










Queue(队列对象)
queue是python3中的标准库,可以直接import queue引用;队列是线程间最常用的交换数据的形式。
python下多线程的思考
对于资源,加锁是个重要的环节。因为python原生的list,dict等,都是not thread safe的。而queue,是线程安全的,因此在满足使用条件下,建议使用队列
1. 初始化: class Queue.Queue(maxsize) FIFO 先进先出
2. 包中的常用方法:
- queue.qsize() 返回队列的大小
- queue.empty() 如果队列为空,返回True,反之False
- queue.full() 如果队列满了,返回True,反之False
- queue.full 与 maxsize 大小对应
- queue.get([block[, timeout]])获取队列,timeout等待时间
3. 创建一个“队列”对象
import queue
myqueue = queue.Queue(maxsize = 10)
4. 将一个值放入队列中
myqueue.put(10)
5. 将一个值从队列中取出
myqueue.get()
多线程示意图
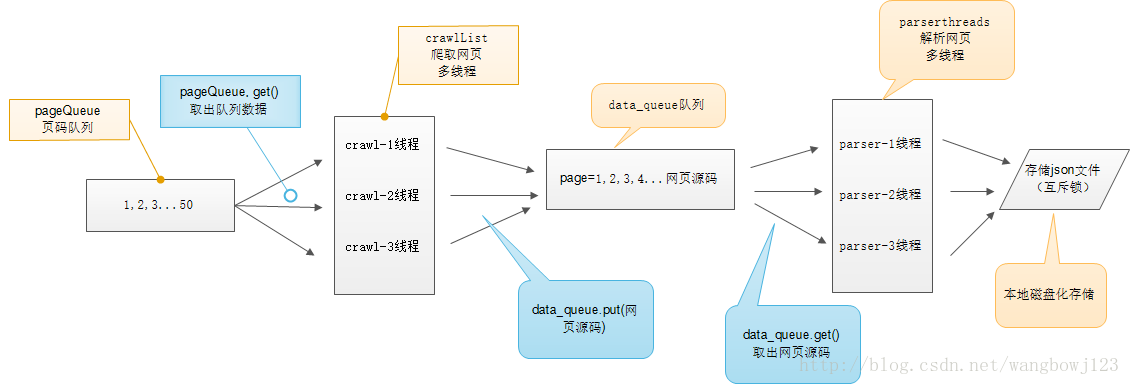
在单进程爬虫中我们发现程序运行缓慢,逐条语句的执行:构建request请求、得到response相应,分析出图片所在的页面,再构建request请求、在分析,从而得到图片地址,之后再执行文件写操作,这样的顺序执行不免过于幼稚,效率实在是低,因而我们引入多线程。
总体而言,多线程是python中相对鸡肋的功能模块,但是将其应用于爬虫中,或高I/O程序中便能得到意想不到的效果。
说干就干,我们利用python3的标准库queue(在python2中是大写Q),构建四个队列,分别保存页码、采集结果、图片页面链接、图片地址,之后构建相应操作的线程,令每一个线程各司其职,访问各自所需要的数据,各自对其进行处理或请求或相应。
从而我们发现需要构建四类线程,所以我们写四个线程类,重写run()方法,执行相应操作。
值得格外注意的便是对数据队列的判空,当某一个数据队列为空时,相应父线程要挂起等待子线程结束,并结束run()方法中的死循环。由此便实现了简单的多线程爬虫。
源代码如下:(去掉了请求的页面地址,页面解析利用了xpath)
# -*- coding:utf-8 -*-
# author = wangbowj123
# 多线程爬虫示例
from queue import Queue
from lxml import etree
from urllib import request as urllib2
import threading
import re
headers = {
'Host':'',
'User-Agent':'',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Referer':'',
'Cookie':'',
'Connection':'keep-alive',
'Upgrade-Insecure-Requests':'1',
}
n = 0
class ThreadCrawl(threading.Thread):
def __init__(self, threadName, pageQueue, dataQueue):
# threading.Thread.__init__(self)
# 调用父类初始化方法
super(ThreadCrawl, self).__init__()
self.threadName = threadName
self.pageQueue = pageQueue
self.dataQueue = dataQueue
def run(self):
print(self.threadName + ' begin--------')
while not CRAWL_EXIT:
try:
# 队列为空 产生异常
page = self.pageQueue.get(block=False)
url = ''+str(page)+'.html'
except:
break
timeOut = 4
while timeOut > 0:
timeOut -= 1
try:
request = urllib2.Request(url=url, headers=headers)
response = urllib2.urlopen(request).read().decode('gbk')
self.dataQueue.put(response)
break
except Exception as e:
print(e)
if timeOut <= 0:
print('time out!')
class ThreadParse(threading.Thread):
# 负责解析页面 提供图片页面地址
def __init__(self, threadName, dataQueue, linkQueue):
super(ThreadParse, self).__init__()
self.threadName = threadName
self.dataQueue = dataQueue
self.linkQueue = linkQueue
def run(self):
print(self.threadName + ' begin--------')
while not PARSE_EXIT:
try:
html = self.dataQueue.get(block=False)
self.parsePage(html)
except Exception as e:
pass
def parsePage(self,html):
# 解析html文档为html dom模型
dom = etree.HTML(html)
# 返回所有匹配成功后的集合
link_list = dom.xpath('//div[@class="gallery_list"]/div/dl/dd[@class="title"]/a/@href')
# 提取出页面链接
for link in link_list:
full_link = '' + link
# print(full_link)
self.linkQueue.put(full_link)
request = urllib2.Request(full_link, headers=headers)
response = urllib2.urlopen(request)
html = response.read().decode('gbk')
dom = etree.HTML(html)
nowPage = dom.xpath('//div[@class="contentbox"]/div[2]/ul/li[@class="thisclass"]/a/text()')
nextPages = dom.xpath('//div[@class="contentbox"]/div[2]//li/a/@href')
pattern = re.compile(r'.*://.*/')
now = ''.join(nowPage)
if int(now) == 1:
newUrl = pattern.findall(full_link)
for nextPage in nextPages:
if nextPage != '#':
full_url = ''.join(newUrl) + nextPage
self.linkQueue.put(full_url)
print(full_url)
class ThreadImage(threading.Thread):
# 负责提取出图片下载地址
def __init__(self, threadName, linkQueue, imageQueue):
super(ThreadImage, self).__init__()
self.threadName = threadName
self.linkQueue = linkQueue
self.imageQueue = imageQueue
def run(self):
print(self.threadName+' begin--------')
while not IMAGE_EXIT:
try:
pageLink = self.linkQueue.get(block=False)
self.loadImage(pageLink)
except Exception as e:
pass
def loadImage(self, url):
request = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(request)
html = response.read().decode('gbk')
# 解析html文档为html dom模型
dom = etree.HTML(html)
srcs = dom.xpath('//img[@id="bigimg"]/@src')
# pageStr = dom.xpath('//div[@class="contentbox"]/div[2]/ul/li[1]/a/text()')
for src in srcs:
self.imageQueue.put(src)
class ThreadWrite(threading.Thread):
def __init__(self, thraedName, imageQueue):
super(ThreadWrite, self).__init__()
self.threadName = thraedName
self.imageQueue = imageQueue
def run(self):
print(self.threadName + ' begin--------')
while not LOAD_EXIT:
try:
pageLink = self.imageQueue.get(block=False)
self.writeImage(pageLink)
except Exception as e:
pass
def writeImage(self, url):
print('-----loading image-----')
print(url)
request = urllib2.Request(url=url, headers=headers)
response = urllib2.urlopen(request)
print(response)
image = response.read()
global n
try:
file = open('image/' + str(n)+'.jpg', 'wb')
n += 1
file.write(image)
file.close()
except Exception as e:
print(e)
return
CRAWL_EXIT = False
PARSE_EXIT = False
IMAGE_EXIT = False
LOAD_EXIT = False
def main():
# 页码的队列, 表示10个页面
pageQueue = Queue(5)
# 放入1 到 10 先进先出
for i in range(1, 6):
pageQueue.put(i)
# 采集结果(每页的html源码)的数据队列
dataQueue = Queue()
# 采集到的图片地址
linkQueue = Queue()
imageQueue = Queue()
# 记录线程的列表
threadCrawl = []
crawList = ['采集线程1号','采集线程2号','采集线程3号','采集线程4号',]
for threadName in crawList:
Cthread = ThreadCrawl(threadName, pageQueue, dataQueue)
Cthread.start()
threadCrawl.append(Cthread)
threadParse = []
parseList = ['解析线程1号', '解析线程2号', '解析线程3号', '解析线程4号', ]
for threadName in parseList:
Pthread = ThreadParse(threadName, dataQueue, linkQueue)
Pthread.start()
threadParse.append(Pthread)
threadImage = []
imageList = ['下载线程1号', '下载线程2号', '下载线程3号', '下载线程4号', ]
for threadName in imageList:
Ithraad = ThreadImage(threadName, linkQueue, imageQueue)
Ithraad.start()
threadImage.append(Ithraad)
threadLoad = []
loadList = ['存储线程1号', '存储线程2号', '存储线程3号', '存储线程4号', ]
for threadName in loadList:
Ithraad = ThreadWrite(threadName, imageQueue)
Ithraad.start()
threadLoad.append(Ithraad)
# 等待pageQueue队列为空,也就是等待之前的操作执行完毕
while not pageQueue.empty():
pass
# 如果pageQueue为空,采集线程退出循环
global CRAWL_EXIT
CRAWL_EXIT = True
print ("pageQueue为空")
for thread in threadCrawl:
thread.join()
print("1")
while not dataQueue.empty():
pass
global PARSE_EXIT
PARSE_EXIT = True
for thread in threadParse:
thread.join()
print ("2")
while not linkQueue.empty():
pass
global IMAGE_EXIT
CRAWL_EXIT = True
for thread in threadImage:
thread.join()
print("3")
while not imageQueue.empty():
pass
global LOAD_EXIT
LOAD_EXIT = True
for thread in threadLoad:
thread.join()
print("4")
if __name__ == '__main__':
main()
因为爬取的是某一个不可言述网站,所以就隐去了,哈哈哈哈。
爬取了大概一千多张图片,之后IP就被封了,也懒得换代理。
















 5853
5853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











