









- Mini-batch gradient descent
- Understanding mini-batch gradient descent
mini-batch大小为1时,即为SGD
数据集小于2000,使用batch。大数据集时,mini-batch大小选择,64,128,256,512等2的指数级。 Exponentially weight averages
加权的移动平均法,选取各时期权重数值为递减指数数列的均值方法。指数平滑法解决了移动平均法需要几个观测值和不考虑t—n前时期数据的缺点,通过某种平均方式,消除历史统计序列中的随机波动,找出其中主要的发展趋势。
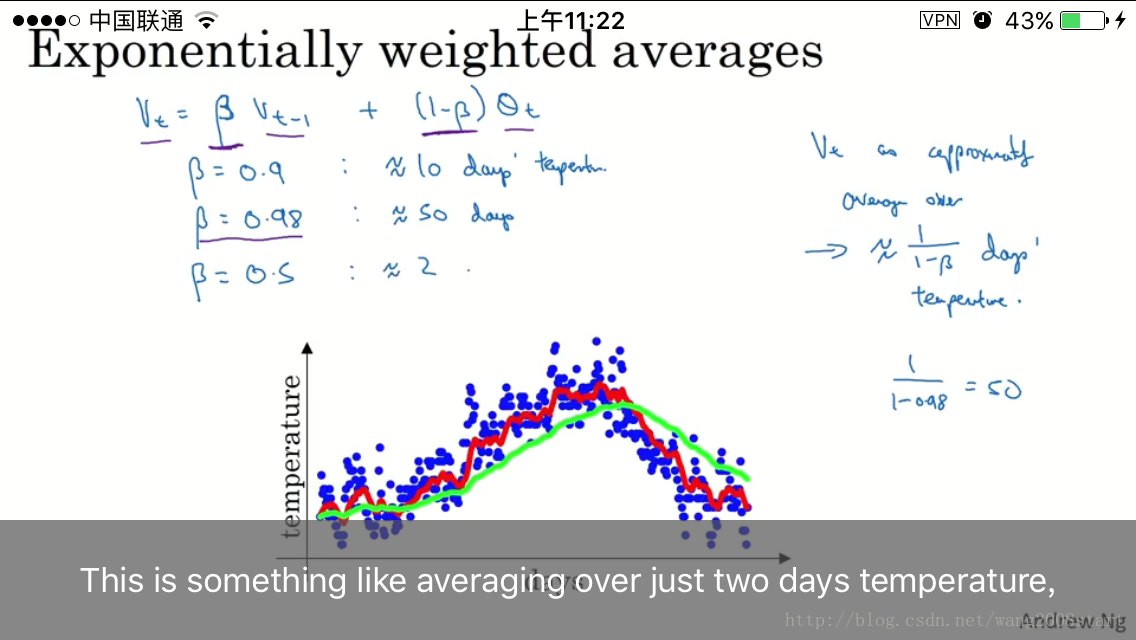
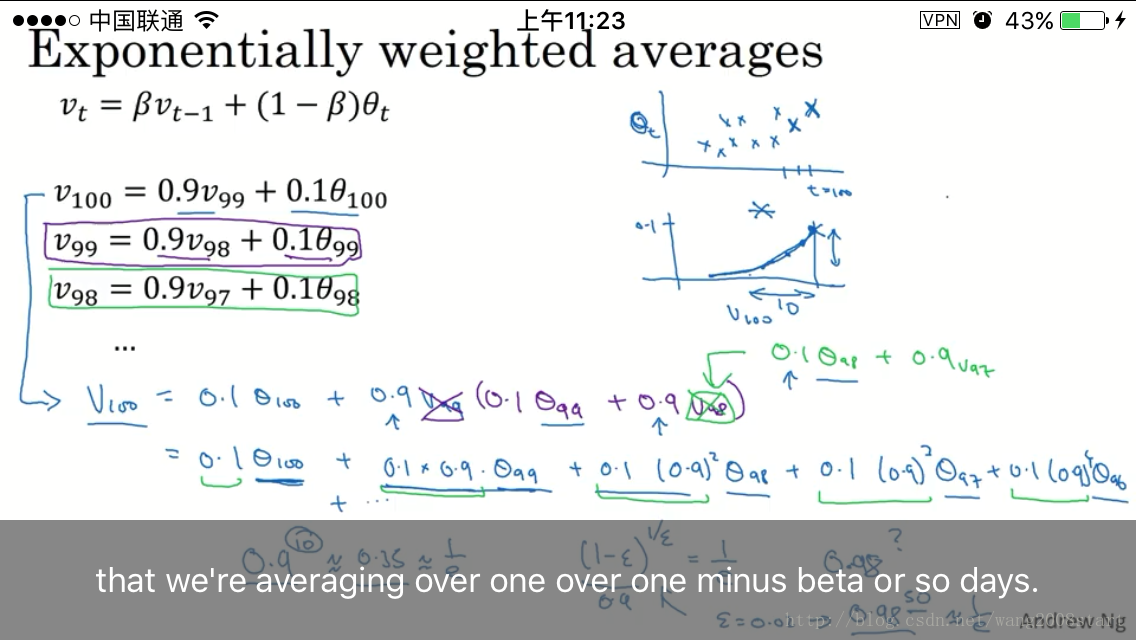
指数加权平均: vt=βvt−1+(1−β)θt
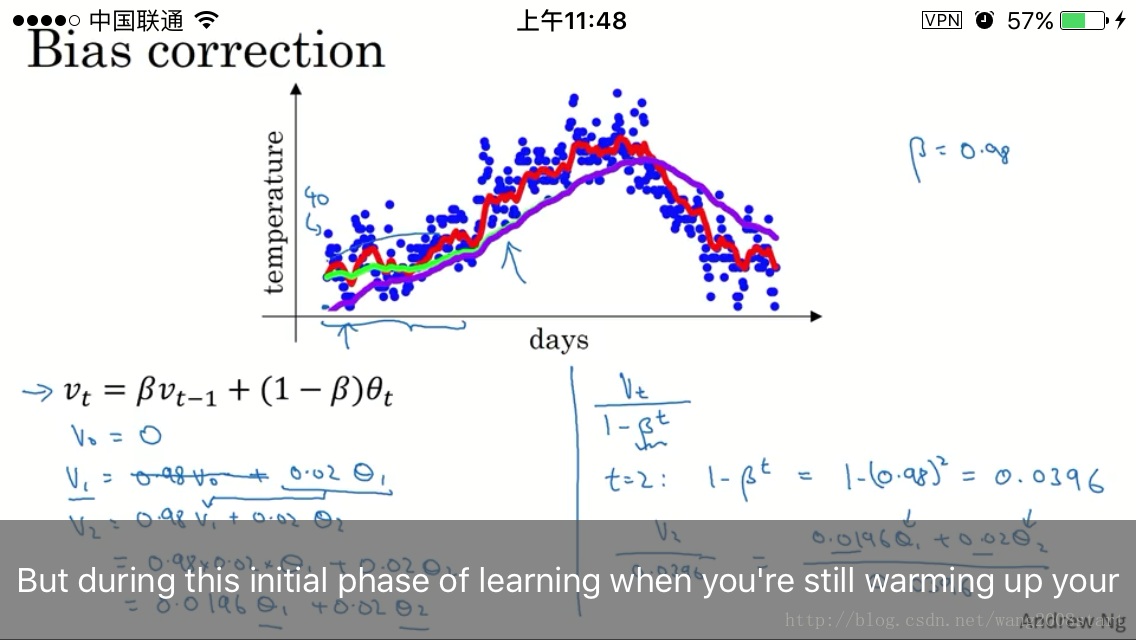
bias correction: vt=vt1−βt
窗口: 11−β
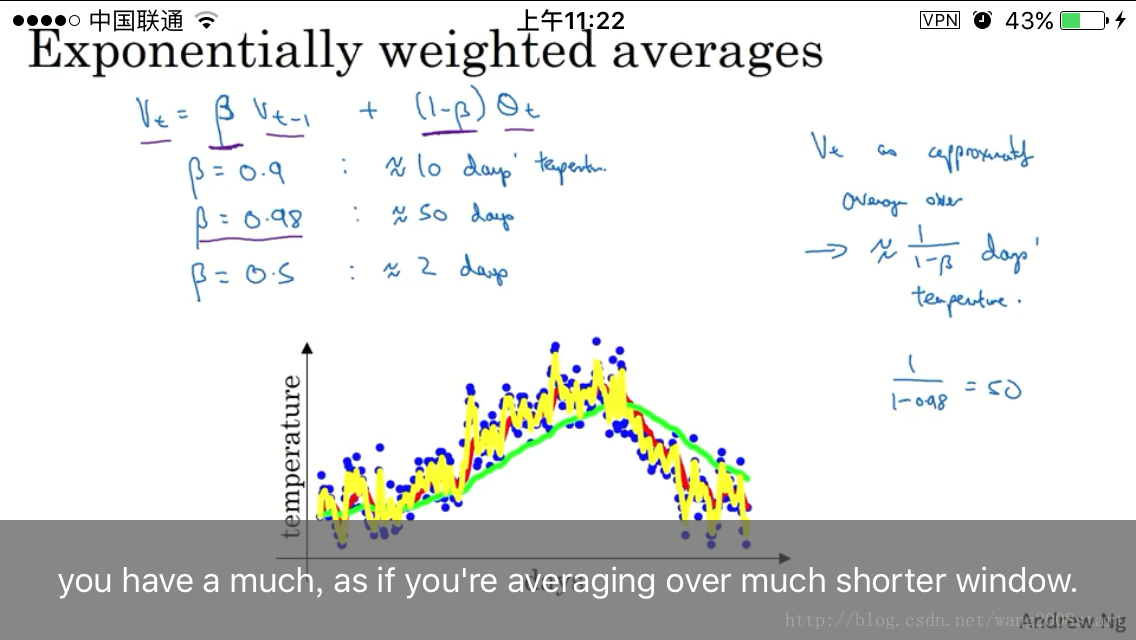
当beta设置为0.98时比0.9更平滑,受历史平均值影响更大.
当beta设置为0.5时,标识时间窗口变为2.
0.9^10近似于0.35,so,对于指数加权平均,beta=0.9时,只有近10天的数据会产生影响,因为超过10天的数据会产生小于1/3的影响
0.98^50近似于0.36,对于beta=0.98时,近50天的数据都会产生影响.
Understanding exponetially weighted averages
- Bias correction in exponentially weighted averages
bias correction: vt=vt1−βt
- Gradient descent with momentum
动量法,思想是前面的指数加权平均,梯度作为当前值,动量作为历史值
- RMSprop
Adm optimization algorithm
Learning rate decay
The problem of local optimal
Andrew-Coursera-DL课程-笔记part2-2(Optimization algorithms)
最新推荐文章于 2024-08-21 09:21:33 发布























 1404
1404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









