






微信公众号:运维开发故事
作者:冬子先生
环境:centos7
kubernetes版本:1.24
前言:这两天在搞大模型服务,之前也没了解过GPU相关的服务,因此整理了一个关于如何能够使用gpu节点文档。
1、现象
本来服务已经部署上去,但是一直处理pending状态,不能正常调度,describe查看返回这么一个错误:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 45m (x23 over 151m) default-scheduler 0/3 nodes are available: 3 Insufficient nvidia.com/gpu. preemption: 0/3 nodes are available: 3 No preemption victims found for incoming pod.
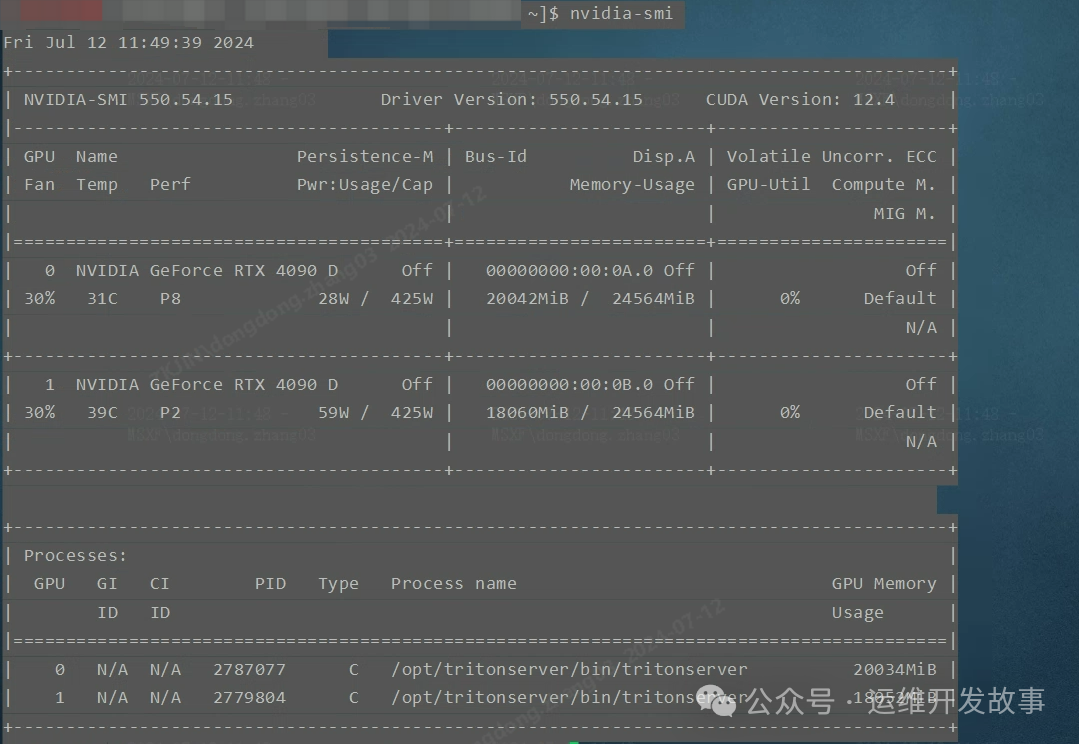
重点是这个 Insufficient nvidia.com/gpu.,提示我没有可用的gpu,第一次遇到是也是感觉有点蒙圈,因为再机器上已经成功安装好驱动,可以正常查看GPU状态。
img
经过查询,kubernetes要调度GPU,也需要安装对应厂商的设备插件
- GPU容器创建流程
containerd --> containerd-shim--> nvidia-container-runtime --> nvidia-container-runtime-hook --> libnvidia-container --> runc -- > container-process
2.安装GPU插件
gpu节点加入k8s集群,做AI分析是一种比较常见的情景,当pod使用GPU卡时,通常有以下两种方案:
2.1 方案一:使用nvidia官方插件
此时资源分配时,是按照卡的数量进行资源分配,k8s的yml文件类似于如下:
resources:
limits:
nvidia.com/gpu: '1'
requests:
nvidia.com/gpu: '1'
其中1表示使用1张GPU卡。
步骤一: 安装nvidia Linux驱动
- 下载并安装nvidia Linux 驱动:
apt-get update
apt-get install gcc make
## cuda10.1
wget -c https://ops-software-binary-1255440668.cos.ap-chengdu.myqcloud.com/nvidia/NVIDIA-Linux-x86_64-430.50.run
bash NVIDIA-Linux-x86_64-430.50.run
## cuda10.2
wget -c https://ops-software-binary-1255440668.cos.ap-chengdu.myqcloud.com/nvidia/NVIDIA-Linux-x86_64-440.100.run
bash NVIDIA-Linux-x86_64-440.100.run
## cuda11
wget -c https://ops-software-binary-1255440668.cos.ap-chengdu.myqcloud.com/nvidia/NVIDIA-Linux-x86_64-450.66.run
bash NVIDIA-Linux-x86_64-450.66.run
## cuda11.4
wget -c https://ops-software-binary-1255440668.cos.ap-chengdu.myqcloud.com/nvidia/NVIDIA-Linux-x86_64-470.57.02.run
bash NVIDIA-Linux-x86_64-470.57.02.run
步骤二: 安装 nvidia runtime
https://nvidia.github.io/nvidia-container-runtime/
- ubuntu 安装 nvidia runtime
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
cat > /etc/apt/sources.list.d/nvidia-docker.list <<'EOF'
deb https://nvidia.github.io/libnvidia-container/ubuntu16.04/$(ARCH) /
deb https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/$(ARCH) /
deb https://nvidia.github.io/nvidia-docker/ubuntu16.04/$(ARCH) /
EOF
apt-get update
apt-get install nvidia-container-runtime
- centos 安装 nvidia runtime
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
DIST=$(sed -n 's/releasever=//p' /etc/yum.conf)
DIST=${DIST:-$(. /etc/os-release; echo $VERSION_ID)}
sudo rpm -e gpg-pubkey-f796ecb0
sudo gpg --homedir /var/lib/yum/repos/$(uname -m)/$DIST/nvidia-docker/gpgdir --delete-key f796ecb0
sudo yum makecache
yum -y install nvidia-container-runtime
步骤三:配置containerd/docker
containerd
若K8s使用containerd,按照如下方式进行配置:
修改/etc/containerd/config.toml文件
cat /etc/containerd/config.toml
#其他的根据自己的需求修改,我这里只说明适配gpu的配置
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
[plugins."io.containerd.grpc.v1.cri".containerd]
#-------------------修改开始-------------------------------------------
default_runtime_name = "nvidia"
#-------------------修改结束-------------------------------------------
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
#-------------------新增开始-------------------------------------------
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/bin/nvidia-container-runtime"
#-------------------新增结束-------------------------------------------
重启containerd
systemctl restart containerd.service
docker
- 若K8s使用docker,按照如下方式进行配置:
配置daemon.json
cat /etc/docker/daemon.json
{
"registry-mirrors": [
"https://wlzfs4t4.mirror.aliyuncs.com"
],
"max-concurrent-downloads": 10,
"log-driver": "json-file",
"log-level": "warn",
"log-opts": {
"max-size": "10m",
"max-file": "3"
},
"data-root": "/data/var/lib/docker",
"bip": "169.254.31.1/24",
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
重启docker
systemctl restart docker
步骤四:在 Kubernetes 中启用 GPU 支持
在集群中的所有 GPU 节点上配置上述选项后,您可以通过部署以下 Daemonset 来启用 GPU 支持:
cat nvidia-device-plugin.yml
[root@ycloud ~]# cat nvidia-device-plugin.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nvidia-device-plugin-daemonset
namespace: kube-system
spec:
selector:
matchLabels:
name: nvidia-device-plugin-ds
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
name: nvidia-device-plugin-ds
spec:
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
# Mark this pod as a critical add-on; when enabled, the critical add-on
# scheduler reserves resources for critical add-on pods so that they can
# be rescheduled after a failure.
# See https://kubernetes.io/docs/tasks/administer-cluster/guaranteed-scheduling-critical-addon-pods/
priorityClassName: "system-node-critical"
containers:
- image: ycloudhub.com/middleware/nvidia-gpu-device-plugin:v0.12.3
name: nvidia-device-plugin-ctr
env:
- name: FAIL_ON_INIT_ERROR
value: "false"
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
volumeMounts:
- name: device-plugin
mountPath: /var/lib/kubelet/device-plugins
volumes:
- name: device-plugin
hostPath:
path: /var/lib/kubelet/device-plugins
通过apply进行部署,并查看
kubectl apply -f nvidia-device-plugin.yml
kubectl get po -n kube-system | grep nvidia
验证
[root@ycloud ~]# kubectl describe nodes ycloud
......
Capacity:
cpu: 32
ephemeral-storage: 458291312Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 131661096Ki
nvidia.com/gpu: 2
pods: 110
Allocatable:
cpu: 32
ephemeral-storage: 422361272440
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 131558696Ki
nvidia.com/gpu: 2
pods: 110
......
2.2 方案二:使用第三方插件
这里使用阿里云gpushare插件,git地址:https://github.com/AliyunContainerService/gpushare-device-plugin/
此时资源分配时,是可以按照卡的显存大小进行资源分配,k8s的yml文件类似于如下:
resources:
limits:
aliyun.com/gpu-mem: '3'
requests:
aliyun.com/gpu-mem: '3'
其中3表示使用的显存大小,单位G
步骤一: 安装nvidia Linux驱动
- 下载并安装nvidia Linux 驱动:
apt-get update
apt-get install gcc make
## cuda10.1
wget -c https://ops-software-binary-1255440668.cos.ap-chengdu.myqcloud.com/nvidia/NVIDIA-Linux-x86_64-430.50.run
bash NVIDIA-Linux-x86_64-430.50.run
## cuda10.2
wget -c https://ops-software-binary-1255440668.cos.ap-chengdu.myqcloud.com/nvidia/NVIDIA-Linux-x86_64-440.100.run
bash NVIDIA-Linux-x86_64-440.100.run
## cuda11
wget -c https://ops-software-binary-1255440668.cos.ap-chengdu.myqcloud.com/nvidia/NVIDIA-Linux-x86_64-450.66.run
bash NVIDIA-Linux-x86_64-450.66.run
步骤二: 安装 nvidia runtime
https://nvidia.github.io/nvidia-container-runtime/
- ubuntu 安装 nvidia runtime
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
cat > /etc/apt/sources.list.d/nvidia-docker.list <<'EOF'
deb https://nvidia.github.io/libnvidia-container/ubuntu16.04/$(ARCH) /
deb https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/$(ARCH) /
deb https://nvidia.github.io/nvidia-docker/ubuntu16.04/$(ARCH) /
EOF
apt-get update
apt-get install nvidia-container-runtime
- centos 安装 nvidia runtime
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
DIST=$(sed -n 's/releasever=//p' /etc/yum.conf)
DIST=${DIST:-$(. /etc/os-release; echo $VERSION_ID)}
sudo rpm -e gpg-pubkey-f796ecb0
sudo gpg --homedir /var/lib/yum/repos/$(uname -m)/$DIST/nvidia-docker/gpgdir --delete-key f796ecb0
sudo yum makecache
yum -y install nvidia-container-runtime
步骤三:配置containerd/docker
containerd
若K8s使用containerd,按照如下方式进行配置:
修改/etc/containerd/config.toml文件
#其他的根据自己的需求修改,我这里只说明适配gpu的配置
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
[plugins."io.containerd.grpc.v1.cri".containerd]
#-------------------修改开始-------------------------------------------
default_runtime_name = "nvidia"
#-------------------修改结束-------------------------------------------
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
#-------------------新增开始-------------------------------------------
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/bin/nvidia-container-runtime"
#-------------------新增结束-------------------------------------------
重启containerd
systemctl restart containerd.service
docker
- 若K8s使用docker,按照如下方式进行配置:
配置daemon.json
cat /etc/docker/daemon.json
{
"registry-mirrors": [
"https://wlzfs4t4.mirror.aliyuncs.com"
],
"max-concurrent-downloads": 10,
"log-driver": "json-file",
"log-level": "warn",
"log-opts": {
"max-size": "10m",
"max-file": "3"
},
"data-root": "/data/var/lib/docker",
"bip": "169.254.31.1/24",
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
重启docker
systemctl restart docker
步骤四:安装gpushare-scheduler-extender插件
参考文档:https://github.com/AliyunContainerService/gpushare-scheduler-extender/blob/master/docs/install.md
1.修改kube-scheduler配置:
因为我们k8s使用二进制方式安装,所以直接修改kube-scheduler启动文件,步骤如下:
- 先创建/etc/kubernetes/scheduler-policy-config.json,内容如下:
{
"kind": "Policy",
"apiVersion": "v1",
"extenders": [
{
"urlPrefix": "http://127.0.0.1:32766/gpushare-scheduler",
"filterVerb": "filter",
"bindVerb": "bind",
"enableHttps": false,
"nodeCacheCapable": true,
"managedResources": [
{
"name": "aliyun.com/gpu-mem",
"ignoredByScheduler": false
}
],
"ignorable": false
}
]
}
- 然后修改cat /etc/systemd/system/kube-scheduler.service文件,添加–policy-config-file相关内容
cat /etc/systemd/system/kube-scheduler.service
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
ExecStart=/usr/local/bin/kube-scheduler \
--address=127.0.0.1 \
--master=http://127.0.0.1:8080 \
--leader-elect=true \
--v=2 \
--policy-config-file=/etc/kubernetes/scheduler-policy-config.json
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
重启kube-scheduler
systemctl daemon-reload
systemctl restart kube-scheduler.service
2.部署gpushare-schd-extender
curl -O https://raw.githubusercontent.com/AliyunContainerService/gpushare-scheduler-extender/master/config/gpushare-schd-extender.yaml
kubectl apply -f gpushare-schd-extender.yaml
3.部署device-plugin
首先需要给节点添加label “gpushare=true”
kubectl label node <target_node> gpushare=true
For example:
kubectl label node mynode gpushare=true
然后部署device-plugin插件
wget https://raw.githubusercontent.com/AliyunContainerService/gpushare-device-plugin/master/device-plugin-rbac.yaml
kubectl apply -f device-plugin-rbac.yaml
wget https://raw.githubusercontent.com/AliyunContainerService/gpushare-device-plugin/master/device-plugin-ds.yaml
kubectl apply -f device-plugin-ds.yaml
4.安装kubectl-inspect-gpushare插件,用来查看GPU使用情况
cd /usr/bin/
wget https://github.com/AliyunContainerService/gpushare-device-plugin/releases/download/v0.3.0/kubectl-inspect-gpushare
chmod u+x /usr/bin/kubectl-inspect-gpushare
公众号:运维开发故事
github:https://github.com/orgs/sunsharing-note/dashboard
博客**:https://www.devopstory.cn**
爱生活,爱运维
我是冬子先生,《运维开发故事》公众号团队中的一员,一线运维农民工,云原生实践者,这里不仅有硬核的技术干货,还有我们对技术的思考和感悟,欢迎关注我们的公众号,期待和你一起成长!















 2571
2571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









