较高
多表查询:查询效率较低,需要同时将两表装载到内存中
3、EXIST(当且仅当关系非空时为1)
--Find the beers that are the unique beer by their manufacturer.
SELECT name
FROM Beers b1
WHERE NOT EXISTS
(SELECT * FROM Beers WHERE manf=b1.manf AND name<>b1.name);
--查找部门中只有一名员工的员工姓名
select empname
from employee e1
where not exists
(select * from employee where deptno=e1.deptno and empname<>e1.empname);4、ANY(at least one)
x = ANY(<relation>)
-- return true <=> x equals at least one tuple in the relation.
-- or x is a member of the relation (x IN<relation>).
x > ANY(<relation>)
-- return true <=> x is larger than at least one tuple in the relation.
--Find the beer(s) not sold for the lowest price.
SELECT beer
FROM Sells
WHERE price > ANY(SELECT price FROM Sells);5、ALL(every)
x <> ALL(<relation>)
--is true <=> for every tuple t in the relation, x is not equal to t.
--x is not a member of the relation (x NOT IN <relation>)
x >= ALL(<relation>)
--is true <=> there is no tuple larger than x in the relation.
--Note tuples must have one component only
--Find the beer(s) sold for the highest price.
SELECT beer
FROM Sells
WHERE price >= ALL(SELECT price FROM Sells);
--选出预算最小的项目,返回项目名称
select projectname
from project
where budget<=ALL(select budget from project);四、并,交,差(Union, Intersection, Difference)
1、概念
语义相同的集合才能并、交、差操作。
| UNION | 【并】将不同表中相同列中查询的数据展示出来(自动去重排序,影响性能) |
| INTERSECT | 【交】返回查询结果中相同的部分既交集(自动去重) |
| EXCEPT | 【差】A EXCEPT B 即A-B(自动去重) |
P.S. UNION ALL:将不同表中相同列中查询的数据展示出来(直接返回合并结果,有重复)
(SELECT * FROM Likes)
INTERSECT
(SELECT drinker, beer FROM Sells, Frequents WHERE Frequents.bar = Sells.bar);2、语义转换
| Set | Union, intersection, difference | 不允许重复结果 |
| Bag | select-from-where | 允许重复结果 |
可使用DISTINCT显示地将包的语义转为集合语义,从而去重。
存在比较、去重两步,代价较高。
-- Employee(empno, empname, deptno) [have 7 tuples]
select e1.empname from employee e1,employee e2;
-- return 49 rows
select distinct e1.empname from employee e1,employee e2;
-- reuturn 7 rows (delete same rows)
五、Aggregations, Grouping, HAVING
1、聚合类别
| SUM | 求和(不考虑空值) | AVG | 求平均(不考虑空值) |
| MAX | 求最大值(不考虑空值) | MIN | 求最小值(不考虑空值) |
| COUNT | 计数(不考虑空值) | COUNT(*) | 计数(考虑空值) |
2、聚合示例
select min(budget) from project;
select count(job) from workson;3、分组作用
将FROM-WHERE子句的结果按照GROUP-BY <attr_list>的属性进行分组。
SELECT-FROM-WHERE-GROUP BY
4、分组示例
-- Find the average sales price for each beer.
SELECT beer, AVG(price)
FROM Sells
GROUP BY beer;
-- Find, for each drinker, the average price of Bud at the bars they frequent.
SELECT drinker, AVG(price)
FROM Frequents, Sells
WHERE beer='Bud' AND Frequents.bar=Sells.bar
GROUP BY drinker;
-- 每个项目由几名员工完成
select projectno,count(*)
from workson
group by projectno;5、SELECT Lists With Aggregation
SQL要求SELECT的每个字句必须被聚合或者出现在GROUP-BY字句中。
-- Each element of a SELECT clause must either be aggregated
-- or appear in a group-by clause.
-- Illegal
SELECT bar, MIN(price)
FROM Sells
WHERE beer = 'Bud';6、HAVING用法
HAVING字句用于分组的条件的选择。
-- Find the average price of those beers that are either
-- served in at least 3 bars or manufactured by Busch.
SELECT beer, AVG(price)
FROM Sells
GROUP BY beer
HAVING COUNT(*) >= 3
OR
beer IN (SELECT name FROM Beers WHERE manf = 'Busch');














 785
785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









