






阿拉伯语属阿非罗一亚细亚语系闪米特语族,是世界主要语言之一,是西亚和北非22个国家和地区的官方语言,使用人口约2亿。它是联合国6种工作语言之一,是全世界穆斯林通用的语言。阿语方言众多,现代标准阿拉伯语采用以《古兰经》为代表的典范的文学语言,书面语与口语不尽相同,与大马士革方言接近。
阿拉伯语有28个字母,都是辅音。元音没有字母(其实字母ى和و表示i和u,字母y与i的符号不同,u与w同用一个符号ِ),需要标记时采用专门的符号,如在《古兰经》、初级课本、辞书中使用,正式书报刊物中一般不使用。所有以阿拉伯字母为基础的文字都如此。

阿拉伯语字母表,第一列是写法,第二列是拉丁转写,第三列是字母的阿语名称读音。
有的朋友问:“阿拉伯语发音简单吗?”就音素而言,阿拉伯语有一半以上辅音音素(17个)是汉语普通话没有的,尤其是顶音、喉音,独具特色;就发音规则而言,阿拉伯语是一个字母对应唯一的音素,比人们熟悉的主要印欧语简单得多。
阿语大多数字母在书写时连写,因而在词首、词中、词末的写法是不同的。阿拉伯语的书写行款是从右到左横书,书本样式与中国以前的一样——是从右往左翻的。阿语图书、刊物都是这样印刷装订。
Windows XP自带阿拉伯语输入法,但是没有安装在输入法选项中。需要安装时,打开“控制面板”,双击“区域和语言选项”,选择“语言”选项卡,勾选“为复杂文字和从右到左的语言安装文件(包括泰文)”,然后点击“详细信息”进入“文字服务与输入语言”对话框,点击“添加”按钮,“输入语言”选择阿拉伯语,“键盘布局/输入法”选择一种阿拉伯语输入法(键盘布局),建议选择“沙特阿拉伯”,单击“确定”。下一步,在"文字服务与输入语言"对话框中选择“高级”选项卡,勾选“将高级文字服务支持应用于所有程序”,单击“应用”,重启计算机后,此项设置生效。安装阿拉伯语输入法以后,语言栏的输入法里显示“AR”。选择它,就可以按照阿文键盘(有的字符需要上档键)输入了。

阿拉伯语键盘表的一种 具体布局因键盘种类和国家而不同。
阿拉伯字母使用非常广泛。除了阿拉伯语,以阿拉伯字母为基础的文字有波斯文、乌尔都文、维吾尔文、哈萨克文、柯尔克孜文等,信德语、旁遮普语等在巴基斯坦使用乌尔都文书写。土耳其革命前土耳其文使用的也是阿拉伯字母。中亚很多语言原来使用阿拉伯字母,1921-1932年苏联将使用阿拉伯字母的语言改为拉丁字母,1936-1940年又全部改为斯拉夫字母。


字母
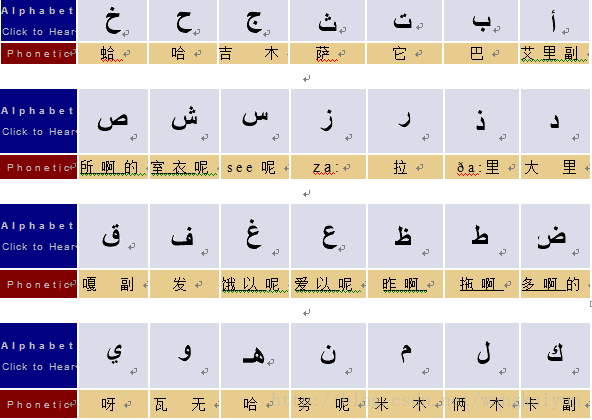
阿拉伯语字母表 nic.org,开放的网络天书!Image:Arabic alphabet.png
阿拉伯语字母表为阿拉伯语的书写形式,类似于希伯来文。这表明在很多书籍和杂志中,短元音并不被标出,所以人们必须从文中推测出这些元音。出现这种现象的原因是闪族语更多的使用辅音和长元音来区分词义。
阿拉伯语是连续书写的,这不同于每个文字都单独书写的象形文字。这意味着阿拉伯字母的书写形式会受到语境的影响。
在阿拉伯字母中,双辅音使用一个tashdeed(类似于w的符号)表明。
可兰经是使用阿拉伯字母表书写的,世界上有几种语言使用阿拉伯字母,包括乌尔都语。请参看阿拉伯书法。
| 目录 [隐藏] |
[编辑]
拼写
ا ب ة ت ث ج ح خ د ذ ر ز س ش ص ض ط ظ ع غ ف ق ك ل م ن ه
و ى ي
旧体字母: ٮ ٯ
[编辑]
阿拉伯数字
有两套数字体系:标准阿拉伯语数字和东阿拉伯语数字,使用于书写阿拉伯语的伊朗、巴基斯坦和印度。
| 标准阿拉伯语数字 | |
| ٠ | 0 |
| ١ | 1 |
| ٢ | 2 |
| ٣ | 3 |
| ٤ | 4 |
| ٥ | 5 |
| ٦ | 6 |
| ٧ | 7 |
| ٨ | 8 |
| ٩ | 9 |
| 东阿拉伯语数字 | |
| ۰ | 0 |
| ۱ | 1 |
| ۲ | 2 |
| ۳ | 3 |
| ۴ | 4 |
| ۵ | 5 |
| ۶ | 6 |
| ۷ | 7 |
| ۸ | 8 |
| ۹ | 9 |
[编辑]
连字符
ﷺ (Sall-allahu alayhiwasallam) - ﷲ (Allah)
关于阿拉伯语排序次序
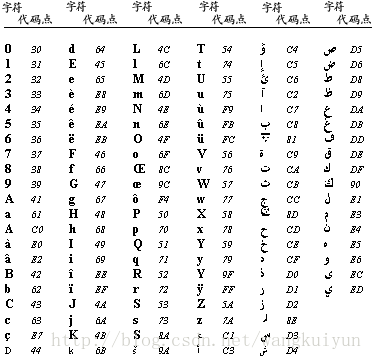
在这里,阿拉伯语排序次序是使用阿拉伯语代码页描述的,而不是使用Unicode (Unicode:Unicode Consortium开发的一种字符编码标准。该标准采用多(于一)个字节代表每一字符,实现了使用单个字符集代表世界上几乎所有书面语言。),因为大多数用户更熟悉前者。阿拉伯语排序次序表将阿拉伯语代码页的字符排列为一种排序次序。该排序次序控制了在使用阿拉伯语代码页的 Access数据库中如何对数据进行排序。
Access 使用来自Unicode的值,对从右到左数据库进行排序,而不是像以前版本那样使用来自从右到左代码页中的值。打开或导入的使用希伯来语代码页和希伯来语排序次序的数据库,将被转换为 Unicode和常规排序次序 (常规排序次序:默认排序次序决定字符在整个数据库(比如表、查询和报表中)的排序次序。如果要在多语言版本的 Access 中使用数据库,就要定义常规排序次序。)。
阿拉伯语代码页的 256 个字符组织为几种类别,以确定如何对字符进行排序。
Kashida (kashidas:用来延长两个阿拉伯字符之间的连接符的特殊字符。用于改进对齐后文本的外观,它所采用的是在视觉上加长单词而不是增加单词之间的间距。也可作为连字符使用)和双向 (双向:描述一种环境,从右向左和从左向右行为的属性同时在该环境下使用,如阿拉伯语和英语文本同时出现在一个句子中。)的控制字符 (控制字符:当继承的文本方向性不足以显示期望的结果时,插入从右向左和混合文本中以指定文本格式的字符。)(十六进制代码标记 9D、9E、DC、FD和 FE):
排序忽略这些字符。
阿拉伯语音调符号 (音调符号:在字符上面、下面或旁边打印的标记,用来指示其如何发音。)(十六位代码标记 F0 到 F3、F5、F6、F8和 FA):
除非所比较的字符串完全相同,否则排序忽略阿拉伯语音调符号。在字符串完全相同的情况下,未标记的字符(没有音调符号)排在标记的字符(有音调符号)前面;具有较低代码标记值的音调符号排在其他音调符号前面。
常规控制字符(十六位代码标记 00到1F和 7F)、保留字符(十六位代码标记80、81、8D、8E、8F和 90)和标点符号:
这三个类别按类别次序排在字母数字字符前面(即常规控制字符排在第一位),并且在每个类型中按升序排列代码标记次序(例如,00排在 01前面)。
阿拉伯语和从左到右 (从左向右:是指键盘设置、文档视图、用户界面对象以及文本的显示方向。英语和大多数其他欧洲语言都是从左向右语言。)字母数字字符(显示在后面的阿拉伯语排序次序表中):
从左到右文本总是排在阿拉伯语文本前面。
从左到右文本排序不区分大小写。例如,虽然大写“A”在排序表中排在小写“a”前面,但Access平等对待这两个字符,不对任何一个字母提供排序优先权。
未标记的从左到右文本(没有音调符号)排在标记的从左到右文本之前。
下表列出了阿拉伯语代码页的字母文字字符,还有它们各自的十六位代码标记。从左上角开始,字符(Char)按排序次序排列。
| U+ | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
| 0600 |
|
|
|
|
|
|
|
|
|
|
| ؋ | ، | ؍ | ؎ | ؏ |
| 0610 | ؐ | ؑ | ؒ | ؓ | ؔ | ؕ |
|
|
|
|
| ؛ |
|
| ؞ | ؟ |
| 0620 |
| ء | آ | أ | ؤ | إ | ئ | ا | ب | ة | ت | ث | ج | ح | خ | د |
| 0630 | ذ | ر | ز | س | ش | ص | ض | ط | ظ | ع | غ |
|
|
|
|
|
| 0640 | ـ | ف | ق | ك | ل | م | ن | ه | و | ى | ي | ً | ٌ | ٍ | َ | ُ |
| 0650 | ِ | ّ | ْ | ٓ | ٔ | ٕ | ٖ | ٗ | ٘ | ٙ | ٚ | ٛ | ٜ | ٝ | ٞ |
|
| 0660 | ٠ | ١ | ٢ | ٣ | ٤ | ٥ | ٦ | ٧ | ٨ | ٩ | ٪ | ٫ | ٬ | ٭ | ٮ | ٯ |
| 0670 | ٰ | ٱ | ٲ | ٳ | ٴ | ٵ | ٶ | ٷ | ٸ | ٹ | ٺ | ٻ | ټ | ٽ | پ | ٿ |
| 0680 | ڀ | ځ | ڂ | ڃ | ڄ | څ | چ | ڇ | ڈ | ډ | ڊ | ڋ | ڌ | ڍ | ڎ | ڏ |
| 0690 | ڐ | ڑ | ڒ | ړ | ڔ | ڕ | ږ | ڗ | ژ | ڙ | ښ | ڛ | ڜ | ڝ | ڞ | ڟ |
| 6A0 | ڠ | ڡ | ڢ | ڣ | ڤ | ڥ | ڦ | ڧ | ڨ | ک | ڪ | ګ | ڬ | ڭ | ڮ | گ |
| 06B0 | ڰ | ڱ | ڲ | ڳ | ڴ | ڵ | ڶ | ڷ | ڸ | ڹ | ں | ڻ | ڼ | ڽ | ھ | ڿ |
| 06C0 | ۀ | ہ | ۂ | ۃ | ۄ | ۅ | ۆ | ۇ | ۈ | ۉ | ۊ | ۋ | ی | ۍ | ێ | ۏ |
| 06D0 | ې | ۑ | ے | ۓ | ۔ | ە | ۖ | ۗ | ۘ | ۙ | ۚ | ۛ | ۜ | | ۞ | ۟ |
| 06E0 | ۠ | ۡ | ۢ | ۣ | ۤ | ۥ | ۦ | ۧ | ۨ | ۩ | ۪ | ۫ | ۬ | ۭ | ۮ | ۯ |
| 06F0 | ۰ | ۱ | ۲ | ۳ | ۴ | ۵ | ۶ | ۷ | ۸ | ۹ | ۺ | ۻ | ۼ | ۽ | ۾ | ۿ |
最近在用VC++开发一个小工具,平时用惯了.NET,用起VC++最郁闷的就是字符串处理。当然最最让人难于琢磨的就是字符集,编码之间的转换。通过这几天的研究,终于明白了Unicode和UTF-8之间编码的区别。Unicode是一个字符集,而UTF-8是Unicode的其中一种,Unicode是定长的都为双字节,而UTF-8是可变的,对于汉字来说Unicode占有的字节比UTF-8占用的字节少1个字节。Unicode为双字节,而UTF-8中汉字占三个字节。
UTF-8编码字符理论上可以最多到6个字节长,然而16位BMP(BasicMultilingual Plane)字符最多只用到3字节长。下面看一下UTF-8编码表:
U-00000000 - U-0000007F: 0xxxxxxx
U-00000080 - U-000007FF: 110xxxxx10xxxxxx
U-00000800 - U-0000FFFF: 1110xxxx10xxxxxx 10xxxxxx
U-00010000 - U-001FFFFF: 11110xxx10xxxxxx 10xxxxxx 10xxxxxx
U-00200000 - U-03FFFFFF: 111110xx10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
U-04000000 - U-7FFFFFFF: 1111110x10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
xxx 的位置由字符编码数的二进制表示的位填入,越靠右的 x 具有越少的特殊意义,只用最短的那个足够表达一个字符编码数的多字节串。 注意在多字节串中, 第一个字节的开头"1"的数目就是整个串中字节的数目。而第一行中以0开头,是为了兼容ASCII编码,为一个字节,第二行就为双字节字符串,第三行为3字节,如汉字就属于这种,以此类推。(个人认为:其实我们可以简单的把前面的1的个数看成字节数)
为了要将Unicode转换为UTF-8,当然要知道他们的区别到底在什么地方。下面来看一下,在Unicode中的编码是怎样转换成UTF-8的,在UTF-8中,如果一个字符的字节小于0x80(128)则为ASCII字符,占一个字节,可以不用转换,因为UTF-8兼容ASCII编码。假如在Unicode中汉字“你”的编码为“u4F60”,把它转换为二进制为100111101100000,然后按照UTF-8的方法进行转换。可以将Unicode二进制从地位往高位取出二进制数字,每次取6位,如上述的二进制就可以分别取出为如下所示的格式,前面按格式填补,不足8位用0填补。
unicode: 100111101100000 4F60
utf-8: 11100100,10111101,10100000 E4BDA0
从上面就可以很直观的看出Unicode到UTF-8之间的转换,当然知道了UTF-8的格式后,就可以进行逆运算,就是按照格式把它在二进制中的相应位置上取出,然后在转换就是所得到的Unicode字符了(这个运算可以通过“位移”来完成)。
如上述的“你”的转换,由于其值大于0x800小于0x10000,因此可以判断为三字节存储,则最高位需要向右移“12”位再根据三字节格式的最高位为11100000(0xE0)求或(|)就可以得到最高位的值了。同理第二位则是右移“6”位,则还剩下最高位和第二位的二进制值,可以通过与111111(0x3F)求按位于(&)操作,再和11000000(0x80)求或(|)。第三位就不用移位了,只要直接取最后六位(与111111(ox3F)取&),在与11000000(0x80)求或(|)。OK了,转换成功!在VC++中的代码如下所示(Unicode到UTF-8的转换)。
1 const wchar_t pUnicode = L"你";
2 char utf8[3+1];
3 memset(utf8,0,4);
4 utf8[0] = 0xE0|(pUnicode>>12);
5 utf8[1] = 0x80|((pUnicode>>6)&0x3F);
6 utf8[2] = 0x80|(pUnicode&0x3F);
7 utf8[3] = "\0";
8 //char[4]就是UTF-8的字符“你”了。
当然在UTF-8到Unicode的转换也是通过移位等来完成的,就是把UTF-8那些格式相应的位置的二进制数给揪出来。在上述例子中“你”为三个字节,因此要每个字节进行处理,有高位到低位进行处理。在UTF-8中“你”为11100100,10111101,10100000。从高位起即第一个字节11100100就是把其中的"0100"给取出来,这个很简单只要和11111(0x1F)取与(&),由三字节可以得知最到位肯定位于12位之前,因为每次取六位。所以还要将得到的结果左移12位,最高位也就这样完成了0100,000000,000000。而第二位则是要把“111101”给取出来,则只需将第二字节10111101和111111(0x3F)取与(&)。在将所得到的结果左移6位与最高字节所得的结果取或(|),第二位就这样完成了,得到的结果为0100,111101,000000。以此类推最后一位直接与111111(0x3F)取与(&),再与前面所得的结果取或(|)即可得到结果0100,111101,100000。OK,转换成功!在VC++中的代码如下所示(UTF-8到Unicode的转换)。
1 //UTF-8格式的字符串
2 const char* utf8 = "你";
3 wchar_t unicode;
4 unicode = (utf8[0] & 0x1F) << 12;
5 unicode |= (utf8[1] & 0x3F) << 6;
6 unicode |= (utf8[2] & 0x3F);
7 //unicode is ok!
当然在编程过程中不可能只转换一个字符,这里需要注意的是字符的长度一定要算清楚,不然会带来...以上就是我这几天研究的结果,至于Unicode的转换为GB2312在MFC中Windows有自带的API(WideCharToMultiByte)可以转换。这样也就能够将UTF-8格式转换为GB2312了。
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8_ | Ä 00C4 | 00A0 | Ç 00C7 | É 00C9 | Ñ 00D1 | Ö 00D6 | Ü 00DC | á 00E1 | à 00E0 | â 00E2 | ä 00E4 | ں 06BA | « 00AB | ç 00E7 | é 00E9 | è 00E8 |
| 9_ | ê 00EA | ë 00EB | í 00ED | … 2026 | î 00EE | ï 00EF | ñ 00F1 | ó 00F3 | » 00BB | ô 00F4 | ö 00F6 | ÷ 00F7 | ú 00FA | ù 00F9 | û 00FB | ü 00FC |
| A_ | 0020 | ! 0021 | " 0022 | # 0023 | $ 0024 | ٪ 066A | & 0026 | ' 0027 | ( 0028 | ) 0029 | * 002A | + 002B | ، 060C | - 002D | . 002E | / 002F |
| B_ | ٠ 0660 | ١ 0661 | ٢ 0662 | ٣ 0663 | ٤ 0664 | ٥ 0665 | ٦ 0666 | ٧ 0667 | ٨ 0668 | ٩ 0669 | : 003A | ؛ 061B | < 003C | = 003D | > 003E | ؟ 061F |
| C_ | ❊ 274A | ء 0621 | آ 0622 | أ 0623 | ؤ 0624 | إ 0625 | ئ 0626 | ا 0627 | ب 0628 | ة 0629 | ت 062A | ث 062B | ج 062C | ح 062D | خ 062E | د 062F |
| D_ | ذ 0630 | ر 0631 | ز 0632 | س 0633 | ش 0634 | ص 0635 | ض 0636 | ط 0637 | ظ 0638 | ع 0639 | غ 063A | [ 005B | \ 005C | ] 005D | ^ 005E | _ 005F |
| E_ | ـ 0640 | ف 0641 | ق 0642 | ك 0643 | ل 0644 | م 0645 | ن 0646 | ه 0647 | و 0648 | ى 0649 | ي 064A | ً 064B | ٌ 064C | ٍ 064D | َ 064E | ُ 064F |
| F_ | ِ 0650 | ّ 0651 | ْ 0652 | پ 067E | ٹ 0679 | ڈ 0688 | ە 06D5 | ڤ 06A4 | گ 06AF | ڈ 0688 | ڑ 0691 | { 007B | | 007C | } 007D | ژ 0698 | ے 06D2 |
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8_ | Ä 00C4 | 00A0 | Ç 00C7 | É 00C9 | Ñ 00D1 | Ö 00D6 | Ü 00DC | á 00E1 | à 00E0 | â 00E2 | ä 00E4 | ں 06BA | « 00AB | ç 00E7 | é 00E9 | è 00E8 |
| 9_ | ê 00EA | ë 00EB | í 00ED | … 2026 | î 00EE | ï 00EF | ñ 00F1 | ó 00F3 | » 00BB | ô 00F4 | ö 00F6 | ÷ 00F7 | ú 00FA | ù 00F9 | û 00FB | ü 00FC |
| A_ | 0020 | ! 0021 | " 0022 | # 0023 | $ 0024 | ٪ 066A | & 0026 | ' 0027 | ( 0028 | ) 0029 | * 002A | + 002B | ، 060C | - 002D | . 002E | / 002F |
| B_ | ٠ 0660 | ١ 0661 | ٢ 0662 | ٣ 0663 | ٤ 0664 | ٥ 0665 | ٦ 0666 | ٧ 0667 | ٨ 0668 | ٩ 0669 | : 003A | ؛ 061B | < 003C | = 003D | > 003E | ؟ 061F |
| C_ | ❊ 274A | ء 0621 | آ 0622 | أ 0623 | ؤ 0624 | إ 0625 | ئ 0626 | ا 0627 | ب 0628 | ة 0629 | ت 062A | ث 062B | ج 062C | ح 062D | خ 062E | د 062F |
| D_ | ذ 0630 | ر 0631 | ز 0632 | س 0633 | ش 0634 | ص 0635 | ض 0636 | ط 0637 | ظ 0638 | ع 0639 | غ 063A | [ 005B | \ 005C | ] 005D | ^ 005E | _ 005F |
| E_ | ـ 0640 | ف 0641 | ق 0642 | ك 0643 | ل 0644 | م 0645 | ن 0646 | ه 0647 | و 0648 | ى 0649 | ي 064A | ً 064B | ٌ 064C | ٍ 064D | َ 064E | ُ 064F |
| F_ | ِ 0650 | ّ 0651 | ْ 0652 | پ 067E | ٹ 0679 | ڈ 0688 | ە 06D5 | ڤ 06A4 | گ 06AF | ڈ 0688 | ڑ 0691 | { 007B | | 007C | } 007D | ژ 0698 | ے 06D2 |
http://zh.wikipedia.org/wiki/ISO/IEC_8859-6
阿拉伯cp1256 http://code.web.idv.hk/charset/cp1256.php
阿拉伯8859-6 http://code.web.idv.hk/charset/iso-8859-6.php
ISO/IEC 8859-6[编辑]
ISO 8859-6,正式编号为ISO/IEC 8859-6:1999或Arabic,是国际标准化组织内ISO/IEC 8859的其中一个8位字符集,供现代阿拉伯语使用。它等同于阿拉伯标准ASMO-708。但因很多于阿拉伯语使用的字母都未能支援,故近来已逐步被Unicode取代。曾推出过 ISO 8859-6:1987 版。
| ISO/IEC 8859-6 | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x0 | x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x9 | xA | xB | xC | xD | xE | xF | |
| 0x | ||||||||||||||||
| 1x | ||||||||||||||||
| 2x | SP | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / |
| 3x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4x | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5x | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6x | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7x | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | |
| 8x | ||||||||||||||||
| 9x | ||||||||||||||||
| Ax | NBSP | ¤ | ، | SHY | ||||||||||||
| Bx | ؛ | ؟ | ||||||||||||||
| Cx | ء | آ | أ | ؤ | إ | ئ | ا | ب | ة | ت | ث | ج | ح | خ | د | |
| Dx | ذ | ر | ز | س | ش | ص | ض | ط | ظ | ع | غ | |||||
| Ex | ـ | ف | ق | ك | ل | م | ن | ه | و | ى | ي | ً | ٌ | ٍ | َ | ُ |
| Fx | ِ | ّ | ْ | |||||||||||||
在上表中,0x20是空格、0xA0是不换行空格、0xAD是选择性连接号。
0x00-0x1F、0x7F、0x80-0x9F、0xA1-0xA3、0xA5-0xAB、0xB0-0xBA、0xBC-0xBE、0xC0、0xDC-0xDF、0xF3-0xFF在此字符集中未有定义。
0xEB-0xF2是组合符号(combining character)(即把此符号加在前一个字母之上)。
CP1256 (微軟阿拉伯語視窗) 編碼表
| −0 | −1 | −2 | −3 | −4 | −5 | −6 | −7 | −8 | −9 | −A | −B | −C | −D | −E | −F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0− | NUL 0000 0 | SOH 0001 1 | STX 0002 2 | ETX 0003 3 | EOT 0004 4 | ENQ 0005 5 | ACK 0006 6 | BEL 0007 7 | BS 0008 8 | HT 0009 9 | LF 000A 10 | VT 000B 11 | FF 000C 12 | CR 000D 13 | SO 000E 14 | SI 000F 15 |
| 1− | DLE 0010 16 | DC1 0011 17 | DC2 0012 18 | DC3 0013 19 | DC4 0014 20 | NAK 0015 21 | SYN 0016 22 | ETB 0017 23 | CAN 0018 24 | EM 0019 25 | SUB 001A 26 | ESC 001B 27 | FS 001C 28 | GS 001D 29 | RS 001E 30 | US 001F 31 |
| 2− | SP 0020 32 | ! 0021 33 | " 0022 34 | # 0023 35 | $ 0024 36 | % 0025 37 | & 0026 38 | ' 0027 39 | ( 0028 40 | ) 0029 41 | * 002A 42 | + 002B 43 | , 002C 44 | - 002D 45 | . 002E 46 | / 002F 47 |
| 3− | 0 0030 48 | 1 0031 49 | 2 0032 50 | 3 0033 51 | 4 0034 52 | 5 0035 53 | 6 0036 54 | 7 0037 55 | 8 0038 56 | 9 0039 57 | : 003A 58 | ; 003B 59 | < 003C 60 | = 003D 61 | > 003E 62 | ? 003F 63 |
| 4− | @ 0040 64 | A 0041 65 | B 0042 66 | C 0043 67 | D 0044 68 | E 0045 69 | F 0046 70 | G 0047 71 | H 0048 72 | I 0049 73 | J 004A 74 | K 004B 75 | L 004C 76 | M 004D 77 | N 004E 78 | O 004F 79 |
| 5− | P 0050 80 | Q 0051 81 | R 0052 82 | S 0053 83 | T 0054 84 | U 0055 85 | V 0056 86 | W 0057 87 | X 0058 88 | Y 0059 89 | Z 005A 90 | [ 005B 91 | \ 005C 92 | ] 005D 93 | ^ 005E 94 | _ 005F 95 |
| 6− | ` 0060 96 | a 0061 97 | b 0062 98 | c 0063 99 | d 0064 100 | e 0065 101 | f 0066 102 | g 0067 103 | h 0068 104 | i 0069 105 | j 006A 106 | k 006B 107 | l 006C 108 | m 006D 109 | n 006E 110 | o 006F 111 |
| 7− | p 0070 112 | q 0071 113 | r 0072 114 | s 0073 115 | t 0074 116 | u 0075 117 | v 0076 118 | w 0077 119 | x 0078 120 | y 0079 121 | z 007A 122 | { 007B 123 | | 007C 124 | } 007D 125 | ~ 007E 126 | DEL 007F 127 |
| 8− | € 20AC 128 | پ 067E 129 | ‚ 201A 130 | ƒ 0192 131 | „ 201E 132 | … 2026 133 | † 2020 134 | ‡ 2021 135 | ˆ 02C6 136 | ‰ 2030 137 | ٹ 0679 138 | ‹ 2039 139 | Œ 0152 140 | چ 0686 141 | ژ 0698 142 | ڈ 0688 143 |
| 9− | گ 06AF 144 | ‘ 2018 145 | ’ 2019 146 | “ 201C 147 | ” 201D 148 | • 2022 149 | – 2013 150 | — 2014 151 | ک 06A9 152 | ™ 2122 153 | ڑ 0691 154 | › 203A 155 | œ 0153 156 | ZWNJ 200C 157 | ZWJ 200D 158 | ں 06BA 159 |
| A− | NBSP 00A0 160 | ، 060C 161 | ¢ 00A2 162 | £ 00A3 163 | ¤ 00A4 164 | ¥ 00A5 165 | ¦ 00A6 166 | § 00A7 167 | ¨ 00A8 168 | © 00A9 169 | ھ 06BE 170 | « 00AB 171 | ¬ 00AC 172 | SHY 00AD 173 | ® 00AE 174 | ¯ 00AF 175 |
| B− | ° 00B0 176 | ± 00B1 177 | ² 00B2 178 | ³ 00B3 179 | ´ 00B4 180 | µ 00B5 181 | ¶ 00B6 182 | · 00B7 183 | ¸ 00B8 184 | ¹ 00B9 185 | ؛ 061B 186 | » 00BB 187 | ¼ 00BC 188 | ½ 00BD 189 | ¾ 00BE 190 | ؟ 061F 191 |
| C− | ہ 06C1 192 | ء 0621 193 | آ 0622 194 | أ 0623 195 | ؤ 0624 196 | إ 0625 197 | ئ 0626 198 | ا 0627 199 | ب 0628 200 | ة 0629 201 | ت 062A 202 | ث 062B 203 | ج 062C 204 | ح 062D 205 | خ 062E 206 | د 062F 207 |
| D− | ذ 0630 208 | ر 0631 209 | ز 0632 210 | س 0633 211 | ش 0634 212 | ص 0635 213 | ض 0636 214 | × 00D7 215 | ط 0637 216 | ظ 0638 217 | ع 0639 218 | غ 063A 219 | ـ 0640 220 | ف 0641 221 | ق 0642 222 | ك 0643 223 |
| E− | à 00E0 224 | ل 0644 225 | â 00E2 226 | م 0645 227 | ن 0646 228 | ه 0647 229 | و 0648 230 | ç 00E7 231 | è 00E8 232 | é 00E9 233 | ê 00EA 234 | ë 00EB 235 | ى 0649 236 | ي 064A 237 | î 00EE 238 | ï 00EF 239 |
| F− | ً 064B 240 | ٌ 064C 241 | ٍ 064D 242 | َ 064E 243 | ô 00F4 244 | ُ 064F 245 | ِ 0650 246 | ÷ 00F7 247 | ّ 0651 248 | ù 00F9 249 | ْ 0652 250 | û 00FB 251 | ü 00FC 252 | LRM 200E 253 | RLM 200F 254 | ے 06D2 255 |
ISO/IEC 8859-6:1999 (iso-ir-127) 編碼表
| −0 | −1 | −2 | −3 | −4 | −5 | −6 | −7 | −8 | −9 | −A | −B | −C | −D | −E | −F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8− | 128 | 129 | 130 | 131 | 132 | 133 | 134 | 135 | 136 | 137 | 138 | 139 | 140 | 141 | 142 | 143 |
| 9− | 144 | 145 | 146 | 147 | 148 | 149 | 150 | 151 | 152 | 153 | 154 | 155 | 156 | 157 | 158 | 159 |
| A− | NBSP 00A0 160 | 161 | 162 | 163 | ¤ 00A4 164 | 165 | 166 | 167 | 168 | 169 | 170 | 171 | ، 060C 172 | SHY 00AD 173 | 174 | 175 |
| B− | 176 | 177 | 178 | 179 | 180 | 181 | 182 | 183 | 184 | 185 | 186 | ؛ 061B 187 | 188 | 189 | 190 | ؟ 061F 191 |
| C− | 192 | ء 0621 193 | آ 0622 194 | أ 0623 195 | ؤ 0624 196 | إ 0625 197 | ئ 0626 198 | ا 0627 199 | ب 0628 200 | ة 0629 201 | ت 062A 202 | ث 062B 203 | ج 062C 204 | ح 062D 205 | خ 062E 206 | د 062F 207 |
| D− | ذ 0630 208 | ر 0631 209 | ز 0632 210 | س 0633 211 | ش 0634 212 | ص 0635 213 | ض 0636 214 | ط 0637 215 | ظ 0638 216 | ع 0639 217 | غ 063A 218 | 219 | 220 | 221 | 222 | 223 |
| E− | ـ 0640 224 | ف 0641 225 | ق 0642 226 | ك 0643 227 | ل 0644 228 | م 0645 229 | ن 0646 230 | ه 0647 231 | و 0648 232 | ى 0649 233 | ي 064A 234 | ً 064B 235 | ٌ 064C 236 | ٍ 064D 237 | َ 064E 238 | ُ 064F 239 |
| F− | ِ 0650 240 | ّ 0651 241 | ْ 0652 242 | 243 | 244 | 245 | 246 | 247 | 248 | 249 | 250 | 251 | 252 | 253 | 254 | 255 |

















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









