







1、Iceberg简介
- 本质:一种数据组织格式
1.1、应用场景
①面向大表:单表包含数十个PB的数据
②分布式引擎非必要:不需要分布式SQL引擎来读取或查找文件
③高级过滤:使用表元数据,使用分区和列级统计信息修建数据文件
1.2、集成方式:通过Lib与Flink、Spark集成。
Icrbeg非常轻量级,与Flink、Spark整合时通过一个Jar包整合。
2、数据存储文件解析
- 核心:每一个对表产生改变的操作commit后,都会产生一份新的metadata files,这包括一个vN.metadata.json + 一个manifest list(例如:snap-242516093407225541-1-4bbf0565-406b-428a-aad7-e32993df0fef.avro) + 一个或多个manifest file(例如:4bbf0565-406b-428a-aad7-e32993df0fef-mN.avro)
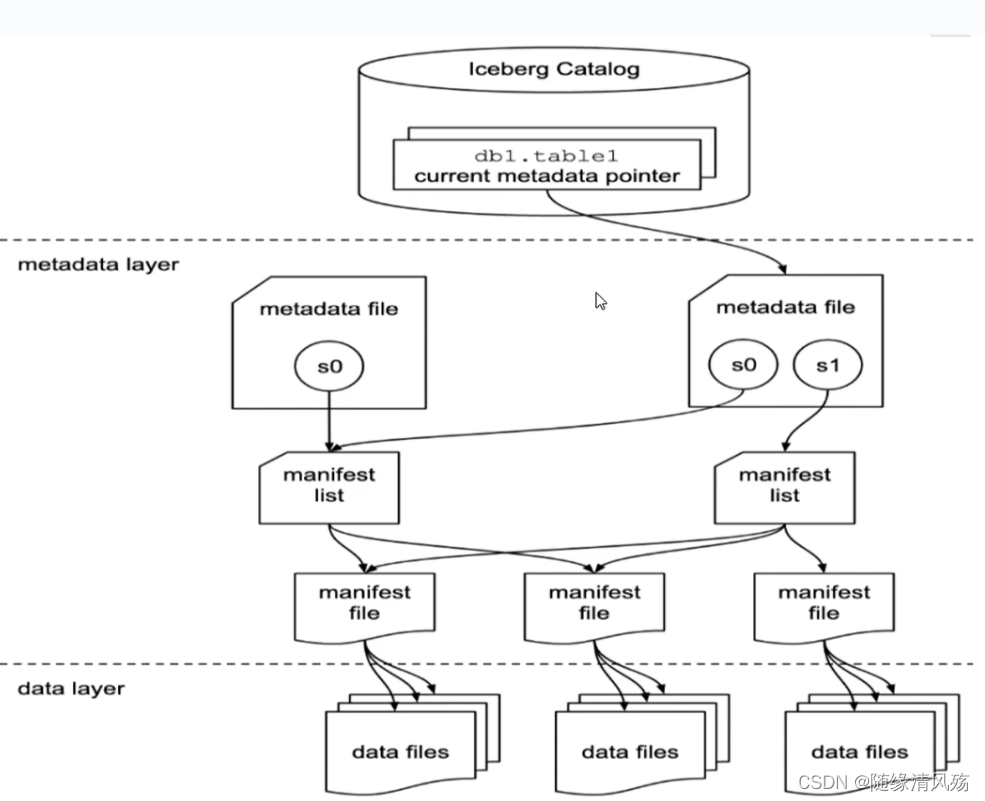
- 下图为Iceberg的表格式:
- Ⅰ、s0、s1代表的是表Snapshot信息,每个表示当前操作的一个快照,每次Commit都会生成一个快照Snapshot。
- Ⅱ、每个Snapshot快照对应的一个manifest list元数据文件。
- Ⅲ、每个manifest list包含多个Manifest元数据文件。
- Ⅳ、每个Manifest中记录了当前操作生成数据所对应的文件地址,也就是data file地址。
2.1、元数据层
①Snapshot(表快照)
- 文件描述:snap-xxxx.avro,当生成一个parquent文件时生成一个快照
快照代表一张表在某个时刻的状态。每个快照里面会列出表在某个时刻的所有data files列表。data files是存储在不同manifest files里面,manifest files是存储在一个Manifest list文件里面,一个Manifest list文件代表一个快照。
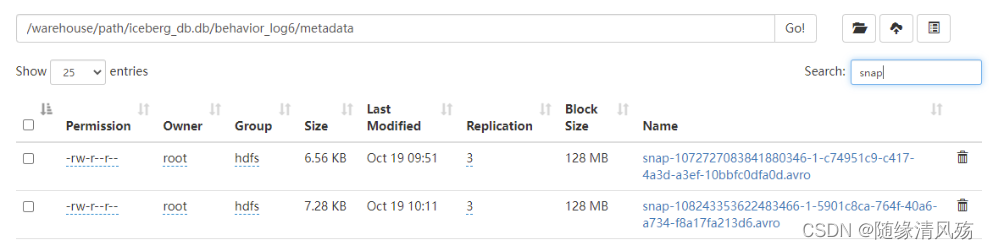
②manifest list(清单列表)
manifest list是一个元数据文件,它列出构建快照(Snapshot)的清单(Manifest file)。这个元数据文件中存储的是Manifest file列表,每个Manifest file占据一行,每行中存储了Manifest file的路径、其存储的数据文件(data files)的分区范围,增加了几个数据文件、删除了几个数据文件等信息。

注意事项:相关统计信息可以在扫描表数据时过滤掉不必要的文件。
③manifest file(清单文件)
- 文件描述:XXX-m0.avro,每当生成一个parquent文件时生成一个快照。

Manifest file是一个元数据文件,它列出了组成快照(Snapshot)的数据文件(data files)的列表信息。每行都是每个数据文件的详细描述,包括数据文件的状态、文件路径、分区信息、列级的统计信息(比如每列的最大最小值、空值数等)、文件的大小以及文件里面数据行数等信息。
- 注意事项:其中列级别的统计信息可以在扫描表数据时过滤掉不必要的文件。
2.2、数据层
数据文件文件是Apache Icberg表真实存储数据的文件,一般在表的数据存储目录的data目录下,如果文件格式选择的是Parquent,那么文件是以".parquent"结尾。

- 重点:每次Commit都会生成一个Parquent文件。
- 注意事项:目前支持parquent、ORC、Avro文件格式
3、数据后端存储解析
- 表元数据存储:存储在Hive Metastore中,复用了HMS模型

通过storage handler实现了外表创建,按照前面对表的类型划分,就是 managed non-native。
4、Iceberg表特性
(1)分区与隐藏分区
(2)表演化
(3)模式演化
(4)分区演化
(5)列顺序演化
5、Iceberg Catalog
- 类别:包括Hive Catalog、Hadoop Catalog、CacheCatalog和JDBC Catalog四种
5.1、Hive Catalog
Hive Catalog将表的元数据信息存储在Hive Metastore,为了兼容HMS,Namespace必须包含table和database。
5.2、Hadoop Catalog
Hadoop Catalog将表的元数据信息存储在Hadoop之上,因为Hadoop支持存算分离,因此底层的数据文件可以是HDFS或者是S3这样的对象系统,对Hadoop Catalog来讲,定位一个表的位置,只需要提供表的路径即可,因为表的元信息都存储在文件中,比如TableIdentifier为[“test_table”,“test_db”,“test_nm1”,“test_nm2”]的表全路径
5.3、CacheCatalog
CacheCatalog将表的元数据信息存储在内存之上。
5.4、JDBC Catalog
JDBC Catalog将表的元信息存储在支持JDBC协议的数据库中,Flink的JDBC Catalog能够查询注册和查询外部JDBC数据源,而Iceberg的JDBC Catalog只是将本身的元数据存储在JDBC数据库中,Iceberg目前支持的数据来源也仅仅是Hadoop。

















 1621
1621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











