







线上问题
未及时加监控,导致线上redis被逐出,业务有损
示例:
一个key临时存储在redis等缓存中,如果该key在一段时间内有很大作用
比如一次业务请求,上游服务写入一个value,时长1小时,下游服务需要在1小时内读取它,并完成核心逻辑
如果被逐出后,导致下游拿不到数据,使得此次请求带来也业务问题
解决方法
redis 80%容量时添加监控,及时告警,及时进行业务处理。
学习文档
https://juejin.cn/post/6921884079830859789
影响
内存数据库,当其使用的内存超过物理内存限制后,内存和磁盘产生频繁的数据交换
导致Redis性能急剧下降
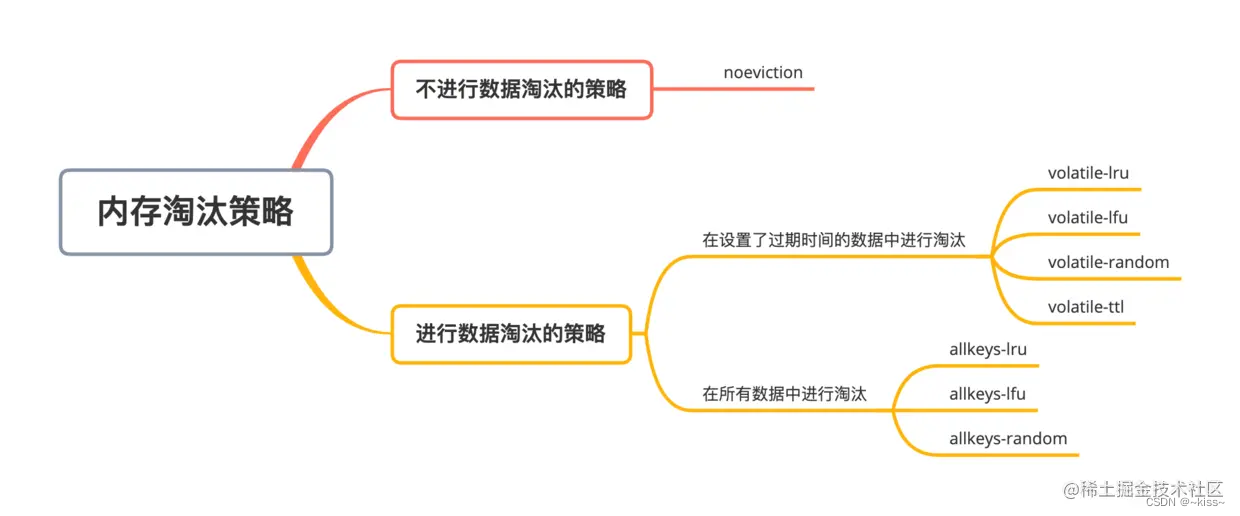
策略
通过配置参数maxmemoey来限制使用的内存大小。
当实际使用内存超过maxmemoey后,Redis提供了如下几种可选策略。
noeviction:(不驱逐,eviction表示驱逐)写请求返回错误
volatile-lru:使用lru算法删除设置了过期时间的键值对
volatile-lfu:使用lfu算法删除设置了过期时间的键值对
volatile-random:在设置了过期时间的键值对中随机进行删除
volatile-ttl:根据过期时间的先后进行删除,越早过期的越先被删除
allkeys-lru:在所有键值对中,使用lru算法进行删除
allkeys-lfu:在所有键值对中,使用lfu算法进行删除
allkeys-random:所有键值对中随机删除
附录
LRU - Least Recently Used
最近最少使用
最近访问的数据,后续很大概率还会被访问到
长时间未被访问的数据,应该被淘汰
LRU算法中数据会被放到一个链表中
链表的头节点为最近被访问的数据
链表的尾节点为长时间没有被访问的数据
LRU算法的核心实现是哈希表+双向链表
链表用来维护访问元素的顺序,哈希表可以在O(1)时间复杂度下进行元素访问
为什么是双向链表呢?
删除元素的话,需要获取前继节点
LFU - Least Frequently Used
LRU算法有一个问题,当一个长时间不被访问的key,偶尔被访问一下后,可能会造成一个比该key访问更频繁的key被淘汰。
LRU算法对key的冷热程度判断不准确。
最不经常使用
按照访问频率来判断key的冷热程度,每次删除的是一段时间内访问频率较低的数据,比LRU算法更准确
如何设计?
-
需要存储k-v的map:keyToVal
-
需要存储某个k的访问频次的map:keyToFreq
-
需要存储当前系统最小的访问频次:minFreq
-
当缓存满时有数据k2需要插入,需要先O1寻找访问频次最低且插入最早的k1,然后删除它,接着O1更新k2的访问频次
某个访问频次的k可能不止一个,有多个,如何O1找到这些k,用访问频次-集合的存储:freqTokeys
如何从找到的集合中O1找到插入最早的k1,用双向链表,表头作为该频次中插入最早的元素。
最终选择既有O1找到集合的map+O1找到插入最早的k1 -> HashMap<Integer, LinkedHashSet>LinkedHashSet类,链表和集合的结合体
链表不能快速删除元素,但是能保证插入顺序
集合内部元素无序,但是能快速删除元素(O(lgN))
LinkedHashSet是一种在迭代其元素时可以返回它们被插入的顺序的set(集合类型)
也就是说,它可以保证元素的插入与访问顺序。
private HashMap<K, V> keyToVal; // HashMap
private HashMap<K, Integer> keyToFreq; // HashMap
private int minFreq;
private int capacity;
private HashMap<Integer, LinkedHashSet<K>> freqTokeys;
public class LfuCache<K, V> {
private HashMap<K, V> keyToVal;
private HashMap<K, Integer> keyToFreq;
private HashMap<Integer, LinkedHashSet<K>> freqTokeys;
private int minFreq;
private int capacity;
public LfuCache(int capacity) {
keyToVal = new HashMap<>();
keyToFreq = new HashMap<>();
freqTokeys = new HashMap<>();
this.capacity = capacity;
this.minFreq = 0;
}
public V get(K key) {
V v = keyToVal.get(key);
if (v == null) {
return null;
}
// 如果k存在,则增加访问频次
increaseFrey(key);
return v;
}
public void put(K key, V value) {
// get方法里面会增加频次
if (get(key) != null) {
// 重新设置值
keyToVal.put(key, value);
return;
}
// 超出容量,删除频率最低的key 【逐出策略】
if (keyToVal.size() >= capacity) {
removeMinFreqKey();
}
// 能进入到这里说明:最小访问频次一定是1
// k-v插入
keyToVal.put(key, value);
// k-访问频次插入
keyToFreq.put(key, 1);
// freqTokeys中,key对应的value存在,返回存在的key;不存在,添加key和value
// 不存在则创建一个新的LinkedHashSet并插入
freqTokeys.putIfAbsent(1, new LinkedHashSet<>());
// 访问频次为1的集合中,有序插入当前key
freqTokeys.get(1).add(key);
// 系统最小访问频次一定是1
this.minFreq = 1;
}
// 【逐出策略】
// 删除出现频率最低且插入最早的key
private void removeMinFreqKey() {
// 找到最小访问频次对应的 LinkedHashSet<K> 集合&列表
LinkedHashSet<K> keyList = freqTokeys.get(minFreq);
// 获取keyList中的第一个元素
// iterator()方法返回一个在一系列元素上进行迭代的迭代器
// next()方法获取迭代器当前位置的下一个元素
K deleteKey = keyList.iterator().next();
// 从 keyList 中删除链表第一个节点,如果keyList中只有一个元素,则将整个keyList删除
keyList.remove(deleteKey);
if (keyList.isEmpty()) {
// 这里删除元素后不需要重新设置minFreq,因为put方法执行完会将minFreq设置为1
freqTokeys.remove(keyList);
}
// k-v中逐出
keyToVal.remove(deleteKey);
// k-访问频次中逐出
keyToFreq.remove(deleteKey);
}
// 增加频率
private void increaseFrey(K key) {
// 获取当前key的访问频次
int freq = keyToFreq.get(key);
// 当前key的访问频次+1
keyToFreq.put(key, freq + 1);
// 当前访问频次中维护的key集合中,删除当前key
freqTokeys.get(freq).remove(key);
// 当前访问频次+1中维护的key集合中,插入当前key(如果LinkedHashSet不存在,则先new一个)
freqTokeys.putIfAbsent(freq + 1, new LinkedHashSet<>());
freqTokeys.get(freq + 1).add(key);
// 当前访问频次中维护的key集合为空,则remove掉该LinkedHashSet
if (freqTokeys.get(freq).isEmpty()) {
freqTokeys.remove(freq);
// remove掉该LinkedHashSet,代表系统中最小的访问频次为 this.minFreq++
if (freq == this.minFreq) {
this.minFreq++;
}
}
}
}
















 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









