







一 为什么加锁
在SMP系统中,如果仅仅是需要串行地增加一个变量的值,那么使用原子操作的函数(API)就可以了。但现实中更多的场景并不会那么简单,比如需要将一个结构体A中的数据提取出来,然后格式化、解析,再添加到另一个结构体B中,这整个的过程都要求是「原子的」,也就是完成之前,不允许其他的代码来读/写这两个结构体中的任何一个。
这时,相对轻量级的原子操作API就无法满足这种应用场景的需求了,我们需要一种更强的同步/互斥机制,那就是软件层面的「锁」的机制。
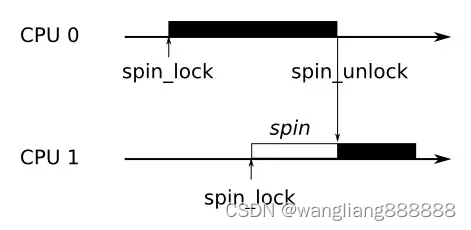
同步锁的「加锁」和「解锁」是放在一段代码的一前一后,成对出现的,这段代码被称为Critical Section/Region(临界区)。但锁保护的并不是这段代码本身,而是其中使用到的多核/多线程共享的变量,它「同步」(或者说串行化)的是对这个变量的访问,通俗的语义就是“我有你就不能有,你有我就不会有”。
Linux中主要有两种同步锁,一种是spinlock,一种是mutex。spinlock和mutex都既可以在用户进程中使用,也可以在内核中使用,它们的主要区别是前者不会导致睡眠和调度,属于busy wait形式的锁,而后者可能导致睡眠和调度,属于sleep wait形式的锁。
spinlock是最基础的一种锁,像后面将要介绍的rwlock(读写锁),seqlock(读写锁)等都是基于spinlock衍生出来的。就算是mutex,它的实现与spinlock也是密不可分。因此,本系列文章将首先围绕spinlock展开介绍。
二 如何加锁
Linux中spinlock机制发展到现在,其实现方式的大致有3种。
第一种实现 - 经典的CAS
最古老的一种做法是:spinlock用一个整形变量表示,其初始值为1,表示available的状态。当一个CPU(设为CPU A)获得spinlock后,会将该变量的值设为0,之后其他CPU试图获取这个spinlock时,会一直等待,直到CPU A释放spinlock,并将该变量的值设为1。
那么其他的CPU是以何种形式等待的,如果有多个CPU一起等待,形成了竞争又该如何处理?这里要用到经典的CAS操作(Compare And Swap)。
谁和谁比较
目前,sh架构的Linux实现中还保留有这种经典的实现方法(相关代码位于/arch/sh/include/asm/spinlock-cas.h)。
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
**while (!__sl_cas(&lock->lock, 1, 0));**
}
static inline unsigned __sl_cas(volatile unsigned *p, unsigned old, unsigned new)
{
__asm__ __volatile__("cas.l %1,%0,@r0"
: "+r"(new)
: "r"(old), "z"(p)
: "t", "memory" );
return new;
}
其中,"p"指向spinlock变量所在的内存位置,存储的是当前spinlock实际的值,"old"存储的试图获取spinlock的本地CPU希望的值(1)。
不断地把「期望的值」和「实际的值」进行比较(compare),当它们相等时,说明持有spinlock的CPU已经释放了锁,那么试图获取spinlock的CPU就会尝试将"new"的值(0)写入"p"(swap),以表明自己成为spinlock新的owner。
汇编代码看起来可能略费力一些,用一段伪代码来展示或许会更加地直观:
function cas(p, old, new)
{
if *p ≠ old
do nothing
else
*p ← new
}
这里只用了0和1两个值来表示spinlock的状态,没有充分利用spinlock作为整形变量的属性,为此还有一种衍生的方法,可以判断当前spinlock的争用情况。具体规则是:每个CPU在试图获取一个spinlock时,都会将这个spinlock的值减1,所以这个值可以是负数,而「负」的越多(负数的绝对值越大),说明当前的争抢越激烈。
存在的问题
基于CAS的实现速度很快,尤其是在没有真正竞态的情况下(事实上大部分时候就是这种情况),但这种方法存在一个缺点:它是「不公平」的。 一旦spinlock被释放,第一个能够成功执行CAS操作的CPU将成为新的owner,没有办法确保在该spinlock上等待时间最长的那个CPU优先获得锁,这将带来延迟不能确定的问题。
第二种实现 - Ticket Spinlock
为了解决这种「无序竞争」带来的不公平问题,spinlock的另一种实现方法是采用排队形式的"ticket spinlock"。这里,我想展示ticket spinlock的两个实现版本,它们的原理都是一样的,只是具体细节略有差异。
ACRN版本
先来看下基于x86-64的ACRN hypervisor对于ticket spinlock的实现:
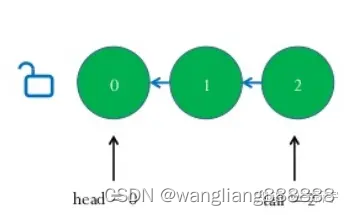
表示一个spinlock的数据结构由"head"和"tail"两个队列的索引组成。
typedef struct _spinlock {
uint32_t head;
uint32_t tail;
} spinlock_t;
"head"指向当前队列的头部,"tail"指向当前队列的尾部,其初始值都为0。
解锁
一个spinlock被owner释放时,该spinlock的head值会被owner通过"inc"指令加1。
static inline void spinlock_release(spinlock_t *lock)
{
asm volatile (" lock incl %[head]\n" // head加1
:
: [head] "m" (lock->head)
: "cc", "memory");
}
加锁
其他CPU在试图获取这个spinlock时,会通过"xadd"指令将"tail"值保存在自己的eax寄存器中,然后将该spinlock的"tail"值加1(也就是将自己加到了这个等待队列的尾部,如果head==tail(eax)说明可以获取spinlock)。
static inline void spinlock_obtain(spinlock_t *lock)
{
asm volatile (" movl $0x1,%%eax\n" // eax = 1
" lock xaddl %%eax,%[tail]\n" // eax = old tail, new tail = old tail + 1
" cmpl %%eax,%[head]\n" // 比较eax(old tail)和head
" jz 1f\n" // 相等,获得锁
"2: pause\n" // 不相等,继续比较
" cmpl %%eax,%[head]\n"
" jnz 2b\n"
"1:\n"
:
:
[head] "m"(lock->head),
[tail] "m"(lock->tail)
: "cc", "memory", "eax");
}
接下来就是不断的循环比较,判断该spinlock当前的"head"值,是否和自己存储在eax寄存器中的"tail"值相等,相等时则获得该spinlock,成为新的owner。
这类似于你去银行柜台办理业务,假设当前银行只有一个柜台,你需要在自助机上获得一个排队号码(相当于一个ticket),然后当柜台叫到的号码与你手中的号码一致时,你将坐上柜台前面的椅子,此时柜台为你服务,这也是这种实现方式被称为"ticket spinlock"的原因。
在ticket spinlock中,"compare"和"swap"的操作就分离了。把spinlock当前的值和旧的值进行比较(compare),还是由每个试图获得spinlock的CPU来执行的,但设置新的值(swap),则是由上一个持有spinlock的CPU来完成的。
Linux版本
再来看下基于ARMv6的Linux中,ticket spinlock的实现(相关代码位于/arch/arm/include/asm/spinlock.h):
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{
lock->tickets.owner++;
}
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
[LL/SC]
while (lockval.tickets.next != lockval.tickets.owner) {
wfe();
lockval.tickets.owner = READ_ONCE(lock->tickets.owner);
}
}
“owner"和"next"分别对应ACRN版本中的"head"和"tail”。"wfe"是ARM中的"wait for event"指令,和x86中的pause指令类似,目的是为了降低busy wait时的CPU功耗。
看起来比ACRN的实现简洁?没有,LL/SC这部分也是一段汇编代码,它完成的是和x86的"add"指令一样的工作,和前文讲述的LL/SC是一样的。
__asm__ __volatile__(
"1: ldrex %0, [%3]\n" // lockval = lock->slock
" add %1, %0, %4\n" // newval = lockval + (1 << TICKET_SHIFT)
" strex %2, %1, [%3]\n" // try lock->slock = newval
" teq %2, #0\n" // test result = 0 ?
" bne 1b" // not equal, do LL/SC again
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp)
: "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
: "cc");
这里之所以是"1<<TICKET_SHIFT"而不是1,是因为它没有把一个32位的变量全部用来表示spinlock的队列索引,而只是其中的一些bits,事实上也不可能有那么多的CPU同时等待一个spinlock。
公平与效率
**可见,使用ticket spinlock可以让CPU按照到达的先后顺序,去获取spinlock的所有权,形成了「有序竞争」。**根据硬件维护的cache一致性协议,如果spinlock的值没有更改,那么在busy wait时,试图获取spinlock的CPU,只需要不断地读取自己包含这个spinlock变量的cache line上的值就可以了,不需要从spinlock变量所在的内存位置读取。
但是,当spinlock的值被更改时,所有试图获取spinlock的CPU对应的cache line都会被invalidate,因为这些CPU会不停地读取这个spinlock的值,所以"invalidate"状态意味着此时,它们必须重新从内存读取新的spinlock的值到自己的cache line中。
而事实上,其中只会有一个CPU,也就是队列中最先达到的那个CPU,接下来可以获得spinlock,也只有它的cache line被invalidate才是有意义的,对于其他的CPU来说,这就是做无用功。内存比cache慢那么多,开销可不小。
还是用银行叫号来类比,假设现在2号客户的业务办理完了,接下来就该在大厅里叫3号,然后3号客户去办理,但是所有排号的,4号、5号……哪怕是20号,也得听一下叫的号,对于20号来说,它完全可以在叫到19号之前打个盹嘛。
本文转自:https://zhuanlan.zhihu.com/p/80727111














 2916
2916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









