







1.NLTK入门
1.下载NLTK,可用pip install nltk,anaconda本身已经有NLTK了,可直接使用。
2.下载NLTK的范例文本,
import nltk
nltk.download()
#下载Collections下的book
3.使用基本函数
3.1 concordance 查找指定词
from nltk.book import *
text1.concordance("monstrous")3.2 similar 查找与monstrous相关的词,比如出现的上下文相同
text1.silimar("monstrous")3.3 common_contexts 共用2个或2个以上词汇的上下文
text2.common_contexts(["monstrous","very"])3.4 dispersion_plot 单词在文章中的分布
text4.dispersion_plot(["citizens","demoracy","freedom","duties","America"])
//需要用到Numpy和Matplotlib,好像Anaconda都有的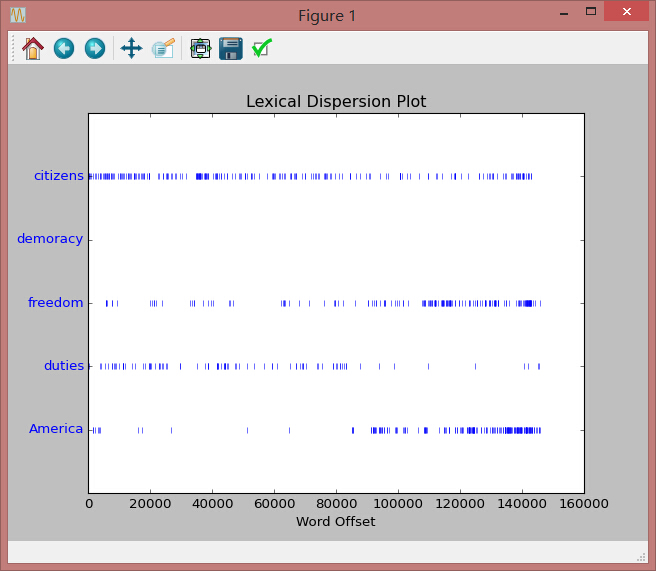
3.5 generate 产生随机文本
text3.generate()//重复使用源文本中常见的单词和短语,从而使我们能感觉到它的风格和内容。3.6.1 计数词汇
len(text3)//创世纪有44764个单词和标点符号,也被称作标识符
sorted(set(text3))//用sorted包裹set(text3),得到一个词汇条目的排序表,以各种标点符号开始,然后接着是以A开头的词汇。大写单词排在小写单词前面。通过求集合中各种项目的个数,可以间接获得词汇表的大小。用len获得。
len(set(text3))//27893.6.2 测量词汇丰富度
print len(text3)/len(set(text3)) #16.050197... 每个词平均出现了16次3.6.3 count 计算一个词在文本中出现的次数,和百分比
text3.count("smote") #5
100*text4.count('a')/len(text4) #1.4643....4.将文本当做词链表
链表的连接,append添加元素,索引(下标),index,切片
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









