









如何自学Python爬虫?在大家自学爬虫之前要解决两个常见的问题,一是爬虫到底是什么?二是问什么要用Python来做爬虫?爬虫其实就是自动抓取页面信息的网络机器人,至于用Python做爬虫的原因,当然还是为了方便。本文将为大家提供一份详细的新手入门教程,带大家从入门到精通Python爬虫技能

一、爬虫是什么?
网络爬虫又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者。它是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序。其实,说白了就是爬虫可以模拟浏览器的行为做你想做的事,订制化自己搜索和下载的内容,并实现自动化的操作。比如浏览器可以下载小说,但是有时候并不能批量下载,那么爬虫的功能就有用武之地了。
二、为什么python适合做爬虫?
实现爬虫技术的编程环境有很多种,Java,Python,C++等都可以用来爬虫。但是为什么大家都选择了Python,还是因为Python确实很适合做爬虫,丰富的第三方库十分强大,简单几行代码便可实现你想要的功能;跨平台,对Linux和windows都有不错的支持。更重要的,Python也是数据挖掘和分析的好能手。这样爬取数据和分析数据一条龙的服务都用Python真的很便捷。
三、自学Python爬虫有哪些步骤?
1、首先学会基本的Python语法知识
2、学习Python爬虫常用到的几个重要内置库urllib, http等,用于下载网页
3、学习正则表达式re、BeautifulSoup(bs4)、Xpath(lxml)等网页解析工具
4、开始一些简单的网站爬取(博主从百度开始的,哈哈),了解爬取数据过程
5、了解爬虫的一些反爬机制,header,robot,时间间隔,代理ip,隐含字段等
6、学习一些特殊网站的爬取,解决登录、Cookie、动态网页等问题
7、了解爬虫与数据库的结合,如何将爬取数据进行储存
8、学习应用Python的[多线程]、[多进程]进行爬取,提高爬虫效率
9、学习爬虫的框架,[Scrapy]、PySpider等
10、学习分布式爬虫(数据量庞大的需求)
读者福利:知道你对Python感兴趣,便准备了这套python学习资料
👉[[CSDN大礼包:《python兼职资源&全套学习资料》免费分享]](安全链接,放心点击)
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习等习教程。带你从零基础系统性的学好Python!
零基础Python学习资源介绍
- ① Python所有方向的学习路线图,清楚各个方向要学什么东西
- ② 600多节Python课程视频,涵盖必备基础、爬虫和数据分析
- ③ 100多个Python实战案例,含50个超大型项目详解,学习不再是只会理论
- ④ 20款主流手游迫解 爬虫手游逆行迫解教程包
- ⑤ 爬虫与反爬虫攻防教程包,含15个大型网站迫解
- ⑥ 爬虫APP逆向实战教程包,含45项绝密技术详解
- ⑦ 超300本Python电子好书,从入门到高阶应有尽有
- ⑧ 华为出品独家Python漫画教程,手机也能学习
- ⑨ 历年互联网企业Python面试真题,复习时非常方便
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)

👉Python必备开发工具👈
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉100道Python练习题👈
检查学习结果。

👉面试刷题👈
👉python副业兼职与全职路线👈
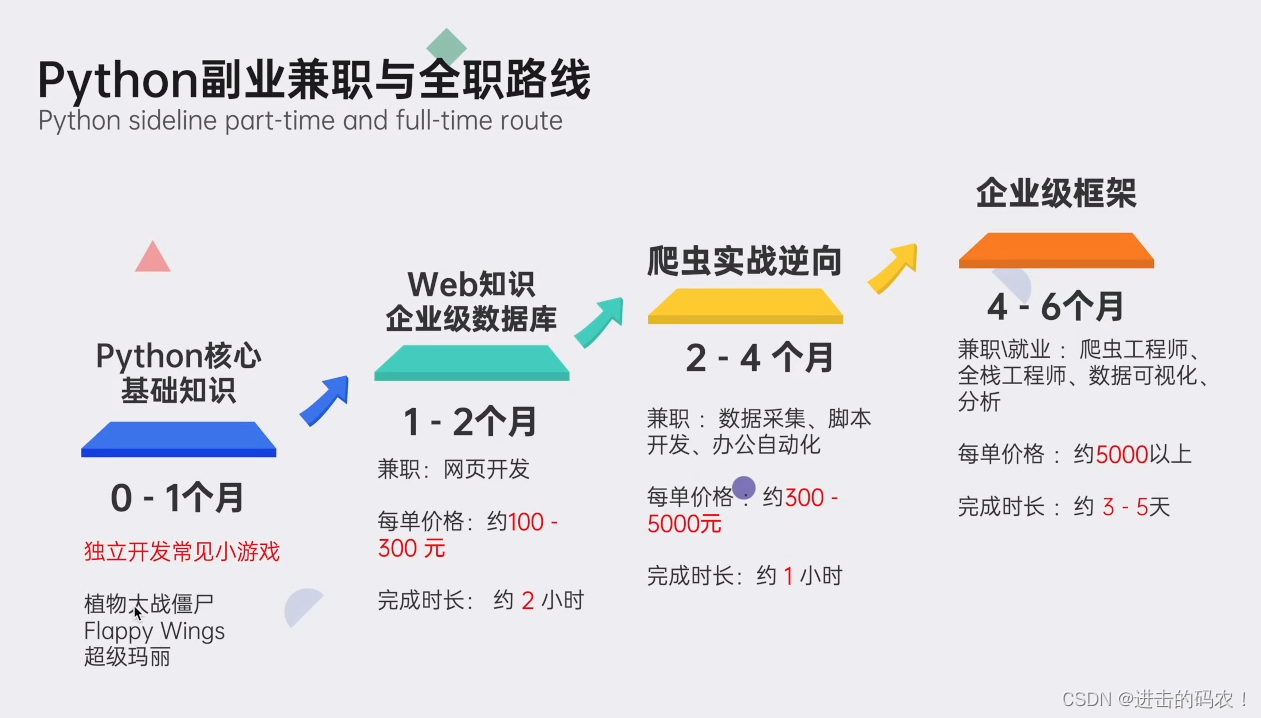
上述这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以微信扫描下方CSDN官方认证二维码 即可领取↓↓↓















 4821
4821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









