







KMP匹配算法实现详解
什么是字符串匹配:
字符串匹配就是查找子串(sub)在主串(str)中的位置,并返回位置信息。这里将子串称之为模式串。
一、常用的的匹配算法思想:
从主串的i(i初始值0)位置字符起一次与模式串的j(j初始值0)位置字符比较;
若相等,i++,j++;
否则,i=i-j+1,即i指向上次比较的下一个位置,j=0;
直到j=sub.length,表示匹配成功,返回模式串在主串的位置i-sub.length;
否则,匹配不成功 。
实现代码:
public static void main(String[] args) {
Scanner sc=new Scanner(System.in);
String S;
String T;
while(sc.hasNext()){
//字符串输入
S=sc.nextLine();
T=sc.nextLine();
int i=0;
int j=0;
char cs[]=S.toCharArray();
char ct[]=T.toCharArray();
//一一匹配比较 每次不成功 j 将回到匹配串的原点,i+1
while(j<ct.length&&i<cs.length){
if (cs[i]==ct[j]) {
i++;
j++;
}else {
i=i-j+1;
j=0;
}
}
if (j>=ct.length) {
//位置是下标加一
System.out.println(i-ct.length+1);
}else {
System.out.println(0);
}
}
}分析:该算法最坏的情况下时间复杂度为O(n*m)。其中n m为主串和模式串的长度。
KMP算法思想:
在简单匹配算法中,一趟的匹配中当i>1时,有cs[i]!=ct[j]时,i需要回到这趟匹配的初始位置的下一个位置,而j也要回到初始位置。即i=i-j+1,即i指向上次比较的下一个位置,j=0;此时该算法忽略了一部分一致的信息,即已经有一部分匹配通过。
因此简单匹配算法有两处改进之处:1、i没必要回溯(即指向回退);2、“部分已匹配”信息没有充分利用,该信息可能使得j无需回到初始位置。这样的就可以是匹配的速度加速前进,无需回滚进行。
二、KMP算法需要解决的问题:
1、i无需回溯
2、在下一趟匹配中,j将指向到模式串中的什么位置(定义为next[j])?即模式串的从哪个字符开始与i(主串上次比较不等的位置)位置之后字符比较?
实例:(《数据结构》严蔚敏 版中示例)
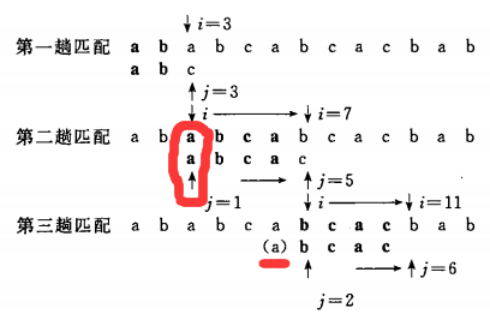
从上面的图很容易发现,在i=3时,模式串中第一个a已经比较并被确定,因此在后续的比较中,就可以利用已知信息使得j的值后移,用来减少比较次数。因此在i为7时,j=2。现在关键的问题是如何确定j=2,而不是其他的数值,在程序实现中。
1、Next[j]推导与实现
定义:当模式串中第j个字符与主串中i位置字符不等时,定义Next[j]为在下趟匹配时,模式串比较的起始位置。
设Next[j]=k,主串为S,模式串T,串的位置下标从1开始,程序中字符数组下标从0开始。
很容易推导出:
T(1),T(2)…..T(K-1)=S(i-k+1)……..S(i-1)
在一趟匹配中,
T(j-k+1)……T(j-1)=S(i-k+1)……..S(i-1)
因此:T(1),T(2)…..T(K-1)=T(j-k+1)……T(j-1)
这也表明:next[j]的值只与其模式串自身有关。
其中K必定满足:1 < k < j
由上面递推可得:
Next[j+1]:
设next[1]=0;
Next[j+1]=next[j]+1 T(next[j])=T(j)
Next[j+1]=next[next[j]]+1 T(next[j])!=T(j) T(next[next[j]])=T(j)
………………………………………
以此类推直到next[M]且M=1,即遇到next[1]=0时,next[j+1]=1;
Next[j+1]求解过程示例:
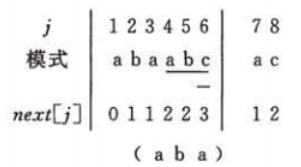
初始状态:Next[1]=0 ;
Next[2]=next[1+1] 因为T(next[1])=T(0)
因此next[2]=1 ,
Next[3]=next[2+1] 因为T(next[2]=1)=a != T(2)
T(next[next[2]])=T(next[1])=T(0)
因此next[3]=1,
Next[4]=next[3+1] 因为T(next[3])=T(1)=a = T(j=3)=a
因此next[4]=next[3]+1=2
Next[5]=next[4+1] 因为T(next[4])=T(2)=b != T(j=4)=a
T(next[next[4]])=T(next[2])=T(1)=a = T(j=4)=a
因此next[5]=next[next[4]]+1=2
Next[6]=next[5+1] 因为T(next[5])=T(2)=b = T(j=5)=b
因此next[6]=next[5]+1=3
Next[7]=next[6+1] 因为T(next[6])=T(3)=a != T(j=6)=c
T(next[next[6]])=T(1)=a != T(j=6)=c
T(next[next[next[6]]])=T(0)
因此next[7]=1
Next[8]=next[7+1] 因为 T(next[7])=T(1)=a = T(j=7)=a 因此 next[8]=next[7]+1=2
这部分的推导比较麻烦,详细推导可参考,《数据结构》严蔚敏 版 P83
KMP完整实现程序:
import java.util.Scanner;
public class KMPIndex {
/**
* next[j]求解过程
*
*/
public static int[] nextJ(char ct[]) {
int[] next = new int[ct.length];
next[0]=-1;
int j = -1;
int i = 0;
while (i < ct.length - 1) {
if ((j == -1) || (ct[i] == ct[j])) {
j++;
i++;
if (ct[i] != ct[j]) {
next[i] = j;
} else {
next[i] = next[j];
}
} else {
j = next[j];
}
}
return next;
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
//输入主串和模式串
String S = sc.nextLine();
String T = sc.nextLine();
char cs[] = S.toCharArray();
char ct[] = T.toCharArray();
//获得next数组
int next[] = nextJ(ct);
int i = 0;
int j = 0;
while (i <= cs.length-1 && j <= ct.length-1) {
if (j == -1 || cs[i] == ct[j]) {
i++;
j++;
} else {
j = next[j];
}
}
if (j < ct.length) {
System.out.println("匹配失败");
} else {
System.out.println(i-ct.length);
}
}
}
}分析该算法的时间复杂度为O(n+m) 其中n为主串长度 ,m为模式串长度
备注:参考文献 《数据结构》(C语言版)严蔚敏 版















 1061
1061











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









