











传统的方法是矩阵降维和矩阵分解作为表示,但是不适用于大型网络。
借鉴 nlp 中的处理思路,先 随机游走,处理成节点序列,再使用节点在上下文中的表示。缺点:无法使用节点自身的信息。
本文提出一种直观的方法是分别单独学习文本表示和网络结构,然后把两种独立的表示合并在一起。
将网络的邻接矩阵和训练好的内容表示作为输入,经过 VAE 得到 embedding 表示。
联合训练模型中的VAE的 loss,两个 KL 散度分别计算。

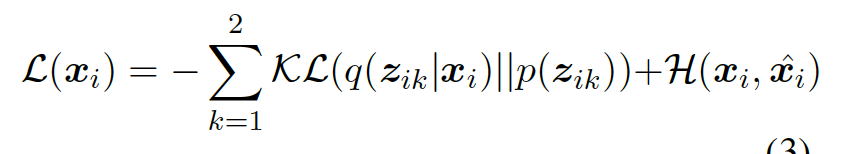
论文缺点:更多是思维的创新,实际操作的可行性有待验证,adjacency matrix 的大小变化等;















 3013
3013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









