






0 redis背景
Redis诞生背景
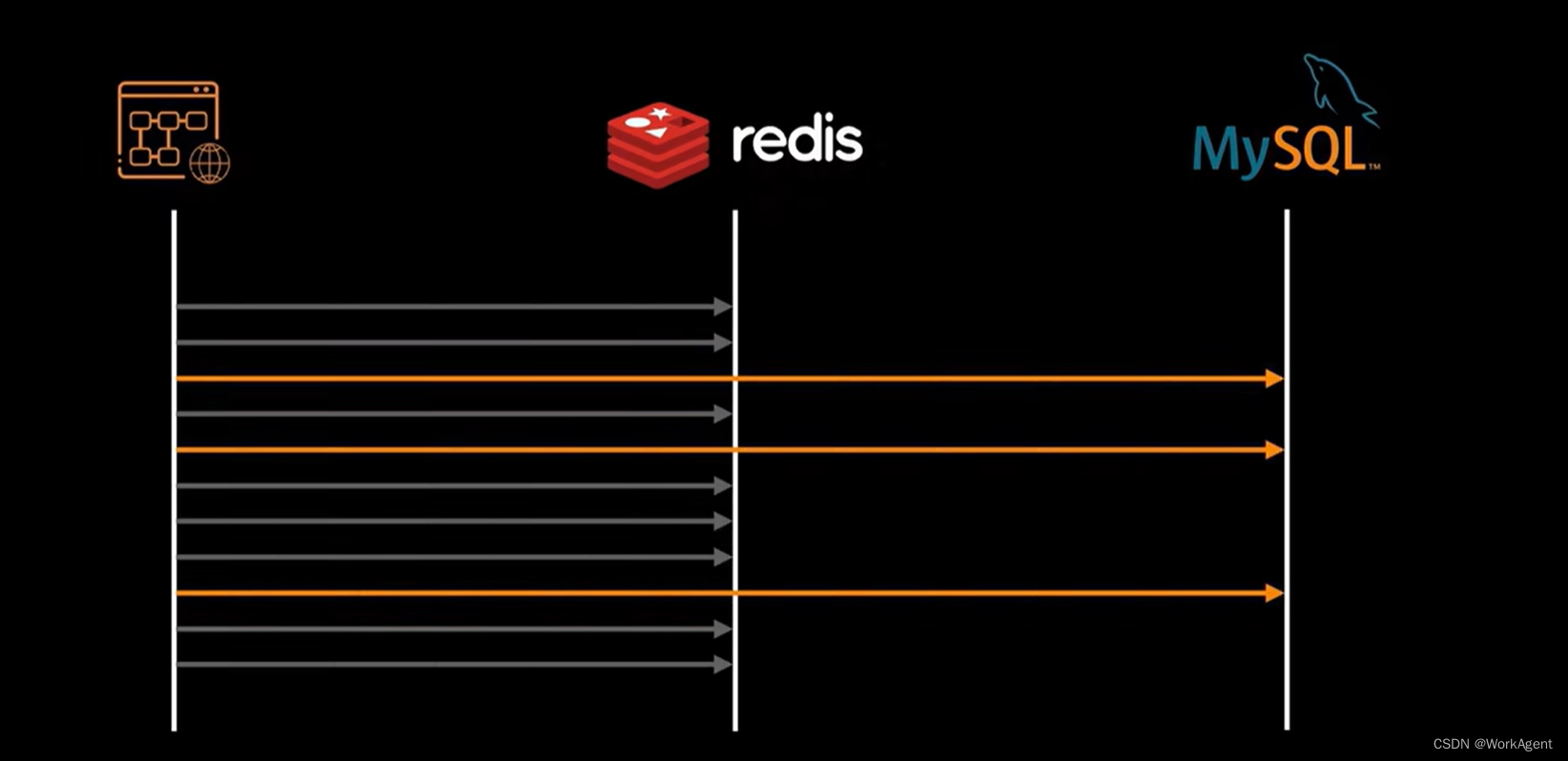
关系型数据库据中一大半操作都是读操作,而且经常都是重复查询一个东西,这浪费了数据库很多时间去进行磁盘I/O.这也是后续很多内存数据库崛起的背景.
学习CPU给数据库也加一个缓存,诞生了Redis.应用程序从mysql查询到的数据,先在redis登记,后续再有读请求,先在redis进行查询.redis把数据都存储在内存内存中不需要进行磁盘I/O,所以速度极快.为Mysql减轻了很大的负担.
Redis缓存管理机制
防止缓存无限制增加,给缓存增加一个超时时间,超出超时时间的内容进行清空.
考虑到缓存中存了大量数据,全面扫描一次进行清理需要很长时间,严重影响接受新的请求,所以Redis采取随机选取部分进行清理.
但是概率上会存在部分数据可能长时间不被清理掉.于是在原来定期删除的基础之上,增加:原来已经超期的键值,如果遇到查询请求,则立即进行删除.这是被动式触发,如果不查询就不会删除,因此叫惰性删除.
还会有一部分数据既逃离了随机删除算法也逃离了惰性删除,慢慢的可用的内存空间则会越来越少,(或者设置过期时间很长,还没来得及清理,内存就吃满了),-出现内存淘汰策略

结合以上策略,可以不用担心内存爆满的问题
定时删除 + 惰性删除 + 内存淘汰
缓存穿透:如果查询数据不存在,那么redis也没办法缓存,所以同样的请求来了,每次还是需要mysql进行查询,(如果存在大量重复的恶意或者批量查询,严重影响数据库性能)
热点数据过期,被redis删除,但是删除后短时间内大量请求,就会都到mysql服务器
缓存雪崩:如果一大批数据同时或者一起过了有效期,又发生了很多对这些数据的请求,比起缓存穿透规模更大
解决缓存雪崩的方案:让应用程序对缓存过期时间设置的长一点均匀一点,不让缓存一起过期.把键值的过期时间随机一下+热点数据永不过期
Redis持久化存储机制
Redis为基于内存的,进程服务down掉内容丢失.需要做持久化存储
持久化方案:RDB持久化是将全部数据记录定时dump到磁盘上进行持久化,恢复数据通过读取原始数据加载到内存恢复数据,数据恢复快,效率高,但是数据容易丢失(数据同步有时间间隔).
为了节约空间,二进制格式生成RDB文件,但是数据量大,全部备份时间成本较高,不能太频繁备份.如果一直都是读取操作没有写入操作,也不需要重复备份.提供周期性备份参数.即使断电或者服务器宕机,可以在启动的时候读取备份文件,恢复状态
RDB的问题:数据丢失问题
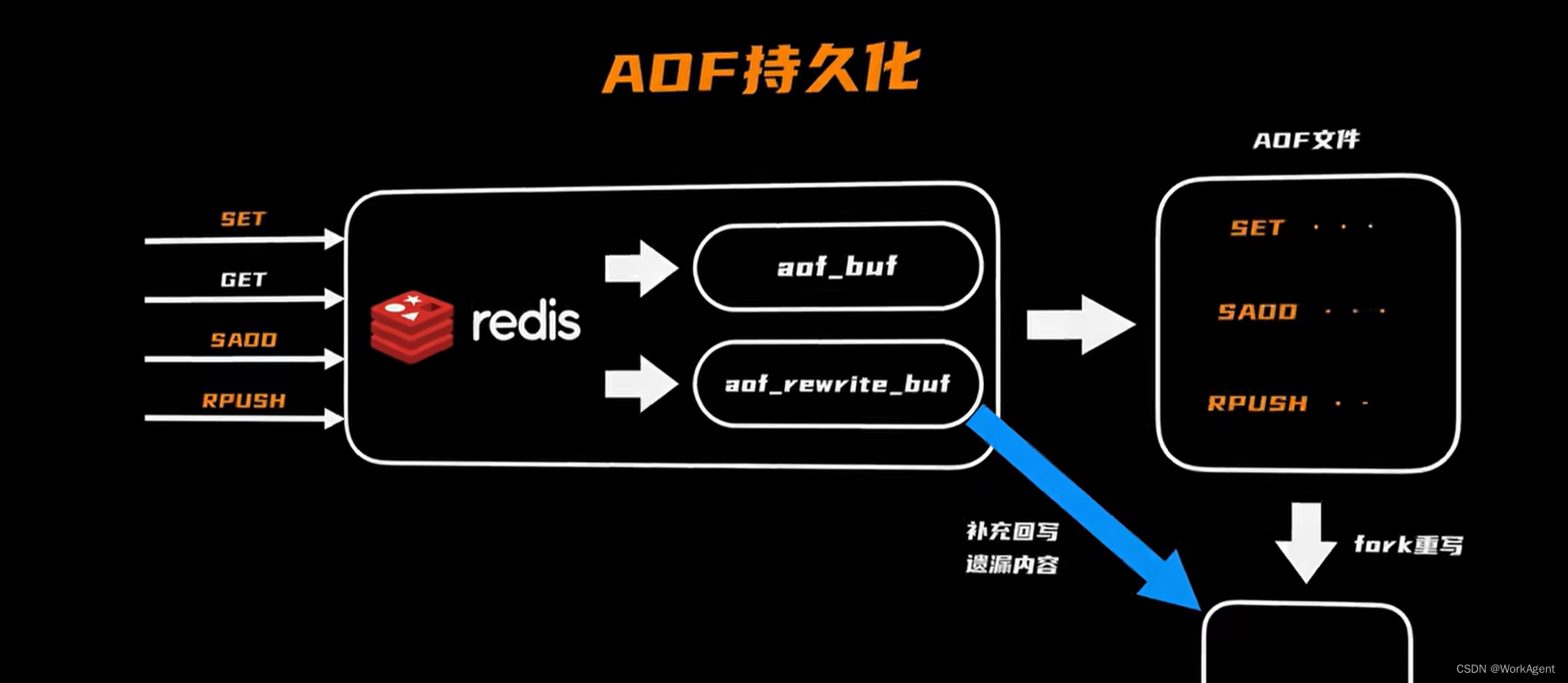
AOF持久化是将操作日志追加形式写入文件,恢复数据通过命令恢复数据,缓存一致性更高,牺牲性能.
Mysql中的BinLog => AOF
多久进行一次写入呢? 建立临时缓冲区aof_buf 再择机将临时缓冲区内容写入文件
但是随着时间推移,AOF备份文件越来越大,加载分析越来越慢
AOF重写:去除冗余指令给AOF文件瘦身,- 工作量太大
指令合并
Redis哨兵与高可用
即使有了缓存持久化管理,但是也要考虑redis稳定性高可用问题
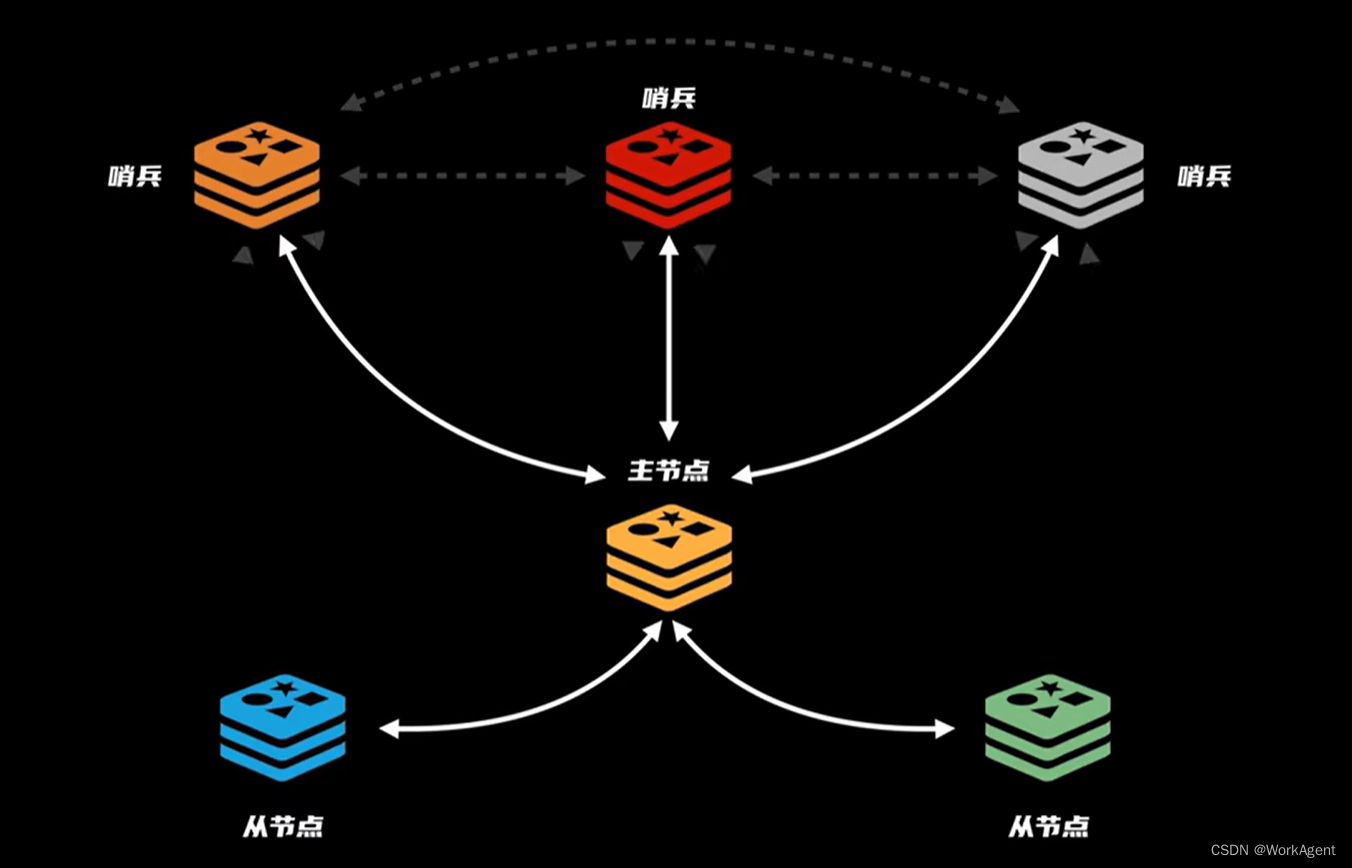
命令传播:主节点将命令传播给从节点
考虑到子节点掉线,数据同步问题
从节点中选择一个管理员,不负责数据的读写,只负责协调各个节点,称为哨兵Sentinel
哨兵每隔10s中用info命令去询问主节点,主节点回复都有哪些从节点,哨兵则每隔一秒用ping命令与各个子节点交互.如果发现主节点掉线,这时候判定为主观下线,多个哨兵一起判定,如果都认为下线则是客观下线
故障转移选择新的主节点
Redis集群工作原理
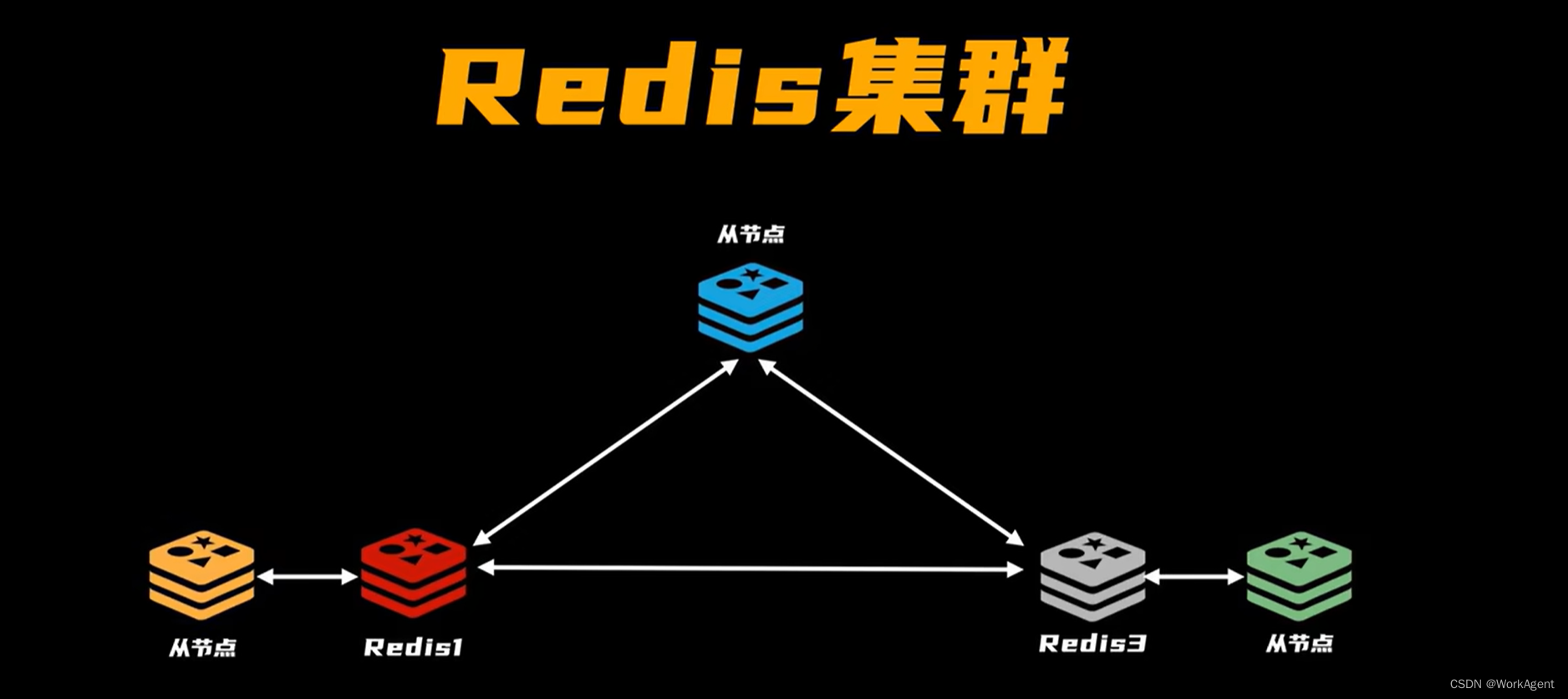
主从复制+哨兵可以解决高可用问题,但是不能解决数据量大的问题
变成集群解决数据量大的问题
存储公平问题 -hash随机性
1.redis基础
1.1 基础概念
key - value
键值数据库 -> NoSql数据库
1.1.1 初始redis
sql关系型数据库
NoSql非关系型数据库 或者 not only sql
对比差异:
- S-Structured 结构化 nosql对数据格式没有严格约束,可以是键值型、文档型或者图格式
- R-Relational 关联 传统数据库中存在外键约束即关联。nosql不存在关联,
- Q-Query查询 sql查询通常使用select ...等等语句 但是nosql方式不统一:redis mongoDB elasticSearch查询方式不同
- 事务:事务满足ACID,而nosql往往不支持事务,只能实现一些基本的一致性 base理论。如果对ACID要求严格,尽量首选sql而不是nosql
- 存储方式:sql大多数以磁盘为主,nosql通常以内存为主
redis - Remote Dictionary Server 远程词典服务器 基于内存的键值型nosql数据库
特征:
- 键值型 key-value型:支持多种不同的数据结构 功能丰富
- 单线程,每个命令有原子性
- 低延迟,速度快
- 支持数据持久化
- 支持主从集群、分片集群
1.1.2 redis常用命令
常见数据结构:
redis为key-value的数据库,其中key通常为string类型,但是value类型种类多样
- String:分为普通string int float 底层都是字节数组形式存储,只是编码方式不同 操作:SET GET MSET MGET INCR INCRBY
- Hash:也叫散列。其value是一个无序字典,类似于java中的hashMap。更加灵活。操作:HSET HGET HGETALL [HSET dlut:user:1 name kasha age 18 设置key为dlut:user:1的hash中name=kasha age=18] []


- List : 与java中的LinkedList类似,可以看成一个双向链表。支持正向检索也支持反向检索。

- Set
- SortedSet - 也叫zSet 其中每个元素都要指定一个score值和member值,可以根据socre值排序 number必须唯一 可以根据member查询分数 zset底层数据结构必须满足 键值存储 键必须唯一 可排序 skiplist 可以排序
- GEO 地理坐标
- BitMap 位操作
- HyperLog 位操作
通用常用命令:
- keys push_news_* :查找相关的key redis为单线程会造成阻塞
- del push_news_1 push_news_2: 删除key
- exists keys_1 :判断key是否存在
- expire :给key设置有效期,有效期到期时key自动删除
- TTL key_2 : 查看key的剩余时长
官网上常用命令:Commands | Docs![]() https://redis.io/docs/latest/commands/
https://redis.io/docs/latest/commands/
1.1.3 关于key - key的分级存储
因为redis没有sql中表的概念,如果学生id为1,教师id也是1 怎么办?
key的结构:redis的key允许多个单词形成层级结构,多个单词之间用:隔开,格式如下:
项目名称:业务名称:类型:id
user相关的key:dlut:user:1
product相关的key:dlut:product:1
如果value是一个java对象,则可以将对象序列化为json字符串之后进行存储















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









