









Linux内核源码中最常见的数据结构之【Spinlock】
1 定义
在软件工程中,自旋锁是一种锁,它使试图获取它的线程在循环中原地等待(“自旋”),同时反复检查锁是否可用。
由于线程保持活动状态但没有执行有用的任务,因此使用这种锁是一种忙等待。一旦获得,自旋锁通常会一直保持直到它们被显式释放,尽管在某些实现中,如果正在等待的线程(持有锁的线程)阻塞或“进入睡眠状态”,它们可能会自动释放。
为什么Linux内核经常使用自旋锁?
因为它们避免了操作系统进程重新调度或上下文切换的开销,所以如果线程可能只在短时间内被阻塞,自旋锁是有效的。出于这个原因,操作系统内核经常使用自旋锁。
自旋锁有什么弊端?
如果长时间持有自旋锁,则会变得浪费,因为它们可能会阻止其他线程运行并需要重新调度。线程持有锁的时间越长,线程在持有锁时被操作系统调度程序中断的风险就越大。如果发生这种情况,其他线程将处于“旋转”状态(反复尝试获取锁)。结果是无限期推迟,直到持有锁的线程可以完成并释放它。
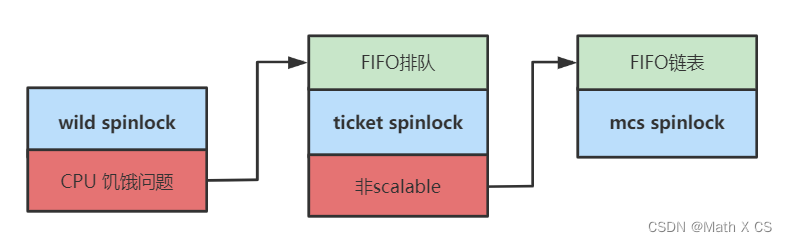
2 发展
wild spinlock
wild spinlock是早期的自旋锁实现,实现也非常简单
struct spinlock {
volatile unsigned int lock;
};
//上锁
void spin_lock(struct spinlock *lock)
{
while (lock->lock);
lock->lock = 1;
//可以优化为==>while (lock->locked || test_and_set(&lock->locked));
}
//释放锁
void spin_unlock(struct spinlock *lock)
{
lock->lock = 0;
}

但是考虑到多个CPU核心由于架构原因,如上图所示,cache无法在同一时间更新,现在CPU1释放锁,CPU2-CPUN哪个CPU的cache先更新就能获得锁。所以不排队的机制可能导致部分CPU饿死,始终拿不到锁。为了解决这个问题,自旋锁从wild spinlock跨度到ticket spinlock。
ticket spinlock
引入排队机制,以FIFO的顺序处理申请者,谁先申请,谁先获得,保证公平性。
struct spinlock {
// 当前持有者票号
int owner;
// 票号
int next;
};
//上锁
void spin_lock(struct spinlock *lock)
{
unsigned short next = xadd(&lock->next, 1);
while (lock->owner != next);
}
//释放锁
void spin_unlock(struct spinlock *lock)
{
lock->owner++;
}
spin_lock()中xadd()也是一条原子操作,原子的将变量加1,并返回变量之前的值。当owner等于next时,代表锁是释放状态,否则,说明锁是持有状态。next就像是排队拿票机制,每来一个申请者,next就加1,代表票号,owner代表当前持锁的票号。
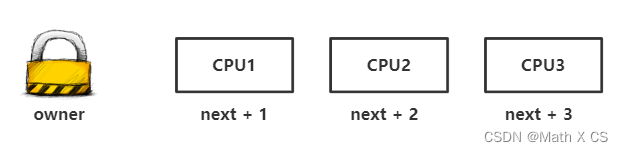
ticket spinlock也存在问题
随着CPU数量的增多,总线带宽压力很大。而且延迟也会随着增长,性能也会逐渐下降。而且CPU0释放锁后,CPU1-CPU7也只有一个CPU可以获得锁,理论上没有必要影响其他CPU的缓存,只需要影响接下来应该获取锁的CPU(按照FIFO的顺序)。这说明ticket spinlock不是scalable(同样最初的wild spinlock也存在此问题)。
为了解决这个问题,自旋锁从ticket spinlock跨度到mcs pinlock。
mcs spinlock
先来思考下造成该问题的原因。根因就是每个CPU都spin在共享变量spinlock上。所以我们只需要保证每个CPU spin的变量是不同的就可以避免这种情况了。
MCS 锁(由 Mellor-Crummey 和 Scott 提出)是一个简单的自旋锁,具有公平的理想属性,并且每个 cpu 都试图获取在本地变量上旋转的锁。 它避免了常见的test-and-set自旋锁实现引起的昂贵的cacheline bouncing。
同时我们需要换一种排队的方式,例如单链表。单链表也可以做到FIFO,每次解锁时,也只需要通知链表头的CPU即可。
struct mcs_spinlock {
struct mcs_spinlock *next;
int locked;
};
// 自己的排队节点node需要自己在外部初始化,它将被排队到lock指示的等锁队列中。
void mcs_spin_lock(struct mcs_spinlock **lock, struct mcs_spinlock *node)
{
struct mcs_spinlock *prev;
/* Init node */
node->locked = 0;
node->next = NULL;
// 原子执行*lock = node并返回原来的*lock
prev = xchg(lock, node);
if (likely(prev == NULL)) {
return;
}
// 原子执行 prev->next = node;
// 这相当于一个排入队的操作。记作(*)
WRITE_ONCE(prev->next, node);
/* 自旋,直到锁的持有者放弃锁 */
arch_mcs_spin_lock_contended(&node->locked);
}
// 自己要传入一个排入到lock的队列中的自己的node对象node,解锁操作就是node出队并且主动将队列中下一个对象的locked帮忙设置成1.
void mcs_spin_unlock(struct mcs_spinlock **lock, struct mcs_spinlock *node)
{
// 原子获取node的下一个节点。
struct mcs_spinlock *next = READ_ONCE(node->next);
if (likely(!next)) {
// 二次确认真的是NULL,则返回,说明自己是最后一个,什么都不需要做。
if (likely(cmpxchg_release(lock, node, NULL) == node))
return;
// 否则说明在if判断next为MULL和cmpxchg原子操作之间有node插入,随即等待它的mcs_spin_lock调用完成,即上面mcs_spin_lock中的(*)注释那句完成以后
while (!(next = READ_ONCE(node->next)))
cpu_relax_lowlatency();
}
// 原子执行next->locked = 1;
/*将锁传递给下一个等待者*/
arch_mcs_spin_unlock_contended(&next->locked);
}
通过以上步骤,我们可以看到每个CPU都spin在自己的使用变量上面,因此不会存在ticket spinlock的问题。
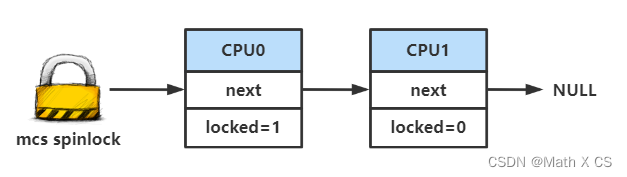
overview
3 实现
在Linux内核源码中的具体实现如下:
位于:include/linux/spinlock_types.h,通用的spinlock类型定义以及初始化
typedef struct spinlock {
union {
struct raw_spinlock rlock;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
# define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map))
struct {
u8 __padding[LOCK_PADSIZE];
struct lockdep_map dep_map;
};
#endif
};
} spinlock_t;
typedef struct raw_spinlock {
arch_spinlock_t raw_lock;
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} raw_spinlock_t;
可以看到,spinlock_t的实现主要靠raw_spinlock_t,而raw_spinlock_t又调用了与CPU架构相关的arch_spinlock_t
如果你使用的是alpha架构
typedef struct {
volatile unsigned int lock;
} arch_spinlock_t;
如果你使用的是arm架构
typedef struct {
union {
u32 slock;
struct __raw_tickets {
#ifdef __ARMEB__
u16 next;
u16 owner;
#else
u16 owner;
u16 next;
#endif
} tickets;
};
} arch_spinlock_t;
由于不同CPU架构spinlock的具体实现不同,下文主要依据ARMv6架构的实现源码
Linux内核提供了多个个宏用于初始化、测试及设置自旋锁。所有这些宏都是基于原子操作的,这样可以保证即使有多个运行在不同CPU上的进程试图同时修改自旋锁,自旋锁也能够被正确地更新。
- 初始化自旋锁
# define spin_lock_init(lock) \
do { \
static struct lock_class_key __key; \
\
__raw_spin_lock_init(spinlock_check(lock), \
#lock, &__key, LD_WAIT_CONFIG); \
} while (0)
void __raw_spin_lock_init(raw_spinlock_t *lock, const char *name,
struct lock_class_key *key, short inner)
{
#ifdef CONFIG_DEBUG_LOCK_ALLOC
/*
* Make sure we are not reinitializing a held lock:
*/
debug_check_no_locks_freed((void *)lock, sizeof(*lock));
lockdep_init_map_wait(&lock->dep_map, name, key, 0, inner);
#endif
lock->raw_lock = (arch_spinlock_t)__ARCH_SPIN_LOCK_UNLOCKED;
lock->magic = SPINLOCK_MAGIC;
lock->owner = SPINLOCK_OWNER_INIT;
lock->owner_cpu = -1;
}
#define SPINLOCK_MAGIC 0xdead4ead
#define SPINLOCK_OWNER_INIT ((void *)-1L)
#define __ARCH_SPIN_LOCK_UNLOCKED { 0 }
static __always_inline raw_spinlock_t *spinlock_check(spinlock_t *lock)
{
return &lock->rlock;
}
初始化自旋锁,把lock->raw_lock置为0,lock->magic置为0xdead4ead,lock->owner置为初始状态
- 上锁
static __always_inline void spin_lock(spinlock_t *lock)
{
raw_spin_lock(&lock->rlock);
}
#define raw_spin_lock(lock) _raw_spin_lock(lock)
/**单核CUP UP**/
#define _raw_spin_lock(lock) __LOCK(lock)
/*上锁前关闭抢占*/
#define __LOCK(lock) \
do { preempt_disable(); ___LOCK(lock); } while (0)
/*将lock+1*/
#define ___LOCK(lock) \
do { __acquire(lock); (void)(lock); } while (0)
/**对称多核CPU,SMP**/
void __lockfunc _raw_spin_lock(raw_spinlock_t *lock)
{
__raw_spin_lock(lock);
}
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
/*上锁前关闭抢占,防止死锁*/
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}
void do_raw_spin_lock(raw_spinlock_t *lock)
{
debug_spin_lock_before(lock);
arch_spin_lock(&lock->raw_lock);
mmiowb_spin_lock();
debug_spin_lock_after(lock);
}
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned long tmp;
u32 newval;
arch_spinlock_t lockval;
prefetchw(&lock->slock);
__asm__ __volatile__(
"1: ldrex %0, [%3]\n" //将slock的值保存在lockval这个临时变量中
" add %1, %0, %4\n"
" strex %2, %1, [%3]\n" //将spin lock中的next加一
" teq %2, #0\n" //判断是否有其他的thread插入
" bne 1b"
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp)
: "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
: "cc");
/*判断当前spin lock的状态,如果是unlocked,那么直接获取到该锁*/
while (lockval.tickets.next != lockval.tickets.owner) {
/*如果当前spin lock的状态是locked,那么调用wfe进入等待状态。*/
wfe();
/*其他的CPU唤醒了本cpu的执行,说明owner发生了变化,该新的own赋给lockval,然后继续判断spin lock的状态*/
lockval.tickets.owner = READ_ONCE(lock->tickets.owner);
}
smp_mb();
}
为什么获取锁之前一定要关闭抢占?
假设 process1通过系统调用进入内核态,如果其需要访问临界区,则在进入临界区前获得锁,上锁,然后进入临界区。如果process1在内核态执行临界区代码的过程中发生了一个外部中断,当中断处理函数返回时,因为内核的可抢占性,此时将会出现一个调度点,如果CPU的运行队列中出现了一个比当前被中断进程process1优先级更高的进程process2,那么被中断的进程将会被换出处理器,即便此时它正运行于内核态。进程process2就会进行空转,浪费CPU资源。
当然这种实现方式对于内核中的spinlock比较合适,而一般用户态的spinlock实现不需要
- 尝试上锁
static __always_inline int spin_trylock(spinlock_t *lock)
{
return raw_spin_trylock(&lock->rlock);
}
#define raw_spin_trylock(lock) __cond_lock(lock, _raw_spin_trylock(lock))
/**单核CUP UP**/
#define _raw_spin_trylock(lock) ({ __LOCK(lock); 1; })
#define __LOCK(lock) \
do { preempt_disable(); ___LOCK(lock); } while (0)
#define ___LOCK(lock) \
do { __acquire(lock); (void)(lock); } while (0)
/**对称多核CPU,SMP**/
int __lockfunc _raw_spin_trylock(raw_spinlock_t *lock)
{
return __raw_spin_trylock(lock);
}
#define BUILD_LOCK_OPS(op, locktype) \
void __lockfunc __raw_##op##_lock(locktype##_t *lock) \
{ \
for (;;) { \
preempt_disable(); \
if (likely(do_raw_##op##_trylock(lock))) \
break; \
preempt_enable(); \
\
arch_##op##_relax(&lock->raw_lock); \
} \
}
int do_raw_spin_trylock(raw_spinlock_t *lock)
{
int ret = arch_spin_trylock(&lock->raw_lock);
if (ret) {
mmiowb_spin_lock();
debug_spin_lock_after(lock);
}
#ifndef CONFIG_SMP
/*
* Must not happen on UP:
*/
SPIN_BUG_ON(!ret, lock, "trylock failure on UP");
#endif
return ret;
}
static inline int arch_spin_trylock(arch_spinlock_t *lock)
{
unsigned long contended, res;
u32 slock;
prefetchw(&lock->slock);
do {
__asm__ __volatile__(
" ldrex %0, [%3]\n"
" mov %2, #0\n"
" subs %1, %0, %0, ror #16\n"
" addeq %0, %0, %4\n"
" strexeq %2, %0, [%3]"
: "=&r" (slock), "=&r" (contended), "=&r" (res)
: "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
: "cc");
} while (res);
if (!contended) {
smp_mb();
return 1;
} else {
return 0;
}
}
spin_trylock() 不会自旋,但如果它在第一次尝试时获得自旋锁,则返回非零值,否则返回 0。 此函数可用于所有上下文, 而spin_lock使用时必须禁用可能会中断获取自旋锁的上下文。
- 释放锁
static __always_inline void spin_unlock(spinlock_t *lock)
{
raw_spin_unlock(&lock->rlock);
}
#define raw_spin_unlock(lock) _raw_spin_unlock(lock)
/**单核CUP UP**/
#define _raw_spin_unlock(lock) __UNLOCK(lock)
#define __UNLOCK(lock) \
do { preempt_enable(); ___UNLOCK(lock); } while (0)
/**对称多核CPU,SMP**/
void __lockfunc _raw_spin_unlock(raw_spinlock_t *lock)
{
__raw_spin_unlock(lock);
}
static inline void __raw_spin_unlock(raw_spinlock_t *lock)
{
spin_release(&lock->dep_map, _RET_IP_);
do_raw_spin_unlock(lock);
preempt_enable();
}
static inline void do_raw_spin_unlock(raw_spinlock_t *lock) __releases(lock)
{
mmiowb_spin_unlock();
arch_spin_unlock(&lock->raw_lock);
__release(lock);
}
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{
smp_mb();
lock->tickets.owner++;
dsb_sev();
}
- 判断锁状态
static __always_inline int spin_is_locked(spinlock_t *lock)
{
return raw_spin_is_locked(&lock->rlock);
}
#define raw_spin_is_locked(lock) arch_spin_is_locked(&(lock)->raw_lock)
static inline int arch_spin_is_locked(arch_spinlock_t *lock)
{
return !arch_spin_value_unlocked(READ_ONCE(*lock));
}
static inline int arch_spin_value_unlocked(arch_spinlock_t lock)
{
return lock.tickets.owner == lock.tickets.next;
}
4 实际案例
spinlock的使用很简单:
- 我们要访问临界资源需要首先申请自旋锁;
- 获取不到锁就自旋,如果能获得锁就进入临界区;
- 当自旋锁释放后,自旋在这个锁的任务即可获得锁并进入临界区,退出临界区的任务必须释放自旋锁。
实验:
#include <pthread.h>
#include <stdio.h>
int cnt = 0;
void* task(void* args) {
for(int i = 0; i < 100000; i++)
{
cnt ++;
}
return NULL;
}
int main() {
pthread_t tid1, tid2;
/* create the thread */
pthread_create(&tid1, NULL, task, NULL);
pthread_create(&tid2, NULL, task, NULL);
/* wait for thread to exit */
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
printf("cnt = %d\n", cnt);
return 0;
}
输出:
cnt = 131189
正确结果不应该是200000吗?为什么会出错呢,我们可以从汇编角度来分析一下。
$> g++ -E test.c -o test.i
$> g++ -S test.i -o test.s
$> vim test.s
.file "test.c"
.globl _cnt
.bss
.align 4
_cnt:
.space 4
.text
.globl __Z5task1Pv
.def __Z5task1Pv; .scl 2; .type 32; .endef
__Z5task1Pv:
...
我们可以看到
for(int i = 0; i < 100000; i++)
{
cnt ++;
}
对应的汇编代码为
cmpl $99999, -4(%ebp)
jg L2
movl _cnt, %eax
addl $1, %eax
movl %eax, _cnt
addl $1, -4(%ebp)
jmp L3
一个简单的cnt++,对应
movl _cnt, %eax
addl $1, %eax
movl %eax, _cnt
CPU先将cnt的值读到寄存器eax中,然后将[eax] + 1,最后将eax的值返回到cnt中,这些操作不是**原子性质(atomic)**的,这就导致cnt被多个线程操作时,+1过程会被打断。
比如task1和 task2,假设cnt初始值为0
Task 1 Task 2
load cnt
load cnt
cnt + 1
store cnt cnt + 1
store cnt
本来cnt应该为2,现在却为1
现在使用spinlock,修改后的代码为:
#include <pthread.h>
#include <stdio.h>
pthread_spinlock_t lock;
int cnt = 0;
void* task(void* args) {
for(int i = 0; i < 1000000; i++)
{
pthread_spin_lock(&lock);
cnt++;
pthread_spin_unlock(&lock);
}
return NULL;
}
int main() {
pthread_spin_init(&lock, 0);
pthread_t tid1;
pthread_t tid2;
/* create the thread */
pthread_create(&tid1, NULL, task, (void*)1);
pthread_create(&tid2, NULL, task, (void*)2);
/* wait for thread to exit */
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
printf("cnt = %d\n", cnt);
return 0;
}
输出
cnt = 2000000
保证了cnt++的原子性,最终取得正确结果
Linux常用数据结构 第二篇,哈希表hlist
Linux常用数据结构 第四篇,mutex
参考文章:
















 312
312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











