







上升的温度
表: Weather
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| recordDate | date |
| temperature | int |
+---------------+---------+
id 是这个表的主键
该表包含特定日期的温度信息
编写一个 SQL 查询,来查找与之前(昨天的)日期相比温度更高的所有日期的 id 。
返回结果 不要求顺序 。
查询结果格式如下例。
输入:
Weather 表:
+----+------------+-------------+
| id | recordDate | Temperature |
+----+------------+-------------+
| 1 | 2015-01-01 | 10 |
| 2 | 2015-01-02 | 25 |
| 3 | 2015-01-03 | 20 |
| 4 | 2015-01-04 | 30 |
+----+------------+-------------+
输出:
+----+
| id |
+----+
| 2 |
| 4 |
+----+
SELECT
weather.id AS 'Id'
FROM
weather JOIN weather as wea
ON
DATEDIFF(weather.recordDate,wea.recordDate)=1
and
weather.Temperature>wea.Temperature;
补充:datediff()函数的用法
DATEDIFF() 函数返回两个日期之间的天数
详细教程
销售员
表: SalesPerson
+-----------------+---------+
| Column Name | Type |
+-----------------+---------+
| sales_id | int |
| name | varchar |
| salary | int |
| commission_rate | int |
| hire_date | date |
+-----------------+---------+
sales_id 是该表的主键列。
该表的每一行都显示了销售人员的姓名和 ID ,以及他们的工资、佣金率和雇佣日期。
表: Company
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| com_id | int |
| name | varchar |
| city | varchar |
+-------------+---------+
com_id 是该表的主键列。
该表的每一行都表示公司的名称和 ID ,以及公司所在的城市。
表: Orders
+-------------+------+
| Column Name | Type |
+-------------+------+
| order_id | int |
| order_date | date |
| com_id | int |
| sales_id | int |
| amount | int |
+-------------+------+
order_id 是该表的主键列。
com_id 是 Company 表中 com_id 的外键。
sales_id 是来自销售员表 sales_id 的外键。
该表的每一行包含一个订单的信息。这包括公司的 ID 、销售人员的 ID 、订单日期和支付的金额。
编写一个SQL查询,报告没有任何与名为 “RED” 的公司相关的订单的所有销售人员的姓名。
select s.name
from SalesPerson as s
where s.sales_id not in
( select sales_id
from
Orders left join Company on Orders.com_id=Company.com_id
where Company.name='RED')
查询近三十天活跃用户数
活动记录表:Activity
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| user_id | int |
| session_id | int |
| activity_date | date |
| activity_type | enum |
+---------------+---------+
该表是用户在社交网站的活动记录。
该表没有主键,可能包含重复数据。
activity_type 字段为以下四种值 (‘open_session’, ‘end_session’, ‘scroll_down’, ‘send_message’)。
每个 session_id 只属于一个用户。
请写SQL查询出截至 2019-07-27(包含2019-07-27),近 30 天的每日活跃用户数(当天只要有一条活动记录,即为活跃用户)。
select activity_date AS day,
count(distinct user_id) AS active_users
from Activity
where datediff('2019-07-27', activity_date) between 0 and 29
group by day
只要与日期相关的查询绝对少不了datediff()函数
每天的领导和合伙人
表:DailySales
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| date_id | date |
| make_name | varchar |
| lead_id | int |
| partner_id | int |
+-------------+---------+
该表没有主键。
该表包含日期、产品的名称,以及售给的领导和合伙人的编号。
名称只包含小写英文字母。
写一条 SQL 语句,使得对于每一个 date_id 和 make_name,返回不同的 lead_id 以及不同的 partner_id 的数量。
select date_id,
make_name,
count(distinct lead_id) AS unique_leads,
count(distinct partner_id) AS unique_partners
from DailySales
group by date_id,
make_name
求关注者的数量
表: Followers
+-------------+------+
| Column Name | Type |
+-------------+------+
| user_id | int |
| follower_id | int |
+-------------+------+
(user_id, follower_id) 是这个表的主键。
该表包含一个关注关系中关注者和用户的编号,其中关注者关注用户。
写出 SQL 语句,对于每一个用户,返回该用户的关注者数量。
按 user_id 的顺序返回结果表。
select user_id ,count(distinct follower_id)followers_count
from Followers
group by user_id
订单最多的客户
表: Orders
+-----------------+----------+
| Column Name | Type |
+-----------------+----------+
| order_number | int |
| customer_number | int |
+-----------------+----------+
Order_number是该表的主键。
此表包含关于订单ID和客户ID的信息。
编写一个SQL查询,为下了 最多订单 的客户查找 customer_number 。
测试用例生成后, 恰好有一个客户 比任何其他客户下了更多的订单。
select customer_number
from Orders
group by customer_number
order by count(order_number ) desc
limit 1
游戏玩法分析
活动表 Activity:
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| player_id | int |
| device_id | int |
| event_date | date |
| games_played | int |
+--------------+---------+
表的主键是 (player_id, event_date)。
这张表展示了一些游戏玩家在游戏平台上的行为活动。
每行数据记录了一名玩家在退出平台之前,当天使用同一台设备登录平台后打开的游戏的数目(可能是 0 个)。
写一条 SQL 查询语句获取每位玩家 第一次登陆平台的日期。
select player_id,min(event_date) AS first_login
from Activity
group by player_id
查找每个员工花费的总时间
表: Employees
+-------------+------+
| Column Name | Type |
+-------------+------+
| emp_id | int |
| event_day | date |
| in_time | int |
| out_time | int |
+-------------+------+
(emp_id, event_day, in_time) 是这个表的主键。
该表显示了员工在办公室的出入情况。
event_day 是此事件发生的日期,in_time 是员工进入办公室的时间,而 out_time 是他们离开办公室的时间。
in_time 和 out_time 的取值在1到1440之间。
题目保证同一天没有两个事件在时间上是相交的,并且保证 in_time 小于 out_time。
编写一个SQL查询以计算每位员工每天在办公室花费的总时间(以分钟为单位)。 请注意,在一天之内,同一员工是可以多次进入和离开办公室的。 在办公室里一次进出所花费的时间为out_time 减去 in_time。
2020年最后一次登录
Logins
+----------------+----------+
| 列名 | 类型 |
+----------------+----------+
| user_id | int |
| time_stamp | datetime |
+----------------+----------+
(user_id, time_stamp) 是这个表的主键。
每一行包含的信息是user_id 这个用户的登录时间。
编写一个 SQL 查询,该查询可以获取在 2020 年登录过的所有用户的本年度 最后一次 登录时间。结果集 不 包含 2020 年没有登录过的用户。
返回的结果集可以按 任意顺序 排列。
select user_id,
max(time_stamp) AS last_stamp
from Logins
where year(time_stamp)='2020'
group by user_id
题目解析:
最早的时间就是最小的时间用min()
最晚的时间就是最大的时间用max()
在某一年就是year(time)=‘2020’
股票的资本收益
Stocks 表:
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| stock_name | varchar |
| operation | enum |
| operation_day | int |
| price | int |
+---------------+---------+
(stock_name, day) 是这张表的主键
operation 列使用的是一种枚举类型,包括:(‘Sell’,‘Buy’)
此表的每一行代表了名为 stock_name 的某支股票在 operation_day 这一天的操作价格。
保证股票的每次’Sell’操作前,都有相应的’Buy’操作。
编写一个SQL查询来报告每支股票的资本损益。
股票的资本损益是一次或多次买卖股票后的全部收益或损失。
select stock_name,
sum( case operation
when 'Sell' then price else -price
end
) as capital_gain_loss
from Stocks
group by stock_name
排名考靠前的旅行者
表:Users
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| name | varchar |
+---------------+---------+
id 是该表单主键。
name 是用户名字。
表:Rides
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| user_id | int |
| distance | int |
+---------------+---------+
id 是该表单主键。
user_id 是本次行程的用户的 id, 而该用户此次行程距离为 distance 。
写一段 SQL , 报告每个用户的旅行距离。
返回的结果表单,以 travelled_distance 降序排列 ,如果有两个或者更多的用户旅行了相同的距离, 那么再以 name 升序排列 。
select u.name,if(sum(distance) is null,0,sum(distance)) as travelled_distance
from users u left join rides r on u.id = r.user_id
group by u.id
order by travelled_distance desc,u.name
市场分析
Table: Users
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| user_id | int |
| join_date | date |
| favorite_brand | varchar |
+----------------+---------+
此表主键是 user_id。
表中描述了购物网站的用户信息,用户可以在此网站上进行商品买卖。
Table: Orders
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| order_id | int |
| order_date | date |
| item_id | int |
| buyer_id | int |
| seller_id | int |
+---------------+---------+
此表主键是 order_id。
外键是 item_id 和(buyer_id,seller_id)。
Table: Items
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| item_id | int |
| item_brand | varchar |
+---------------+---------+
此表主键是 item_id。
请写出一条SQL语句以查询每个用户的注册日期和在 2019 年作为买家的订单总数。
select Users.user_id as buyer_id, join_date, ifnull(UserBuy.cnt, 0) as orders_in_2019
from Users
left join (
select buyer_id, count(order_id) cnt
from Orders
where order_date between '2019-01-01' and '2019-12-31'
group by buyer_id
) UserBuy
on Users.user_id = UserBuy.buyer_id
题目解析:
ifnull(x1,x2): 如果x1为空则为null,返回x2,否则返回x1
链表的中间节点
给定一个头结点为 head 的非空单链表,返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
输入:[1,2,3,4,5]
输出:此列表中的结点 3 (序列化形式:[3,4,5])
返回的结点值为 3 。 (测评系统对该结点序列化表述是 [3,4,5])。
注意,我们返回了一个 ListNode 类型的对象 ans,这样:
ans.val = 3, ans.next.val = 4, ans.next.next.val = 5, 以及 ans.next.next.next = NULL.
class Solution {
public ListNode middleNode(ListNode head) {
ListNode a=head,b=head;
while(b.next!=null){
a=a.next;
b=b.next;
if(b.next==null){
return a;
}
b=b.next;
}
return a;
}}
删除链表的倒数第N个节点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode dummy = new ListNode(0, head);
ListNode first = head;
ListNode second = dummy;
for (int i = 0; i < n; ++i) {
first = first.next;
}
while (first != null) {
first = first.next;
second = second.next;
}
second.next = second.next.next;
ListNode ans = dummy.next;
return ans;
}
}
题目解析:
1.双指针法,
2.计算链表长度
3.栈
无重复字符的最长字串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
输入: s = “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
双指针滑动
class Solution {
public int lengthOfLongestSubstring(String s) {
// 记录字符上一次出现的位置
int[] last = new int[128];
for(int i = 0; i < 128; i++) {
last[i] = -1;
}
int n = s.length();
int res = 0;
int start = 0; // 窗口开始位置
for(int i = 0; i < n; i++) {
int index = s.charAt(i);
start = Math.max(start, last[index] + 1);
res = Math.max(res, i - start + 1);
last[index] = i;
}
return res;
}
}
字符串的排列
给你两个字符串 s1 和 s2 ,写一个函数来判断 s2 是否包含 s1 的排列。如果是,返回 true ;否则,返回 false
换句话说,s1 的排列之一是 s2 的 子串 。
输入:s1 = “ab” s2 = “eidbaooo”
输出:true
解释:s2 包含 s1 的排列之一 (“ba”).
注意该题中说的是 排列之一为,不是包含一样的字串
class Solution {
public boolean checkInclusion(String s1, String s2) {
int n = s1.length(), m = s2.length();
if (n > m) {
return false;
}
int[] cnt1 = new int[26];
int[] cnt2 = new int[26];
for (int i = 0; i < n; ++i) {
++cnt1[s1.charAt(i) - 'a'];
++cnt2[s2.charAt(i) - 'a'];
}
if (Arrays.equals(cnt1, cnt2)) {
return true;
}
for (int i = n; i < m; ++i) {
++cnt2[s2.charAt(i) - 'a'];
--cnt2[s2.charAt(i - n) - 'a'];
if (Arrays.equals(cnt1, cnt2)) {
return true;
}
}
return false;
}
}
图像渲染
有一幅以 m x n 的二维整数数组表示的图画 image ,其中 image[i][j] 表示该图画的像素值大小。
你也被给予三个整数 sr , sc 和 newColor 。你应该从像素 image[sr][sc] 开始对图像进行 上色填充 。
为了完成 上色工作 ,从初始像素开始,记录初始坐标的 上下左右四个方向上 像素值与初始坐标相同的相连像素点,接着再记录这四个方向上符合条件的像素点与他们对应 四个方向上 像素值与初始坐标相同的相连像素点,……,重复该过程。将所有有记录的像素点的颜色值改为 newColor 。
最后返回 经过上色渲染后的图像
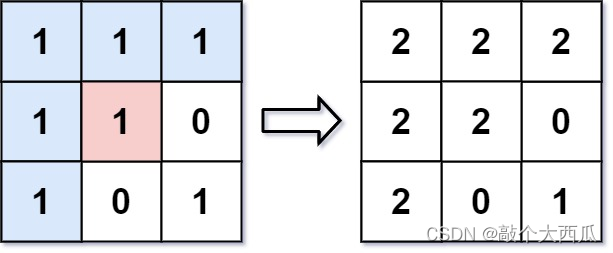
输入: image = [[1,1,1],[1,1,0],[1,0,1]],sr = 1, sc = 1, newColor = 2
输出: [[2,2,2],[2,2,0],[2,0,1]]
解析: 在图像的正中间,(坐标(sr,sc)=(1,1)),在路径上所有符合条件的像素点的颜色都被更改成2。
注意,右下角的像素没有更改为2,因为它不是在上下左右四个方向上与初始点相连的像素点
class Solution {
int[] dx = {1, 0, 0, -1};
int[] dy = {0, 1, -1, 0};
public int[][] floodFill(int[][] image, int sr, int sc, int newColor) {
int currColor = image[sr][sc];
if (currColor == newColor) {
return image;
}
int n = image.length, m = image[0].length;
Queue<int[]> queue = new LinkedList<int[]>();
queue.offer(new int[]{sr, sc});
image[sr][sc] = newColor;
while (!queue.isEmpty()) {
int[] cell = queue.poll();
int x = cell[0], y = cell[1];
for (int i = 0; i < 4; i++) {
int mx = x + dx[i], my = y + dy[i];
if (mx >= 0 && mx < n && my >= 0 && my < m && image[mx][my] == currColor) {
queue.offer(new int[]{mx, my});
image[mx][my] = newColor;
}
}
}
return image;
}
}
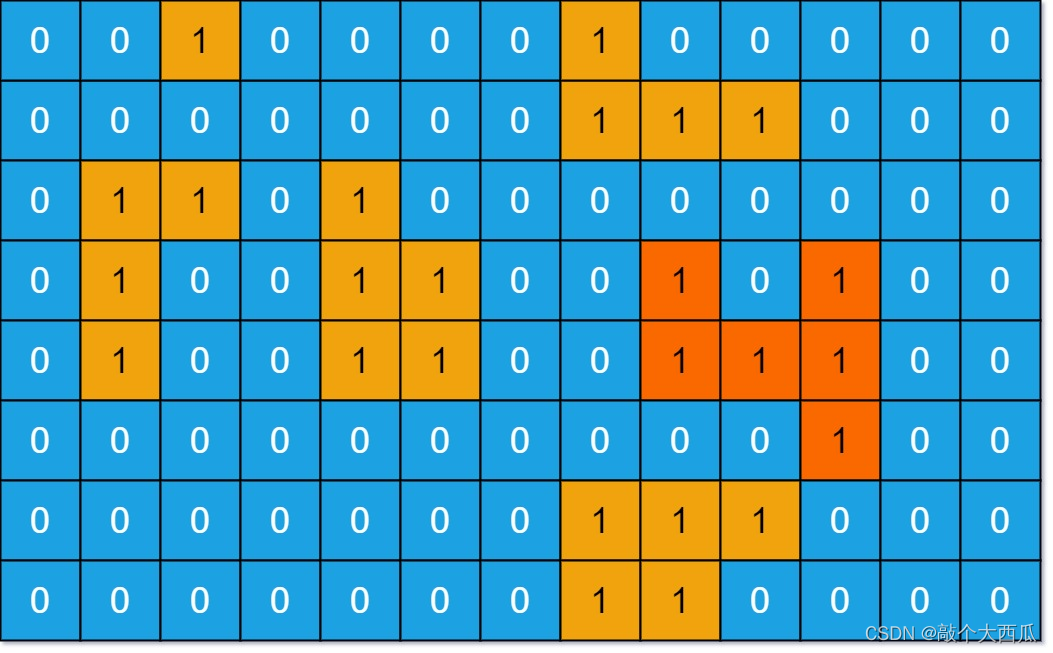
岛屿的最大面积
给你一个大小为 m x n 的二进制矩阵 grid 。
岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
岛屿的面积是岛上值为 1 的单元格的数目。
计算并返回 grid 中最大的岛屿面积。如果没有岛屿,则返回面积为 0
class Solution {
public int maxAreaOfIsland(int[][] grid) {
int ans = 0;
for (int i = 0; i != grid.length; ++i) {
for (int j = 0; j != grid[0].length; ++j) {
int cur = 0;
Queue<Integer> queuei = new LinkedList<Integer>();
Queue<Integer> queuej = new LinkedList<Integer>();
queuei.offer(i);
queuej.offer(j);
while (!queuei.isEmpty()) {
int cur_i = queuei.poll(), cur_j = queuej.poll();
if (cur_i < 0 || cur_j < 0 || cur_i == grid.length || cur_j == grid[0].length || grid[cur_i][cur_j] != 1) {
continue;
}
++cur;
grid[cur_i][cur_j] = 0;
int[] di = {0, 0, 1, -1};
int[] dj = {1, -1, 0, 0};
for (int index = 0; index != 4; ++index) {
int next_i = cur_i + di[index], next_j = cur_j + dj[index];
queuei.offer(next_i);
queuej.offer(next_j);
}
}
ans = Math.max(ans, cur);
}
}
return ans;
}
}
合并二叉树
给你两棵二叉树: root1 和 root2 。
想象一下,当你将其中一棵覆盖到另一棵之上时,两棵树上的一些节点将会重叠(而另一些不会)。你需要将这两棵树合并成一棵新二叉树。合并的规则是:如果两个节点重叠,那么将这两个节点的值相加作为合并后节点的新值;否则,不为 null 的节点将直接作为新二叉树的节点。
返回合并后的二叉树。
注意: 合并过程必须从两个树的根节点开始。
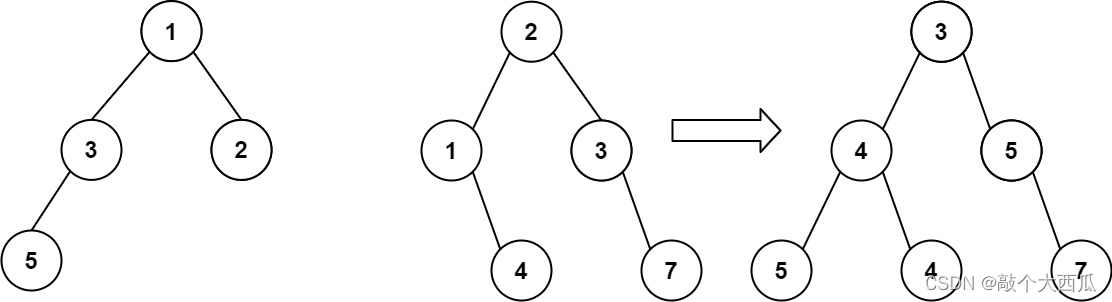
输入:root1 = [1,3,2,5], root2 = [2,1,3,null,4,null,7]
输出:[3,4,5,5,4,null,7]
class Solution {
public TreeNode mergeTrees(TreeNode t1, TreeNode t2) {
if (t1 == null) {
return t2;
}
if (t2 == null) {
return t1;
}
TreeNode merged = new TreeNode(t1.val + t2.val);
merged.left = mergeTrees(t1.left, t2.left);
merged.right = mergeTrees(t1.right, t2.right);
return merged;
}
}
填充每个节点的下一个右侧节点
给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
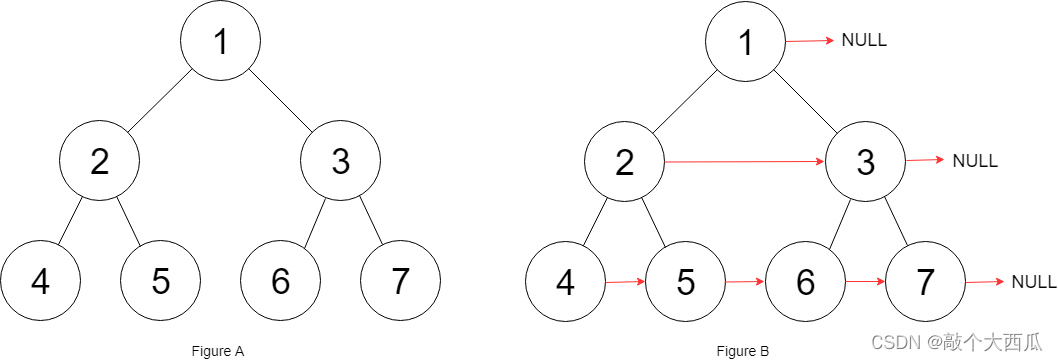
输入:root = [1,2,3,4,5,6,7]
输出:[1,#,2,3,#,4,5,6,7,#]
解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化的输出按层序遍历排列,同一层节点由 next 指针连接,‘#’ 标志着每一层的结束。
示例 2:
输入:root = []
输出:[]
class Solution {
public Node connect(Node root) {
if (root == null) {
return root;
}
// 初始化队列同时将第一层节点加入队列中,即根节点
Queue<Node> queue = new LinkedList<Node>();
queue.add(root);
// 外层的 while 循环迭代的是层数
while (!queue.isEmpty()) {
// 记录当前队列大小
int size = queue.size();
// 遍历这一层的所有节点
for (int i = 0; i < size; i++) {
// 从队首取出元素
Node node = queue.poll();
// 连接
if (i < size - 1) {
node.next = queue.peek();
}
// 拓展下一层节点
if (node.left != null) {
queue.add(node.left);
}
if (node.right != null) {
queue.add(node.right);
}
}
}
// 返回根节点
return root;
}
}
层序遍历,一种处理二叉树很重要的东西
从上到下打印二叉树 |
从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印。
例如:
给定二叉树: [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回:
[3,9,20,15,7]
class Solution {
public int[] levelOrder(TreeNode root) {
if (root==null){
return new int[0];
}
Queue<TreeNode> queue=new LinkedList<>( );
queue.add( root );
ArrayList<Integer> ans=new ArrayList<>( );
while (!queue.isEmpty()){
TreeNode node=queue.poll();
ans.add( node.val );
if (node.left!=null) queue.add( node.left );
if (node.right!=null) queue.add( node.right );
}
int[] res=new int[ans.size()];
for (int i=0;i<ans.size();i++){
res[i]=ans.get( i );
}
return res;
}
}
从上到下按层打印二叉树||
从上到下按层打印二叉树,同一层的节点按从左到右的顺序打印,每一层打印到一行。
例如:
给定二叉树: [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其层次遍历结果:
[
[3],
[9,20],
[15,7]
]
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
List<List<Integer>> res = new ArrayList<>();
if(root != null) queue.add(root);
while(!queue.isEmpty()) {
List<Integer> tmp = new ArrayList<>();
for(int i = queue.size(); i > 0; i--) {
TreeNode node = queue.poll();
tmp.add(node.val);
if(node.left != null) queue.add(node.left);
if(node.right != null) queue.add(node.right);
}
res.add(tmp);
}
return res;
}
}
从上到下打印二叉树|||
请实现一个函数按照之字形顺序打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右到左的顺序打印,第三行再按照从左到右的顺序打印,其他行以此类推。
给定二叉树: [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其层次遍历结果:
[
[3],
[20,9],
[15,7]
]
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
List<List<Integer>> res = new ArrayList<>();
if(root != null) queue.add(root);
while(!queue.isEmpty()) {
LinkedList<Integer> tmp = new LinkedList<>();
for(int i = queue.size(); i > 0; i--) {
TreeNode node = queue.poll();
if(res.size() % 2 == 0) tmp.addLast(node.val); // 偶数层 -> 队列头部
else tmp.addFirst(node.val); // 奇数层 -> 队列尾部
if(node.left != null) queue.add(node.left);
if(node.right != null) queue.add(node.right);
}
res.add(tmp);
}
return res;
}
}














 210
210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









