







频率分布
函数FreqDist
函数FreqDist方法获取在文本中每个出现的标识符的频率分布。通常情况下,函数得到的是每个标识符出现的次数与标识符的map映射
| 标识符 | 出现次数 |
|---|---|
| are | 209 |
| the | 660 |
| people | 550 |
fdist = FreqDist(text1)
fdist

FreqDist的常用函数
keys() #获取map对象的键值,返回一个数组
获取文本中最常出现的前20的词
vocabulary = fdist.keys()
vocabulary[1:20]
freq() #获取标识符的频率
获取词whale的频率
fdist.freq('whale') * 100
tabulate() 制表函数,将文本的出现次数绘制成一张二维表格,横向表格。函数首先绘制的是频率分布样本中出现频率最高的。如果给函数提供一个Integer参数P,那么函数将绘制前P个标识符。
参数cumulative用来设置次数是否累加
fdist.tabulate(20, cumulative=True) # 绘制前20个标识符,并出现次数累加

plot()函数绘制图,用法和tabulate相同。
fdist.plot(20, cumulativce=True)
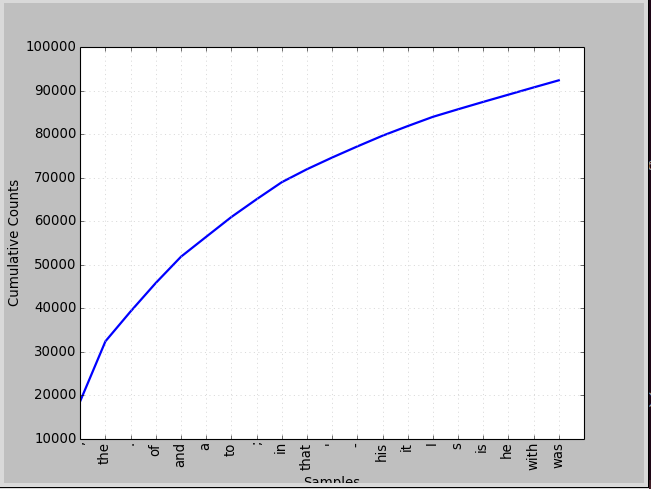
注意从图中可以看出一些介词和冠词占据了词总量的很大一部分,但是这些词却对我们了解文章没有什么帮助,所以要过滤掉这些词
inc(sample)函数,增加样本
fdist.inc(["In","the","beginning"])N()函数,获取样本总数
fdistN()max()函数,数值最大的样本
fdist.max()表达式:for sample in fdist: 以频率递减遍历样本
细粒度的选择词
采用集合论的一些方法和符号进行过滤筛选,这是最基本的。当然还有更好的方法。
#获取文章中词长度大于15的单词
V = set(text1)
long_words = [w for w n V if len(w) > 15]
现在我们已经知道如何找词的频率,并且也知道如何过滤掉长度过长的词。那么可以想象一下,一篇文章中较短的词,例如介词to,of等是一些高频词,但对了解文章无用。同样,一些长度过长的词,一般都是低频词,这些词也不能代表文章的特征。即这些词都不能作为文章的特征词汇。
fdist = FreqDist(text3)
sorted([w for w in set(text3) if len(w) > 7 and fdist[w] > 7])
获取文章中词长在7位以上且词频在7次以上的单词这些词往往能代表文章的特点。
单个元素操作
| 函数 | 含义 |
|---|---|
| s.startswith(t) | 测试s是否以t开头 |
| s.endswith(t) | 测试s是否以t结尾 |
| t in s | 测试s是否包含t |
| s.islower() | 测试s中所有字符是否都是小写字母 |
| s.isupper() | 测试s中所有字符是否都是大写字母 |
| s.isalpha() | 测试s中所有字符是否都是字母 |
| s.isalnum() | 测试s中所有字符是否都是字母或数字 |
| s.isdigit() | 测试s中所有字符是否都是数字 |
| s.istitle() | 测试s是否首字母大写 |
| s.upper() | 将s转成大写 |
| s.lower() | 将s转成小写 |
#以-ableness结尾的词
sorted([w for w in set(text1) if (not) w.endswith("ableness")])
#包含gnt的词
sorted([w for in set(text1) if (not) 'gnt' in w])
#首字符大写的词
sorted([w for w in set(text1) if (not) w.istitle()])
#完全由数字组成的词
sorted([w for w in set(text1) if (not) w.isdigit()])
#获取文本中的单词数量,过滤掉大小写,标识符,数字
len(set([w.lower() for w in text1 if w.isalpha()]))马尔科夫假设
马尔科夫假设,将其应用在词频的检测上就是:文章的单词往往存在依赖关系,即有很多的词是以词组的形式出现的。如red wine,而不是the wine,所以我们假设下一个词的出现之与其前一个词的出现有关,而与之前出现的词无关。(虽然这个假设存在问题,因为我们都知道,有很多的词组不是相邻依赖,而是非相邻依赖,而且词的出现还和上下文有关)
bgrams = nltk.bigrams(text2) #返回一个generate
bgfdist = FreqDist(list(bgrams)) #返回搭配的频率
bgfdist.plot(10) #查看前10个出现频率最高的搭配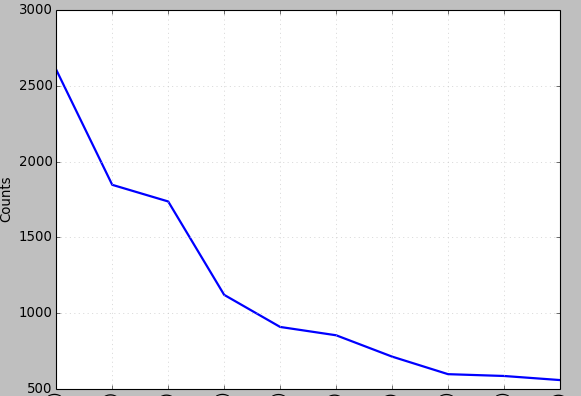

可以看出这里出现了我们处理单个词频率时出现的问题,介词和一些标识符
nltk给我们提供了获取这种二元组中最频繁搭配的函数——collocations
text2.collocations()
现在假设我们要统计一下在文章中单词长度为多少出现的次数对多。
fdist = FreqDist([len(w) for w in text1])
fdist.items()















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









