一、torch
torch.cat and torch.stack
t1 = torch.tensor([1, 1, 1])
t2 = torch.tensor([2, 2, 2])
t3 = torch.tensor([3, 3, 3])
torch.cat((t1,t2,t3), dim=0)
输出: tensor([1, 1, 1, 2, 2, 2, 3, 3, 3])
torch.stack((t1,t2,t3), dim=0)
输出: tensor([[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])
print(t1.unsqueeze(0).shape)
print(t1.unsqueeze(0))
输出: torch.Size([1, 3])
tensor([[1, 1, 1]])
torch.cat(
(
t1.unsqueeze(0),
t2.unsqueeze(0),
t3.unsqueeze(0)
),
dim=0
)
输出: tensor([[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])
torch.stack((t1,t2,t3), dim=1)
输出: tensor([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]])
print(t1.unsqueeze(1).shape)
print(t1.unsqueeze(1))
输出: torch.Size([3, 1])
tensor([[1],
[1],
[1]])
torch.cat(
(
t1.unsqueeze(1),
t2.unsqueeze(1),
t3.unsqueeze(1)
),
dim=1
)
输出: tensor([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]])
二、tensorflow
tf.concat and tf.stack
t1 = tf.constant([1, 1, 1])
t2 = tf.constant([2, 2, 2])
t3 = tf.constant([3, 3, 3])
tf.concat((t1,t2,t3), axis=0)
输出: <tf.Tensor: shape=(9,), dtype=int32, numpy=array([1, 1, 1, 2, 2, 2, 3, 3, 3])>
tf.stack((t1,t2,t3), axis=0)
输出: <tf.Tensor: shape=(3, 3), dtype=int32, numpy=
array([[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])>
print(tf.expand_dims(t1, 0).shape)
print(tf.expand_dims(t1, 0))
输出: (1, 3)
tf.Tensor([[1 1 1]], shape=(1, 3), dtype=int32)
tf.concat(
(
tf.expand_dims(t1, 0),
tf.expand_dims(t2, 0),
tf.expand_dims(t3, 0)
),
axis=0
)
输出: <tf.Tensor: shape=(3, 3), dtype=int32, numpy=
array([[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])>
tf.stack((t1,t2,t3), axis=1)
输出: <tf.Tensor: shape=(3, 3), dtype=int32, numpy=
array([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]])>
print(tf.expand_dims(t1, 1).shape)
print(tf.expand_dims(t1, 1))
输出: (3, 1)
tf.Tensor(
[[1]
[1]
[1]], shape=(3, 1), dtype=int32)
tf.concat(
(
tf.expand_dims(t1, 1),
tf.expand_dims(t2, 1),
tf.expand_dims(t3, 1)
),
axis=1
)
输出: <tf.Tensor: shape=(3, 3), dtype=int32, numpy=
array([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]])>
三、numpy
np.concatenate and np.stack
t1 = np.array([1, 1, 1])
t2 = np.array([2, 2, 2])
t3 = np.array([3, 3, 3])
np.concatenate((t1,t2,t3), axis=0)
输出: array([1, 1, 1, 2, 2, 2, 3, 3, 3])
np.stack((t1,t2,t3), axis=0)
输出: array([[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])
np.concatenate(
(
np.expand_dims(t1, 0),
np.expand_dims(t2, 0),
np.expand_dims(t3, 0)
),
axis=0
)
输出: array([[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])
np.stack((t1,t2,t3),axis=1)
输出: array([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]])
np.concatenate(
(
np.expand_dims(t1, 1),
np.expand_dims(t2, 1),
np.expand_dims(t3, 1)
),
axis=1
)
输出: array([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]])
四、结论
- torch、tensorflow、numpy不同库的语法,命名可能不同但是实现的逻辑相同
- concat方法是在现有轴上拼接
- stack方法是在新轴上堆叠,即先扩维创建新轴,再内部调用concat拼接,可以看做是concat的附加功能
- 下面是numpy的concatenate源码
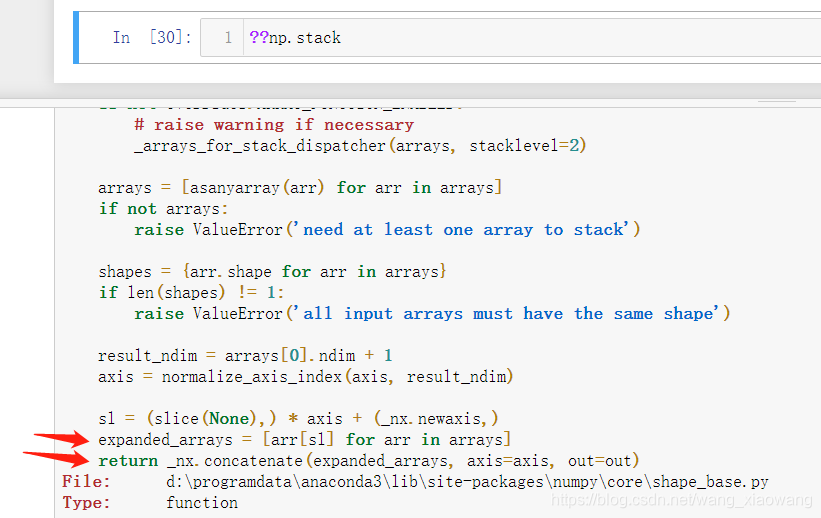







 博客对比了torch、tensorflow和numpy三个库的拼接与堆叠方法。torch有cat和stack,tensorflow有concat和stack,numpy有concatenate和stack。虽语法命名不同,但逻辑相同,concat在现有轴拼接,stack先扩维再拼接,可视为concat附加功能。
博客对比了torch、tensorflow和numpy三个库的拼接与堆叠方法。torch有cat和stack,tensorflow有concat和stack,numpy有concatenate和stack。虽语法命名不同,但逻辑相同,concat在现有轴拼接,stack先扩维再拼接,可视为concat附加功能。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









