







1. 什么是 Selective Search ?
简单说,就是从图片中找出物体可能存在的区域,下面宇航员图片中红色框就是 selective search 找出来的可能存在物体的区域,

2. 与传统的目标检测算法相比
- 传统的目标检测算法一般是图片上使用穷举法或者滑动窗口选出所有物体可能出现的区域框,对这些区域框提取特征并进行使用图像识别分类方法,得到所有分类成功的区域后,通过非极大值抑制输出结果。
- 这样做的缺点是,复杂度太高,产生了很多的冗余候选区域,而且由于不可能每个尺度都兼顾到,因此得到的目标位置也不可能那么准,在现实当中不可行。
- 选择性搜索有效地去除冗余候选区域,使得计算量大大的减小。
在讨论原理之前,首先分析一下,如何判别哪些区域属于一个物体 ?

上图来自原论文,分别描述了四种可能的情况:
- 图 a,物体之间存在层级关系,如:碗里有个勺子;
- 图 b,我们可以用颜色来分开两只猫,却没法用纹理来区分;
- 图 c,我们可以用纹理来区分变色龙,却没法用颜色来区分;
- 图 d,轮胎是车的一部分,不是因为它们颜色相近、纹理相近,而是因为轮胎包含在车上。
因此,我们无法从单一特征来定位物体,需要综合考虑多种策略,这一点是 Selective Search的要点。
Selective Search 的策略是,在不知道物体的尺度是怎样的情况下,尽可能遍历所有的尺度,但又不同于暴力穷举,我们可以先基于图的图像分割的方法得到小尺度的区域,然后一次次合并得到大的尺度(即包含物体的区域)。最后对每个区域进行排序,想要得到几个候选区域就产生多少个。
3. 说一下 Selective Search 的几个特点
- 能够适应不同的尺度:传统的穷举搜索通过改变窗口大小来适应物体的不同尺度,Selective Search 则采用了图像分割以及一种层次算法有效地解决了这个问题。
- 多样化:上面提到,无法从单一特征来定位物体,因此使用颜色、纹理、大小等多种策略对分割好的区域进行合并
- 速度快
4. Selective Search 的具体算法

算法描述如下
* 输入:彩色图片
* 输出:物体可能的位置,实际上是很多的矩形坐标
1. 首先,使用论文中的方法将图片初始化为很多小区域 R = {r1, r2, ..., rn}。
2. 初始化一个相似集合为空集:S = {}
3. 计算所有相邻区域之间的相似度,放入集合 S 中,集合 S 保存的其实是一个区域对以及它们之间的相似度
for each 邻居区域对(ri, rj) do
计算相似度 s(ri, rj)
放入集合 S:S = S ∪ s(ri, rj)
4. 找出 S 中相似度最高的区域对,将它们合并,并从 S 中删除与它们相关的所有相似度和区域对。
重新计算这个新区域与周围区域的相似度,放入集合 S 中,并将这个新合并的区域放入集合 R 中,重复这个步骤直到 **S** 为空。
while S 不为空 do
从 S 中取得最大相似度区域对 s(ri, rj) = max(S)
将取得的区域对合并,产生新的区域:rt = ri ∪ rj
移除 ri 对应的所有相似度:S = S\s(ri, r*)
移除 rj 对应的所有相似度:S = S\s(r*, rj)
计算新的区域 rt 与周围区域的相似度集合 St
将 St 放入相似度集合 S:S = S ∪ St
将 新的区域 rt 放入集合 R:R = R ∪ rt
5. 从 R 中找出所有区域的 bounding box (即包围该区域的最小矩形框),
这些 box 就是物体可能的区域。
为了提高速度,新合并区域的 feature 可以通过之前的两个区域获得,而不必重新遍历新区域的像素点进行计算。这个 feature 会被用于计算相似度。

5. 区域相似度计算
考虑该算法的多样性的特点,需要计算多种相似度。
颜色相似度
使用 L1-norm 归一化获取图像每个颜色通道的 25bin(表示将0-255的颜色空间平均划分为25个小的颜色空间) 直方图,这样每个区域都可以得到一个 75(25x3) 维的向量
{
c
i
1
,
.
.
.
,
c
i
n
}
\{c^1_i, ... ,c^n_i\}
{ci1,...,cin},区域之间颜色相似度通过以下公式计算:
s
c
o
l
o
r
(
r
i
,
r
j
)
=
∑
k
=
1
n
m
i
n
(
c
i
k
,
c
j
k
)
.
s_{color}(r_i, r_j)=\sum^n_{k=1}min(c^k_i, c^k_j).
scolor(ri,rj)=k=1∑nmin(cik,cjk).
解释:由于
{
c
i
1
,
.
.
.
,
c
i
n
}
\{c^1_i, ... ,c^n_i\}
{ci1,...,cin} 是归一化后的值,每个颜色通道的直方图累加和为 1.0,三个通道的累加和就为 3.0,假设区域
c
i
c_i
ci 和区域
c
j
c_j
cj 直方图完全一样,则此时颜色相似度最大为 3.0,如果不一样,由于累加取两个区域 bin 的最小值进行累加,当直方图差距越大,累加的和解越小,即颜色相似度越小。
在区域合并过程中需要对新的区域计算其直方图,计算方法为:
C
t
=
s
i
z
e
(
r
i
)
×
C
i
+
s
i
z
e
(
r
j
)
×
C
j
s
i
z
e
(
r
i
)
+
s
i
z
e
(
r
j
)
C_t = \frac{size(r_i)\times C_i+size(r_j)\times C_j}{size(ri)+size(r_j)}
Ct=size(ri)+size(rj)size(ri)×Ci+size(rj)×Cj
纹理相似度
这里的纹理采样 SIFT-Like 特征,具体做法是对每个颜色通道的 8 个不同方向计算方差
σ
=
1
\sigma=1
σ=1 的高斯微分,使用 L1-norm 归一化获取图像每个颜色通道的每个方向的 10 bins 的直方图,这样就可以获取到一个 240(10x8x3)维的向量
T
i
=
{
t
i
1
,
.
.
.
,
t
i
n
}
T_i=\{t^1_i, ..., t^n_i\}
Ti={ti1,...,tin} 区域之间纹理相似度计算方式和颜色相似度计算方式相似,合并之后新区域的纹理特征计算方式和颜色特征计算相同
s
t
e
x
t
u
r
e
(
r
i
,
r
j
)
=
∑
k
=
1
n
m
i
n
(
t
i
k
,
t
j
k
)
.
s_{texture}(r_i, r_j)=\sum^n_{k=1}min(t^k_i, t^k_j).
stexture(ri,rj)=k=1∑nmin(tik,tjk).
优先合并小的区域
如果仅仅是通过颜色和纹理特征合并的话,很容易使得合并后的区域不断吞并周围的区域,后果就是多尺度只应用在了那个局部,而不是全局的多尺度。因此我们给小的区域更多的权重,这样保证在图像每个位置都是多尺度的在合并。
s
s
i
z
e
(
r
i
,
r
j
)
=
1
−
s
i
z
e
(
r
i
)
+
s
i
z
e
(
r
j
)
s
i
z
e
(
i
m
)
s_{size}(r_i, r_j)=1-\frac{size(r_i)+size(r_j)}{size(im)}
ssize(ri,rj)=1−size(im)size(ri)+size(rj)
上式表示,两个区域越小,其相似度越大,越接近 1。
区域的合适度距离
如果区域
r
i
r_i
ri 包含在
r
j
r_j
rj 内,我们首先应该合并,另一方面,如果
r
i
r_i
ri 很难与
r
j
r_j
rj 相接,他们之间会形成断崖,不应该合并在一块。这里定义区域的合适度距离主要是为了衡量两个区域是否更加“吻合”,其指标是合并后的区域的 Bounding Box(能够框住区域的最小矩形BBij)越小,其吻合度越高,即相似度越接近 1。其计算方式:
f
i
l
l
(
r
i
,
r
j
)
=
1
−
s
i
z
e
(
B
B
i
j
)
−
s
i
z
e
(
r
i
)
−
s
i
z
e
(
r
j
)
s
i
z
e
(
i
m
)
fill(r_i, r_j)=1-\frac{size(BB_{ij})-size(r_i)-size(r_j)}{size(im)}
fill(ri,rj)=1−size(im)size(BBij)−size(ri)−size(rj)
合并上面四种相似度
s ( r i , r j ) = a 1 s c o l o r ( r i , r j ) + a 2 s t e x t u r e ( r i , r j ) + a 3 s s i z e ( r i , r j ) + a 4 s f i l l ( r i , r j ) s(r_i, r_j)=a_1s_{color}(r_i, r_j)+a_2s_{texture}(r_i, r_j)+a_3s_{size}(r_i, r_j)+a_4s_{fill}(r_i, r_j) s(ri,rj)=a1scolor(ri,rj)+a2stexture(ri,rj)+a3ssize(ri,rj)+a4sfill(ri,rj),其中 a i ∈ { 0 , 1 } a_i \in \{0, 1\} ai∈{0,1}
6. 给区域打分
通过上述的步骤我们能够得到很多很多的区域,但是显然不是每个区域作为目标的可能性都是相同的,因此我们需要衡量这个可能性,这样就可以根据我们的需要筛选区域建议个数啦。
这篇文章做法是,给予最先合并的图片块较大的权重,比如最后一块完整图像权重为1,倒数第二次合并的区域权重为2以此类推。但是当我们策略很多,多样性很多的时候呢,这个权重就会有太多的重合了,排序不好搞啊。文章做法是给他们乘以一个随机数,毕竟3分看运气嘛,然后对于相同的区域多次出现的也叠加下权重,毕竟多个方法都说你是目标,也是有理由的嘛。这样我就得到了所有区域的目标分数,也就可以根据自己的需要选择需要多少个区域了。
7. 选择性搜索性能评估
通过算法计算得到的包含物体的 Bounding Boxes 与真实情况(ground truth)的窗口重叠越多,那么算法性能就越好。这是使用的指标是平均最高重叠率 ABO(Average Best Overlap)。对于每个固定的类别 c,每个真实情况(ground truth)表示为
g
i
c
∈
G
c
g^c_i \in G^c
gic∈Gc,令计算得到的位置假设 L 中的每个值
l
j
l_j
lj,那么 ABO 的公式表达为:
A
B
O
=
1
∣
G
c
∣
∑
g
i
c
∈
G
c
max
l
j
∈
L
Overlap
(
g
i
c
,
l
j
)
\mathrm{ABO}=\frac{1}{\left|G^{c}\right|} \sum_{g_{i}^{c} \in G^{c}} \max _{l_{j} \in L} \text { Overlap }\left(g_{i}^{c}, l_{j}\right)
ABO=∣Gc∣1gic∈Gc∑lj∈Lmax Overlap (gic,lj)
重叠率计算方式为:
Overlap
(
g
i
c
,
l
j
)
=
area
(
g
i
c
)
∩
area
(
l
j
)
area
(
g
i
c
)
∪
area
(
l
j
)
\text { Overlap }\left(g_{i}^{c}, l_{j}\right)=\frac{\operatorname{area}\left(g_{i}^{c}\right) \cap \operatorname{area}\left(\mathrm{l}_{\mathrm{j}}\right)}{\operatorname{area}\left(g_{i}^{c}\right) \cup \operatorname{area}\left(\mathrm{l}_{\mathrm{j}}\right)}
Overlap (gic,lj)=area(gic)∪area(lj)area(gic)∩area(lj)
上面结果给出的是一个类别的 ABO,对于所有类别下的性能评价,很自然就是使用所有类别的 ABO 的平均值 MABO(Mean Average Best Overlap)来评价
1、单一策略评估
通过改变多样性策略中的任何一种,评估选择性搜索的 MABO 性能指标。论文中采取的策略如下:
- 使用RGB色彩空间(基于图的图像分割会利用不同的色彩进行图像区域分割)
- 采用四种相似度计算的组合方式
- 设置图像分割的阈值k=50
然后通过改变其中一个策略参数,获取MABO性能指标如下表(第一列为改变的参数,第二列为MABO值,第三列为获取的候选区的个数):

表中左侧为不同的相似度组合,单独的,我们可以看到纹理相似度表现最差,MABO 为0.581,其他的 MABO 值介于0.63和0.64之间。当使用多种相似度组合时 MABO 性能优于单种相似度。表的右上角表名使用 HSV 颜色空间,有463个候选区域,而且 MABO 值最大为0.693。表的右下角表名使用较小的阈值,会得到更多的候选区和较高的 MABO 值。
2、多样性策略组合
使用贪婪的搜索算法,把单一策略进行组合,会得到较高的 MABO,但是也会造成计算成本的增加。下表给出了三种组合的MABO性能指标:
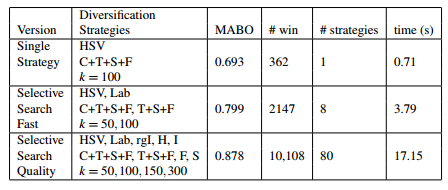

上图中的绿色边框为对象的标记边框,红色边框为我们使用 ‘Quality’ Selective Search算法获得的Overlap最高的候选框。可以看到我们这个候选框和真实标记非常接近。
下图为各个算法在选取不同候选区数量,Recall和MABO性能的曲线图,从计算成本、以及性能考虑,Selective Search Fast算法在2000个候选区时,效果较好。

8. python 代码实现 Selective Search
pip install selectivesearch
然后从https://github.com/AlpacaDB/selectivesearch下载源码,运行example\example.py文件。效果如下:
# -*- coding: utf-8 -*-
from __future__ import (
division,
print_function,
)
import skimage.data
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import selectivesearch
def main():
# loading astronaut image
img = skimage.data.astronaut()
# perform selective search
img_lbl, regions = selectivesearch.selective_search(
img, scale=500, sigma=0.9, min_size=10)
candidates = set()
for r in regions:
# excluding same rectangle (with different segments)
if r['rect'] in candidates:
continue
# excluding regions smaller than 2000 pixels
if r['size'] < 2000:
continue
# distorted rects
x, y, w, h = r['rect']
if w / h > 1.2 or h / w > 1.2:
continue
candidates.add(r['rect'])
# draw rectangles on the original image
fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(6, 6))
ax.imshow(img)
for x, y, w, h in candidates:
print(x, y, w, h)
rect = mpatches.Rectangle(
(x, y), w, h, fill=False, edgecolor='red', linewidth=1)
ax.add_patch(rect)
plt.show()
if __name__ == "__main__":
main()
















 797
797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









