







Apache Iceberg Tables中文教程3-Evolution
文章目录
Evolution
Iceberg支持就地表格演进。您可以像使用SQL一样演进表格模式,即使是在嵌套结构中,或者在数据量发生变化时更改分区布局。Iceberg不需要昂贵的操作,比如重写表格数据或迁移到新表。
例如,Hive表的分区无法更改,因此从每日分区布局移动到每小时分区布局需要创建一个新表。并且由于查询依赖于分区,必须为新表重写查询。在某些情况下,即使是简单的更改,比如重命名列,要么不受支持,要么可能导致数据正确性问题。
Schema evolution
Iceberg支持以下模式演进更改:
- 添加:向表格或嵌套结构中添加新列
- 删除:从表格或嵌套结构中删除现有列
- 重命名:重命名现有列或嵌套结构中的字段
- 更新:扩展列、结构字段、映射键、映射值或列表元素的类型
- 重新排序:更改嵌套结构中的列或字段顺序
Iceberg模式更新是元数据更改,因此执行更新不需要重写数据文件。
请注意,映射键不支持添加或删除会改变相等性的结构字段。
Correctness
Iceberg保证模式演进更改是独立的,没有副作用,并且无需重写文件:
- 添加的列从不读取其他列中的现有值。
- 删除列或字段不会更改任何其他列中的值。
- 更新列或字段不会更改任何其他列中的值。
- 更改结构中的列或字段顺序不会更改与列或字段名称相关联的值。
- Iceberg使用唯一ID跟踪表格中的每个列。当您添加列时,它被分配一个新的ID,因此不会错误地使用现有数据。
通过名称跟踪列的格式如果重新使用名称,则可能无意中取消删除列,这违反了规则#1。
通过位置跟踪列的格式无法删除列而不更改用于每个列的名称,这违反了规则#2。
Partition evolution
Iceberg表格的分区可以在现有表格中进行更新,因为查询不直接引用分区值。
当您演进分区规范时,使用早期规范写入的旧数据保持不变。使用新规范以新布局写入新数据。每个分区版本的元数据被单独保留。因此,当您开始编写查询时,您将获得拆分规划。这是每个分区布局都使用其派生的过滤器分别计划文件的拆分。下面是一个虚构示例的可视化表示:
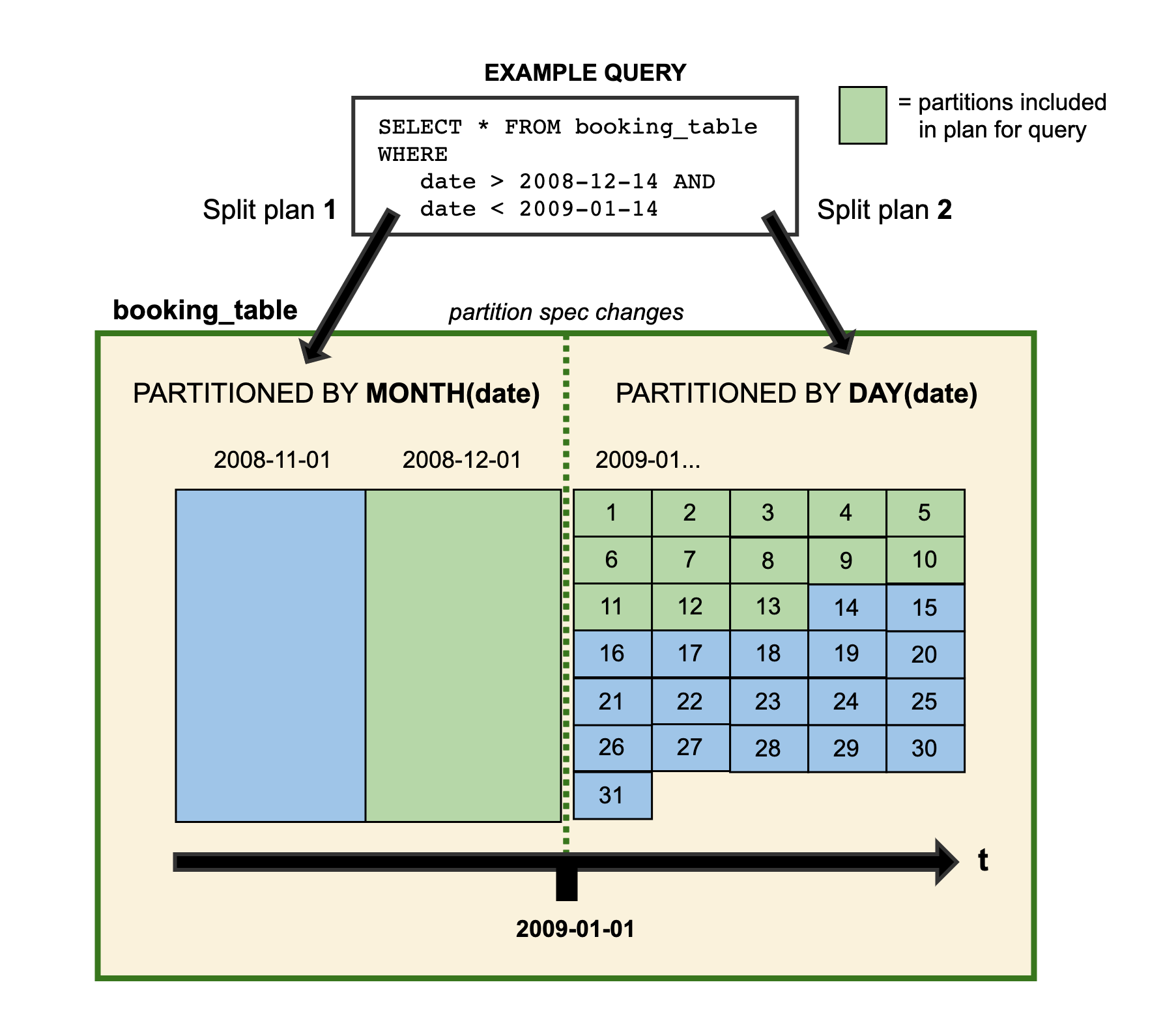
Iceberg使用隐藏分区,因此您不需要为特定的分区布局编写查询以获得快速查询。相反,您可以编写选择所需数据的查询,并且Iceberg会自动修剪掉不包含匹配数据的文件。
分区演进是一种元数据操作,不会急切地重写文件。
Iceberg的Java表格API提供了updateSpec API来更新分区规范。例如,以下代码可以用于更新分区规范,添加一个将id列值放入8个桶中并删除现有分区字段category的新分区字段:
Table sampleTable = ...;
sampleTable.updateSpec()
.addField(bucket("id", 8))
.removeField("category")
.commit();
Spark通过其ALTER TABLE SQL语句支持更新分区规范,请在Spark SQL中获取更多详细信息。
Sort order evolution
类似于分区规范,Iceberg排序顺序也可以在现有表格中进行更新。当您演进排序顺序时,早期按顺序写入的旧数据保持不变。引擎始终可以选择按最新的排序顺序或未排序的方式写入数据,如果排序过程过于昂贵。
Iceberg的Java表格API提供了replaceSortOrder API来更新排序顺序。例如,以下代码可以用于创建一个新的排序顺序,其中id列按升序排序,null值排在最后,category列按降序排序,null值排在最前:
Table sampleTable = ...;
sampleTable.replaceSortOrder()
.asc("id", NullOrder.NULLS_LAST)
.dec("category", NullOrder.NULL_FIRST)
.commit();
Spark通过其ALTER TABLE SQL语句支持更新排序顺序,请在Spark SQL中获取更多详细信息。
pache.org/docs/latest/spark-ddl/#alter-table–write-ordered-by)中获取更多详细信息。
















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











