







一、Kafka副本基本概念
Kafka通过多副本机制实现故障自动转移,Kafka副本一些基本概念:
- 副本是针对分区而言的,即副本是分区的副本
- 一个分区有一个 leader 副本,多个 follower 副本,只有 leader副本对外提供服务,follower 副本只负责数据同步
- 分区所有副本统称 AR,ISR 指与 leader副本保持同步状态的副本集合
- LEO标识每个分区最后一条消息的下一个位置,ISR中最小的LEO为 HW,俗称高水位,消费者只能拉取到 HW 之前的消息
生产者发出的一条消息首先会被写入分区的 leader 副本,等到所有的 follower 副本都同步完之后才会被认为已提交,并更新 HW, 进而才会被消费者消费到
二、副本数据一致性问题
数据在主从复制的过程中难免会遇到某一节点宕机的情况,如何确保在类似特殊情况下依旧保持各副本数据的一致性,是分布式系统必须要解决的问题。为了解决这一问题,Kafka引入了 Leader Epoch 的概念
leader epoch 代表 leader 的纪元信息,初始值为0,每当 leader 变更一次, leader epoch 的值就会加1,相当于为 leader 增设了一个版本号。 当某一节点从宕机状态恢复时,会去查找该节点当前 leader epoch 的 LEO 作为截断依据。
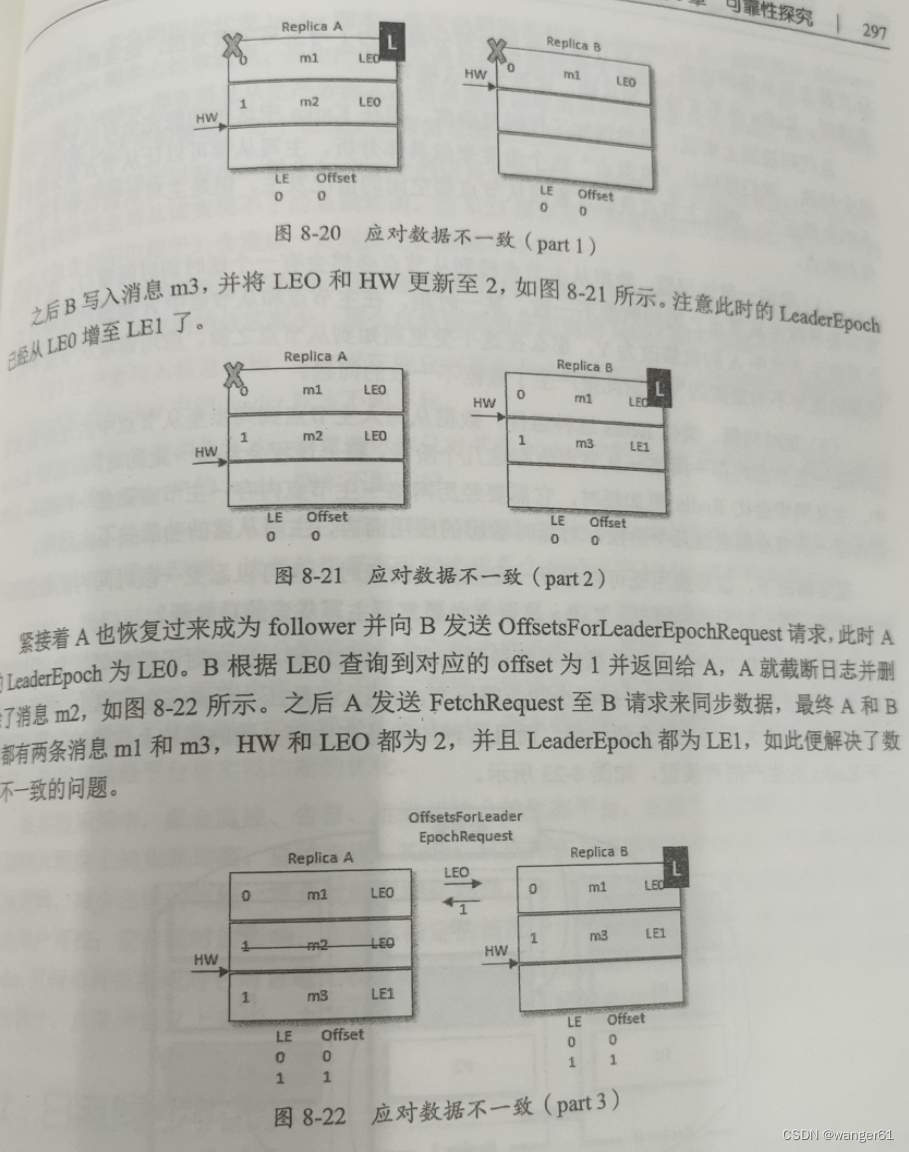
具体的同步流程如下:
初始A为leader,A有2条消息 m1 和 m2;
B为 follower,B有1条消息m1
假设A、B同时宕机,然后B第一个恢复过来成为新的 leader
三、Kafka和Zookeeper数据同步机制比较
Zookeeper 采用 ZAB 一致性协议,总的来讲就是“少数服从多数”,只要一半以上的数据同步成功即为同步成功
“少数服从多数”有一个很大的优势,系统的延迟取决于最快的几个节点。但是它所能容忍的失败 follower比较少(一半以下),因此生产环境下为了保证较高的容错率,必须要有大量副本,而大量副本在大数据量下会导致性能的急剧下降。因此“少数服从多数”模型通常会被用作共享集群配置(如 Zookeeper),而很少用于主流的数据存储。
Kafka写入消息时只有等到所有 ISR 集合中的副本都确认收到后才能被认为已提交,这种方式会使所需要的副本总数变小,复制带来的集群开销降低。
此外,在数据恢复上,Kafka不需要宕机节点必须从本地数据日志中进行恢复,Kafka 的同步方式允许宕机副本重新加入 ISR 集合,但在进入 ISR 之前必须保证自己能够重新同步完 leader 中的所有数据
四、Kafka为什么不支持读写分离
前面提到了,Kafka采用了主写主读的方式,副本仅仅提供了数据容错功能,为什么 Kafka 不采用读写分离的方式呢
首先,主写从读存在2个很明显的缺点:
- 数据一致性问题。数据从主节点同步到从接到必然会有一个延时,在该时间段内如果去读从节点的数据,读到的值不是最新的,从而会产生数据不一致的问题
- 延时问题。数据从主节点同步到从节点必然存在延时的问题,对于延时敏感的应用而言,主写从读不太适用
读写分离的主要作用是分摊负载,而 Kafka 本身就能很好的做到负载均衡, Kafka 会自动将主从节点均匀的分布在 broker 上,因此 Kafka 可以通过主写主读实现主写从读实现不了的负载均衡
总的来说,Kafka 只支持主写主读有几个优点:
- 简化代码的实现逻辑,减少出错的可能
- 将负载均衡细化均摊,与主写从读相比,不仅负载效能更好,而且对用户可控
- 没有延时的影响
- 在副本稳定的情况下,不会出现数据不一致的情况
五、如何提高Kafka的可靠性
可以通过合理设置以下设置来提高Kafka的可靠性:
- 副本数量:一般设置为3即可满足绝大多数场景的可靠性要求,对于可靠性要求极高的场景,可以适当增大这个值
- acks:设置为-1保证数据 leader 和 follower 均同步完成并写入本地日志
- retries:有些发送异常属于可重试异常,对于高可靠性场景,需要将该值设置为大于1
- enable.auto.commit:默认为true自动提交位移,可能会造成重复消费和消息丢失。对于可靠性要求高的场景应该设置为手动提交
- min.insync.replicas:指定ISR集合中的最小副本数,如果不满足条件就会抛出 NotEnoughReplicasException 或 NotEnoughReplicasAfterAppendException异常。在副本数为3时,可以设置该参数为2















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









