







在java中,数组是查询性能最高的数据类型,同时也是集合类型的底层实现。
内存结构
String[] array = new String[10];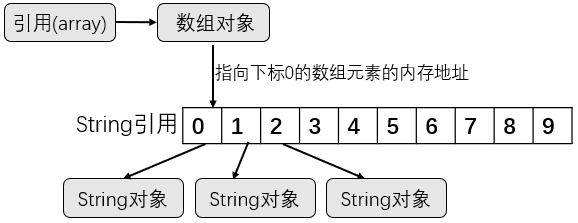
如上,这里new了一个数组对象,数组中有10个引用元素,每个引用 又可以指向一个String对象。这10个引用元素并没有存储在数组对象中,而是在另一块内存中连续存储。上一篇讲过,数组对象只有16个字节,存储不下那么多元素,只需要存储第1个元素的内存地址。那么,数组如何找到第2个和第n个元素?
数组寻址
第2篇讲过,引用的长度是相等的,即4字节,
由此可以得出一个数组的寻址公式:
- 第n个元素的内存地址 = 第1个元素的内存地址 + 数组下标 * 元素类型长度 。
因此,无论在数组中存储多大的数据量,都可以瞬间计算出任一元素的内存地址,所以数组的查询效率是最高的。
查询性能测试
以下创建一个5亿长度的数组,并添加5亿个数据元素,执行5亿次查询。 public static void main(String[] args) throws InterruptedException {
//创建一个5亿元素的数组
int size=500000000;
int[] s = new int[size];
for(int i=0;i<s.length;i++) {
s[i] = i;
}
//记录时间点1
long time1 = System.currentTimeMillis();
int temp;
//执行5亿次查询
for(int i=0;i<size;i++) {
temp = s[i];
}
//记录时间点2
long time2 = System.currentTimeMillis();
System.out.println(time2-time1);
}
耗时:1毫秒
5亿次查询仅用时1毫秒,没有比它性能更高的了。
增删改性能
无论什么结构,首先要通过查询进行定位,找到要操作的具体位置,才能执行增删改。由于数组可以直接定位,查询性能最高,直接带动增删改的性能都非常高。而有些其他结构,无法直接定位,需要逐个查找,整体性能会逊色很多,以后会具体讲。
数组特性
为了保证高效的查询,可以推导出数组的特性:
- 数组中元素类型必须一致,这样才能保证每个元素的长度一致。否则寻址公式无效。
- 数组长度是固定的,因为要计算内存地址,数组必须连续存储。而数组前后的内存有可能被其他数据占用,导致数组长度无法扩容。

应用场景
由于数组的高性能,在通用场景下第一选择就是数组。如果你看过spring源码,你会发现遍地都是数组,spring的原则是能用数组就不会去用集合,其实我们也应该这样。但是上面说了,数组的使用是有一些限制的,比如无法扩容。遇到这样的场景要如何应对?下篇再讲


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









