







目录
quartz.properties Quartz Configuration
本文源码:https://github.com/wangmaoxiong/quartzapp
quartz-scheduler 石英调度器概述
1、Quartz 是功能强大的开源作业调度库,几乎可以集成到任何 Java 应用程序中,从最小的独立应用程序到最大的电子商务系统。Quartz 可用于创建简单或复杂的计划,以执行数以万计的工作;可以执行您编写的所有内容。
2、Quartz Scheduler 包含许多企业级功能,例如对 JTA 事务和集群的支持。Quartz 是免费使用的,并根据 Apache 2.0 许可获得许可。
| Quartz 官网:Quartz Enterprise Job Scheduler 二进制 jar 包下载地址:Downloads 官网文档:Documentation github 开源地址:https://github.com/quartz-scheduler/quartz w3c 教程:Quartz官方文档_w3cschool |
3、Spring Boot 官方也对 Quartz 调度器进行了集成,Spring boot 官网文档:Quartz Scheduler
4、Java JDK 有原生的 计时器 Timer 以及 定时执行服务 ScheduledExecutorService ,Spring 也提供了 @Scheduled 执行定时任务。
5、生产中如果定时任务多,处理频繁,则强烈建议使用第三方封装的调度框架,因为定时器操作底层都是多线程的操作,任务的启动、暂停、恢复、删除、实质是线程的启动、暂停、中断、唤醒等操作。
quartz-scheduler HelloWorld
1、本文环境 Spring Boot 2.1.3 + java jdk 1.8 ,pom.xml 文件中导入 quartz 依赖:
<!--quartz 定时器 https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-quartz -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
<version>2.2.5.RELEASE</version>
</dependency>
源码:https://github.com/wangmaoxiong/quartzapp/blob/master/pom.xml
spring-boot-starter-quartz 组件内部依赖了如下的组件:
| ategory/License | Group / Artifact | Version |
|---|---|---|
| Job Scheduling/Apache 2.0 | org.quartz-scheduler » quartz | 2.3.2 |
| Apache 2.0 | org.springframework » spring-context-support | 5.2.4.RELEASE |
| Transactions/Apache 2.0 | org.springframework » spring-tx | 5.2.4.RELEASE |
| Apache 2.0 | org.springframework.boot » spring-boot-starter | 2.2.5.RELEASE |
2、由浅入深,下面先以一个简单 main 方法调用来介绍 quartz 作业调度器的基本使用步骤。
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 自定义作业实现 org.quartz.Job 接口,execute 方法中写作业逻辑.
*/
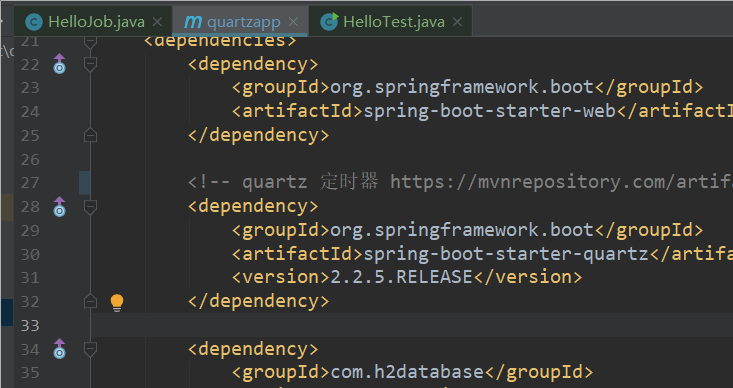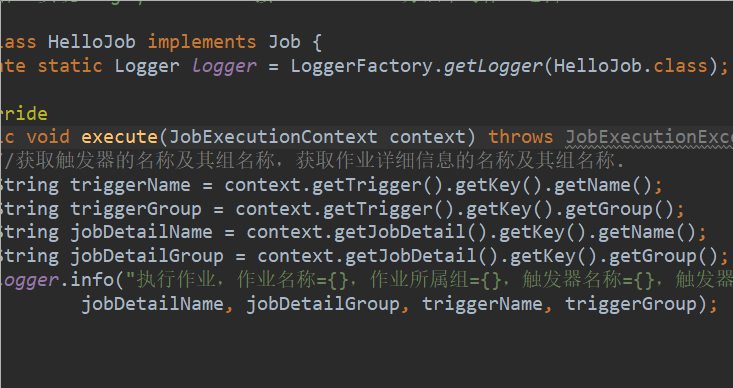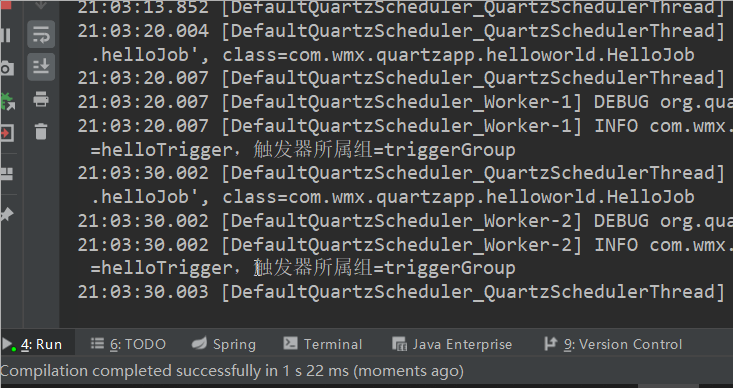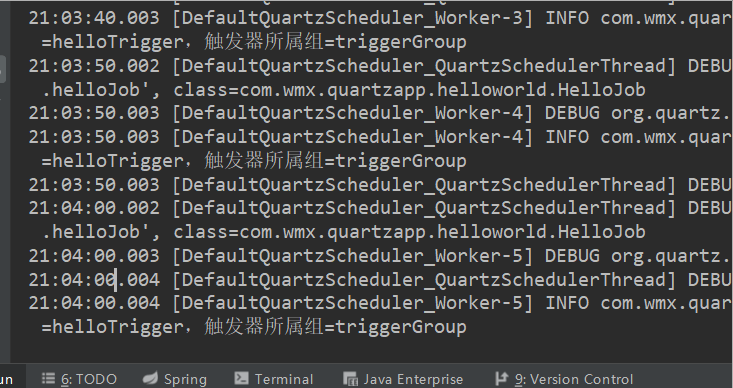
public class HelloJob implements Job {
private static Logger logger = LoggerFactory.getLogger(HelloJob.class);
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
//获取触发器的名称及其组名称,获取作业详细信息的名称及其组名称.
String triggerName = context.getTrigger().getKey().getName();
String triggerGroup = context.getTrigger().getKey().getGroup();
String jobDetailName = context.getJobDetail().getKey().getName();
String jobDetailGroup = context.getJobDetail().getKey().getGroup();
logger.info("执行作业,作业名称={},作业所属组={},触发器名称={},触发器所属组={}",
jobDetailName, jobDetailGroup, triggerName, triggerGroup);
}
}
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
public class HelloTest {
public static void main(String[] args) throws SchedulerException, InterruptedException {
//1)读取 classpath 下的 quartz.properties(不存在就都使用默认值)配置来实例化 Scheduler
//可以在类路径下使用同名文件覆盖 quartz-x.x.x.jar 包下的 org\quartz\quartz.properties 属性文件
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
//2、定义作业的详细信息,并设置要执行的作业的类名。设置作业的名称及其组名.
JobDetail jobDetail = JobBuilder.newJob(HelloJob.class).withIdentity("helloJob", "jobGroup").build();
//3、创建触发器,设置触发器名称与组名称,设置 CronTrigger 触发器的调度规则为每 10 秒触发一次.
//startNow():表示立即触发任务,否则需要等待下一个触发点
CronTrigger cronTrigger = TriggerBuilder.newTrigger().withIdentity("helloTrigger", "triggerGroup")
.startNow()
.withSchedule(CronScheduleBuilder.cronSchedule("0/10 * * * * ?")).build();
//4、将 jobDetail 与 trigger 注册到调度器 scheduler 并启动。
scheduler.scheduleJob(jobDetail, cronTrigger);
scheduler.start();
TimeUnit.MINUTES.sleep(1);//1分钟以后停掉调度器
scheduler.shutdown();
}
}
quartz-scheduler 核心 API
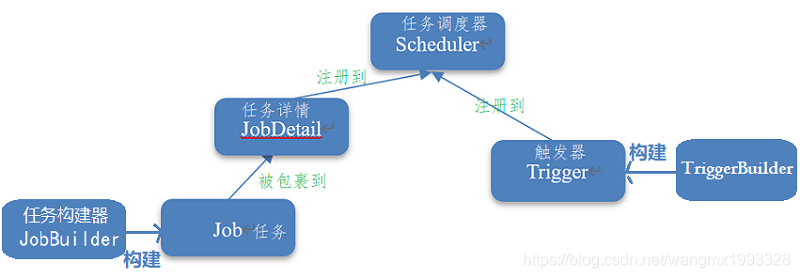
| Scheduler · 调度器 | 1、Scheduler 用来对 Trigger 和 Job 进行管理,Trigger 和 JobDetail 可以注册到 Scheduler 中,两者在 Scheduler 中都拥有自己的唯一的组(group)和名称(name)用来进行彼此的区分,Scheduler 可以通过组和名称来对 Trigger 和 JobDetail 进行管理。 |
| Job · 任务 | 1、Job 是一个任务接口,开发者可以实现该接口定义自己的任务,JobExecutionContext 中提供了调度上下文的各种信息。 |
| JobDetail · 任务详情 | 1、JobDetail 对象是在将 job 注册到 scheduler 时,由客户端程序创建的,它包含 job 的各种属性设置,以及用于存储 job 实例状态信息的 JobDataMap。 |
| Trigger·触发器 | 1、Trigger 用于触发 Job 的执行。TriggerBuilder 用于定义/构建触发器实例。 |
| JobDataMap | 1、JobDataMap 实现了 JDK 的 Map 接口,可以以 Key-Value 的形式存储数据。 2、JobDetail、Trigger 实现类中都定义 JobDataMap 成员变量及其 getter、setter 方法,可以用来设置参数信息,Job 执行 execute() 方法的时候,JobExecutionContext 可以获取到 JobDataMap 中的信息。 |
1、Scheduler 实例化后,可以启动(start)、暂停(stand-by)、停止(shutdown)。
2、Scheduler 被停止后,除非重新实例化,否则不能重新启动;只有当 scheduler 启动后,trigger才会被触发(job才会被执行;暂停状态 trigger 不会触发执行任务。
3、Scheduler 生命周期:从 SchedulerFactory 创建它开始,到 Scheduler 调用 shutdown() 方法结束;Scheduler 被创建后,可以增加、删除和列举 Job 和 Trigger,以及执行其它与调度相关的操作(如暂停Trigger)。
4、SimpleTrigger 触发器主要用于一次性执行的 Job(只在某个特定的时间点执行一次),或者每间隔T个时间单位执行一次。CronTrigger 触发器基于日历进行调度,如“每个星期五的正午”,或者“每月的第十天的上午10:15”等。
5、Job 被创建后,可以保存在 Scheduler 中,与 Trigger 是独立的,同一个 Job 可以有多个 Trigger;这种松耦合的一个好处是可以修改或者替换 Trigger,而不用重新定义与之关联的 Job。
6、Job 和 Trigger 注册到 Scheduler 时,可以为它们设置 key,配置其身份属性。Job 和 Trigger 的key(JobKey和TriggerKey)可以用于将 Job 和 Trigger 放到不同的分组(group)里,然后基于分组进行操作。同一个分组下的 Job 或 Trigger 的名称必须唯一,即一个 Job 或 Trigger 的 key 由名称(name)和分组(group)组成。
quartz.properties Quartz Configuration
1、Quartz 使用一个名为 quartz.properties 的属性文件进行信息配置,必须位于 classpath 下,是 StdSchedulerFactory 用于创建 Scheduler 的默认属性文件。
2、默认情况下 StdSchedulerFactory 从类路径下加载名为 “quartz.properties” 的属性文件,如果失败,则加载 org/quartz 包中的“quartz.properties”文件,其默认内容如下:
#计划程序的名称
org.quartz.scheduler.instanceName: DefaultQuartzScheduler
org.quartz.scheduler.rmi.export: false
org.quartz.scheduler.rmi.proxy: false
org.quartz.scheduler.wrapJobExecutionInUserTransaction: false
org.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPool
#线程池中的线程个数.10个线程表示最多可以同时执行10个任务/作业
org.quartz.threadPool.threadCount: 10
org.quartz.threadPool.threadPriority: 5
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread: true
org.quartz.jobStore.misfireThreshold: 60000
#表示 quartz 中的所有数据,比如作业和触发器的信息都保存在内存中(而不是数据库中)
org.quartz.jobStore.class: org.quartz.simpl.RAMJobStore
3、quartz.properties 可用属性的完整配置信息可以参考官网 Quartz Configuration,根据不同的需求,配置分类如下:
- Main Configuration (configuration of primary scheduler settings, transactions)
- Configuration of ThreadPool (tune resources for job execution)
- Configuration of Listeners (your application can receive notification of scheduled events)
- Configuration of Plug-Ins (add functionality to your scheduler)
- Configuration of RMI Server and Client (use a Quartz instance from a remote process)
- Configuration of RAMJobStore (store jobs and triggers in memory)
- Configuration of JDBC-JobStoreTX (store jobs and triggers in a database via JDBC)
- Configuration of JDBC-JobStoreCMT (JDBC with JTA container-managed transactions)
- Configuration of DataSources (for use by the JDBC-JobStores)
- Configuration of Database Clustering (achieve fail-over and load-balancing with JDBC-JobStore)
- Configuration of TerracottaJobStore (Clustering without a database!)
JobDataMap 任务数据对象
1、创建 JobDetail 时,将要执行的 job 的类名传给了 JobDetail,所以 scheduler 就知道了要执行何种类型的 job;每次当scheduler 执行 job 的 execute(…) 方法之前会创建该类的一个新的实例;执行完毕,对该 Job 实例的引用就被丢弃了,实例会被垃圾回收;
2、Job 实现类中必须有一个无参的构造函数(当使用默认的JobFactory时),Job 实现类中,不应该定义有状态的数据属性,因为在 job 的多次执行中,这些属性的值不会保留。应该使用 JobDataMap 给 Job 实例设置属性,用于在多次执行中跟踪 Job 的状态。
3、JobDetail、Trigger 实现类中都定义 JobDataMap 成员变量及其 getter、setter 方法,可以用来设置参数信息,Job 执行 execute() 方法的时候,JobExecutionContext 可以获取到 JobDataMap 中的信息。
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
/**
* @author wangmaoxiong
*/
public class HiJobTest {
public static void main(String[] args) {
try {
//1)读取 classpath 下的 quartz.properties(不存在就都使用默认值)配置来实例化 Scheduler
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
//2)创建任务详情。设置任务名称与所属组名,同组内的任务名称必须唯一。
// 为任务添加数据,可以直接 usingJobData,也可以先 jobDetail.getJobDataMap(),然后 put
JobDetail jobDetail = JobBuilder.newJob(HiJob.class)
.withIdentity("hiJob", "hiJobGroup")
.usingJobData("url", "https://wangmaoxiong.blog.csdn.net/article/details/105057405")
.build();
//3)设置触发器,设置触发器名称与所属组名,同组内的触发器名称必须唯一。
// 为触发器添加数据,可以直接 usingJobData,也可以先 jobDetail.getJobDataMap(),然后 put
// startNow() 表示启动后立即执行
// withSchedule(ScheduleBuilder<SBT> scheduleBuilder):设置触发器调度计划,withIntervalInSeconds:间隔多少秒执行
// repeatForever:表示用于重复。
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("hiTrigger", "hiTriGroup")
.startNow()
.usingJobData("totalCount", 3)
.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(5).repeatForever())
.build();
//4)注册任务详情与触发器,然后启动
scheduler.scheduleJob(jobDetail, trigger);
scheduler.start();
} catch (SchedulerException e) {
e.printStackTrace();
}
}
}
import org.quartz.Job;
import org.quartz.JobDataMap;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
/**
* @author wangmaoxiong
* quartz 任务/作业
*/
public class HiJob implements Job {
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
//getJobDetail() 返回 JobDetail, getTrigger() 返回 Trigger,然后都可以获取自己的 JobDataMap 进行取值或者设值
//context.getMergedJobDataMap() 返回的 JobDataMap 包含了 JobDetail 与 getTrigger 设置的所有属性
JobDataMap jobDetailDataMap = context.getJobDetail().getJobDataMap();
JobDataMap triggerDataMap = context.getTrigger().getJobDataMap();
String url = jobDetailDataMap.getString("url");
int totalCount = triggerDataMap.getInt("totalCount");
}
}| 1、context.getMergedJobDataMap() 返回的 JobDataMap 是 JobDetail 中的 JobDataMap 和 Trigger 中的 JobDataMap 的并集,但是如果存在相同的数据,则后者会覆盖前者的值。 2、如果在 Job 类中为 JobDataMap 中存储数据的 key 增加 setter 方法,那么 Quartz 的默认 JobFactory 实现会在 job 被实例化的时候自动调用这些 setter 方法进行注值,这样就不需要在 execute() 方法中显式地从 JobDataMap 中取数据了。 |
示例源码:https://github.com/wangmaoxiong/quartzapp/tree/master/src/test/java/com/wmx/quartzapp/helloworld
Job/JobDetail 实例 与 并发
1、一个 Job 实现类可以与多个 JobDetail 实例关联(JobDetal 与 Trigger 一对多),每一个 JobDetail 实例都有自己的属性集和 JobDataMap,最后将所有的实例都注册到 scheduler 中。如 "YearEndSettlementJob" 类实现 Job 接口,该 job 实现需要 JobdataMap 传入一个参数,表示年终结算的季度(1-4)。因此可以创建该 job 的多个实例(JobDetail),如 "jobDetail1"、"jobDetail2"、"jobDetail3"、"jobDetail4", 然后将季度"1,2,3,4"作为 JobDataMap 的属性传入。当一个 trigger 被触发时,与之关联的 JobDetail 实例会被加载,JobDetail 引用的 job 类通过配置在 Scheduler 上的 JobFactory 进行初始化,然后尝试调用 JobDataMap 中的 key 的 setter 方法注入属性值。、
2、Job 的状态数据(JobDataMap)和并发性会被下面两个注解所影响:
| @DisallowConcurrentExecution | 添加到 Job 的实现类上,表示不要并发地执行 Job 实现的同一个实例(JobDetail)。假如上面的“YearEndSettlementJob”类上有该注解,则同一时刻仅允许执行一个“jobDetail1”实例,但可以并发地执行“jobDetail2”、"jobDetail3"、"jobDetail4" 实例。所以该并发限制实际是针对JobDetail 的,而不是 job 的。 |
| @PersistJobDataAfterExecution | 添加到 Job 实现类上,表示调度器在成功执行了 job 类的 execute 方法后(没有发生任何异常),更新 JobDetail 中 JobDataMap 的数据,使得该 JobDetail 在下一次执行的时候JobDataMap 中是更新后的数据,而不是更新前的旧数据。 和 @DisallowConcurrentExecution 注解一样,尽管注解是加在 job 类上,但其限制作用是针对JobDetil 的,而不是 job 类。 |
3、生产环境如果任务执行存在并发问题,则强烈建议加上 @PersistJobDataAfterExecution 、@DisallowConcurrentExecution 注解,因为当同一个 JobDetail 实例被并发执行时,由于竞争,JobDataMap 中存储的数据很可能是不确定的。
4、当任务的执行时间过长,而触发的时间间隔小于执行时间,则会导致同一个 JobDetil 实例被并发执行。所以如果想要验证注解非常简单,只要将执行间隔缩小,然后 Job 实现类的 execute 方法中使用 Thread.sleep() 硬性延迟。查看任务执行情况,然后加上上面的注解才查看。源码如下:
5、通过 JobDetail 对象还可以给 job 实例配置的以下属性:
| Durability | 指示 job 是否是持久性的。如果 job 是非持久的,当没有活跃的 trigger 与之关联时,就会被自动地从 scheduler 中删除。即非持久的 job 的生命期是由 trigger 的存在与否决定的. |
| RequestsRecovery | 指示 job 遇到故障重启后,是否是可恢复的。如果 job 是可恢复的,在其执行的时候,如果 scheduler 发生硬关闭(hard shutdown)(比如运行的进程崩溃了,或者关机了),则当 scheduler 重启时,该 job 会被重新执行。此时该 job 的JobExecutionContext.isRecovering() 返回true。 |
//2)创建任务详情。设置任务名称与所属组名,同组内的任务名称必须唯一。
// 为任务添加数据,可以直接 usingJobData,也可以先 jobDetail.getJobDataMap(),然后 put
JobDetail jobDetail = JobBuilder.newJob(HiJob.class)
.withIdentity("hiJob", "hiJobGroup")
.usingJobData("url", "https://wangmaoxiong.blog.csdn.net/article/details/105057405")
.requestRecovery(true) //设置 job 遇到故障重启后,是否是可恢复的,默认为 false.
.storeDurably(true) //设置 job 是否是持久性的,默认为 false.
.build();MVC 访问调度 Quartz 任务
1、为了学习 Quartz 方便,所以使用了 mian 运行,其实对于 web 应用操作步骤完全同理,如下源码所示:
https://github.com/wangmaoxiong/quartzapp/tree/master/src/main/java/com/wmx/quartzapp
2、其中 WeatherController 控制层提供访问接口,方法中使用 Quartz 调度器调度 WeatherRequestJob 作业,用于定时请求天气信息接口,获取城市的天气数据。
3、WeatherRequestJob 任务中使用 BeanFactoryAware 的方式获取 Spring 容器中的 RestTemplate 实例,然后请求 http 地址.
4、BeanConfig 类是 @Configuration 配置类,使用 @Bean 将 RestTemplate 实例交由 Spring 容器管理.
5、控制层接口返回的数据使用 ResultData 对象进行封装,包含 code、message、data 三部分,同时提供 ResultCode 枚举提供常用的返回值类型。
本文介绍的是内存存储,即所有的调度信息全部存储在内存中,如果需要使用 jdbc 存储到数据库中,则可以参考《Spring Boot 2.1.3 集成 Quartz 定时器, jdbc 持久化调度信息》


















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











