










Eclipse Deeplearning4j GitChat课程:Deeplearning4j 快速入门_专栏
Eclipse Deeplearning4j 系列博客:万宫玺的专栏_wangongxi_CSDN博客
Eclipse Deeplearning4j Github:https://github.com/eclipse/deeplearning4j
在之前的文章中,我们基于Embedding+LSTM的结构实现了一个文本分类的应用。本质上,这是循环神经网络Many-to-One架构下的一种应用。在那种结构中,我们将Embedding后的词向量依次投入到LSTM Cell中,循环结构依照时序逐步计算并且获取到整个文本的语义(向量化表示),在此基础上对文本的语义向量进行SoftMax,得到分类标签。这种基于循环神经网络的分类结构最主要的问题在于长距离依赖的问题。尽管我们可以采用LSTM或者GRU这种改进后的Cell,但是当文本较长的时候依然会存在这样的问题。对此我们可以运用一些trick来解决这些问题,比如Truncated-BPTT来训练循环神经网络,这里我们不讨论这些trick的细节,我们希望从另一个角度来重新审视文本分类的问题。这就是这篇文章讨论的重点:TextCNN。
在开始描述TextCNN的细节之前,我们先回顾下基于词袋模型(Bag-Of-Words)+ 分类器来解决文本分类的传统方法。词袋模型用于结构化文本特征。一般我们对所有语料切词后,统计下词空间的维度(一般会有几万甚至上百万),然后用One-Hot的方式对语料进行编码,每个词会占据这个达到几万甚至几十万维的向量中的一个位置。它的值可以是1或者0,也可以是一些类似TF-IDF的算法值。这个特征表示方式的明显缺陷在于维度高,并且丢失了时序信息。我们重点看第二点。针对于时序信息的丢失,直接的解决方案就是采用N-gram的语言模型进行扩充。一般,这里的N可以取2,3,4就可以了。语言模型是通过“绑定”连续的几个词来变相解决时序问题的一种方式,但毫无疑问,加入语言模型后的词空间维度又将上升,这对接下来分类器的训练会造成很大的影响,无论是存储还是算力都会有较大的消耗。
卷积神经网络(CNN)最成功的应用是在机器视觉领域的一些问题,但对于自然语言处理的问题同样适用。我们可以将语料中的词进行向量化之后,构成一个大的二维矩阵(每一个矩阵就代表一条语料)。我们将kernel size处理成N x VectorSize的大小,其中N代表N-gram语言模型中的N元的含义,这样就可以通过卷积操作抽取语料中的文本信息。当然,实际的操作可以是多尺度的kernel size同时对语料进行语义抽取,最终merge在一起就可以得到在不同维度语言模型下的文本语义。这就是TextCNN这篇文章的核心思想(https://arxiv.org/pdf/1408.5882.pdf)。下面看下论文中的截图:

截图的结构是Conv + Max-Pool + MLP-Classifier的经典结构。我们重点看Conv层的输入。这是一个9 x 6 x 1(Height x Width x Channel)的矩阵,该条训练语料中一共包含9个词,每个词的词向量维度是6。我们可以把这条语料矩阵化后的表示方式认为是一张9 x 6的灰度图。卷积操作后的featureMap的数量这里我们不讨论,这个超参数在实践的时候调优即可。我们需要关注的是每个featureMap其实是一个M x 1的向量。M的大小取决于stride纵向的步长,而featureMap的Width等于1显然是stride的横向步长等于vectorSize的结果。这在上面的阐述中我们已经有所提及。下面我们基于Deeplearning4j来搭建这样的一个TextCNN网络
public static ComputationGraph getTextCNN(final int vectorSize, final int numFeatureMap,
final int corpusLenLimit){
ComputationGraphConfiguration config = new NeuralNetConfiguration.Builder()
.weightInit(WeightInit.RELU)
.activation(Activation.LEAKYRELU)
.updater(new Adam(0.01))
.convolutionMode(ConvolutionMode.Same)
.l2(0.0001)
.graphBuilder()
.addInputs("input")
.addLayer("2-gram", new ConvolutionLayer.Builder()
.kernelSize(2,vectorSize)
.stride(1,vectorSize)
.nIn(1)
.nOut(numFeatureMap)
.build(), "input")
.addLayer("3-gram", new ConvolutionLayer.Builder()
.kernelSize(3,vectorSize)
.stride(1,vectorSize)
.nIn(1)
.nOut(numFeatureMap)
.build(), "input")
.addLayer("4-gram", new ConvolutionLayer.Builder()
.kernelSize(4,vectorSize)
.stride(1,vectorSize)
.nIn(1)
.nOut(numFeatureMap)
.build(), "input")
.addVertex("merge", new MergeVertex(), "2-gram", "3-gram", "4-gram")
.addLayer("globalPool", new GlobalPoolingLayer.Builder()
.poolingType(PoolingType.MAX)
.dropOut(0.5)
.build(), "merge")
.addLayer("out", new OutputLayer.Builder()
.lossFunction(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.activation(Activation.SOFTMAX)
.nIn(300)
.nOut(2)
.build(), "globalPool")
.setOutputs("out")
.setInputTypes(InputType.convolutional(corpusLenLimit, vectorSize, 1))
.build();
ComputationGraph net = new ComputationGraph(config);
net.init();
return net;
}我们来剖析一下这段建模逻辑。注意下,我这次用的Deeplearning4j的版本是1.0.0-beta2,部分API和之前的0.8.0版本有微调,需要注意下。
.setInputTypes(InputType.convolutional(corpusLenLimit, vectorSize, 1))这段设置我们可以看到输入的结构。这和我们之前说的是类似的,corpusLenLimit x vectorSize代表了语料向量化矩阵的Height x Width。至于通道数,这里就是1。
.addLayer("2-gram", new ConvolutionLayer.Builder()
.kernelSize(2,vectorSize)
.stride(1,vectorSize)
.nIn(1)
.nOut(numFeatureMap)
.build(), "input")这段设置的目的从Layer的名称为“2-gram”就可以看出这是基于2元语言模型来抽取语料的时序信息。卷积核的size是2 x vectorSize,步长stride为1 x vectorSize可以保证输出的featureMap是一个(corpusLen - 1)x 1的向量。corpusLen代表文本语料切词后的长度。其他的两个卷积操作是类似的,不过是提取的3-gram和4-gram的信息。
.addVertex("merge", new MergeVertex(), "2-gram", "3-gram", "4-gram")这个Merge层比较重要。之前的三个卷积层都输出了numFeatureMap数量的feature map。这个Merge层就是将其合并在一起构成了3 x numFeatureMap数量的全局的feature map。
.addLayer("globalPool", new GlobalPoolingLayer.Builder()
.poolingType(PoolingType.MAX)
.dropOut(0.5)
.build(), "merge")GlobalPoolingLayer和之前文章中介绍的SubsamplingLayer有相似的地方,都是做池化。但是它们也有不同的地方,就是GlobalPoolingLayer对于feature map会直接从矩阵(TextCNN实际就是一个向量)中抽取值最大的元素(如果是Max-Pool的话)作为池化结果。实际完成的是: [miniBatchSize, channels, height, width] -> 2d output [miniBatchSize, channels]的计算。因此在经过GlobalPoolingLayer的计算后,TextCNN输出的其实就是一个3 x numFeatureMap的向量。
以上就是对TextCNN结构中的一些关键部分的剖析。下面我们来构建训练数据集。语料部分和我之前在基于LSTM做文本分类的那篇博客用的语料是一样的。这里直接把图贴一下:


截图中涉及两个文件,一个是语料本身(已经用jieba切过词)并shuffle过,另一个是对应的标注信息。我们来看下数据集的构建。
private static DataSetIterator getDataSetIterator(WordVectors wordVectors, int minibatchSize,
int maxSentenceLength){
String corpusPath = "comment/corpus.txt";
String labelPath = "comment/label.txt";
String line;
List<String> sentences = new LinkedList<>();
List<String> labels = new LinkedList<>();
try(BufferedReader br = new BufferedReader(new FileReader(corpusPath))){
while((line = br.readLine()) != null)sentences.add(line);
}catch(Exception ex){
ex.printStackTrace();
}
//
try(BufferedReader br = new BufferedReader(new FileReader(labelPath))){
while((line = br.readLine()) != null)labels.add(line);
}catch(Exception ex){
ex.printStackTrace();
}
//
LabeledSentenceProvider sentenceProvider = new CollectionLabeledSentenceProvider(sentences, labels);
TokenizerFactory tokenizerFactory = new DefaultTokenizerFactory();
tokenizerFactory.setTokenPreProcessor(new CommonPreprocessor());
System.out.println("DataSetIter 2 Current Num of Classes:" + sentenceProvider.numLabelClasses());
System.out.println("DataSetIter 2 Total Num of samples: " + sentenceProvider.totalNumSentences());
//
return new CnnSentenceDataSetIterator.Builder(Format.CNN2D)
.sentenceProvider(sentenceProvider)
.wordVectors(wordVectors)
.minibatchSize(minibatchSize)
.maxSentenceLength(maxSentenceLength)
.tokenizerFactory(tokenizerFactory)
.useNormalizedWordVectors(false)
.build();
}这部分的逻辑主要可以分为两个部分。第一个是分别从语料文件和标注文件中读取所有的记录。第二个部分则是使用Deeplearning4j内置的CnnSentenceDataSetIterator工具类构建训练数据集。这里需要注意一点,wordVectors这个对象实例其实是我事先已经使用Word2Vec训练好的模型实例。我们可以通过下面的逻辑来加载已经训练好的模型:
WordVectors wordVectors = WordVectorSerializer.loadStaticModel(new File("w2v.mod"));最后,我们把完整的训练逻辑贴一下。
final int batchSize = 32;
final int corpusLenLimit = 256;
final int vectorSize = 128;
final int numFeatureMap = 100;
final int nEpochs = Integer.parseInt(args[0]);
//读取预先训练好的Word2Vec的模型,并且构建训练和验证数据集
WordVectors wordVectors = WordVectorSerializer.loadStaticModel(new File("w2v.mod"));
DataSetIterator trainIter = getDataSetIterator(wordVectors, batchSize, corpusLenLimit);
DataSetIterator testIter = getDataSetIterator(wordVectors, 1, corpusLenLimit);
//生成TextCNN模型,并打印模型结构信息
ComputationGraph net = getTextCNN(vectorSize, numFeatureMap, corpusLenLimit);
System.out.println(net.summary());
//使用单条记录并且打印每一层网络的输入和输出信息
INDArray input = testIter.next().getFeatures();
System.out.println(input.shapeInfoToString());
Map<String,INDArray> map = net.feedForward(input, false);
for( Map.Entry<String, INDArray> entry : map.entrySet() ){
System.out.println(entry.getKey() + ":" + entry.getValue().shapeInfoToString());
System.out.println();
}
//训练开始。。。
System.out.println("Starting training");
net.setListeners(new ScoreIterationListener(1));
for (int i = 0; i < nEpochs; i++) {
net.fit(trainIter);
System.out.println("Epoch " + i + " complete. Starting evaluation:");
Evaluation evaluation = net.evaluate(trainIter);
trainIter.reset();
testIter.reset();
System.out.println(evaluation.stats());
}这段建模的主逻辑大致可以分为三个部分。首先是超参数的定义。这里我们直接把batchSize、vectorSize等参数进行硬编码,用户可以根据的实际需要进行定制。其次是基于之前提到的数据集构建逻辑来读取文本中的语料和标注并且生成完整的训练语料。再者则是生成TextCNN网络模型并且为了更好地分析模型,我们从测试集中选取了一条记录并通过打印在前向传播过程中每一层网络的输入和输出来得到网络的信息。最后一部分则是和之前文章中相似,进行模型训练并在每一轮训练后进行模型准确性的评估。我们先来看下模型的基本信息截图。
==========================================================================================================================================================================================================================================================
VertexName (VertexType) nIn,nOut TotalParams ParamsShape Vertex Inputs
==========================================================================================================================================================================================================================================================
input (InputVertex) -,- - - -
2-gram (ConvolutionLayer) 1,100 25700 W:{100,1,2,128}, b:{1,100} [input]
3-gram (ConvolutionLayer) 1,100 38500 W:{100,1,3,128}, b:{1,100} [input]
4-gram (ConvolutionLayer) 1,100 51300 W:{100,1,4,128}, b:{1,100} [input]
merge (MergeVertex) -,- - - [2-gram, 3-gram, 4-gram]
globalPool (GlobalPoolingLayer) -,- 0 - [merge]
out (OutputLayer) 300,2 602 W:{300,2}, b:{1,2} [globalPool]
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Total Parameters: 116102
Trainable Parameters: 116102
Frozen Parameters: 0
==========================================================================================================================================================================================================================================================这是TextCNN的基本信息截图。包括每一层网络的名称以及超参数的量。下面是我们选取一条记录后,通过TextCNN每一层前向传播过程中的输入输出数据的截图。
Rank: 4,Offset: 0
Order: c Shape: [1,1,64,128], stride: [8192,8192,128,1]
3-gram:Rank: 4,Offset: 0
Order: c Shape: [1,100,64,1], stride: [64,64,1,1]
input:Rank: 4,Offset: 0
Order: c Shape: [1,1,64,128], stride: [8192,8192,128,1]
globalPool:Rank: 2,Offset: 0
Order: c Shape: [1,300], stride: [1,1]
4-gram:Rank: 4,Offset: 0
Order: c Shape: [1,100,64,1], stride: [64,64,1,1]
merge:Rank: 4,Offset: 0
Order: c Shape: [1,300,64,1], stride: [19200,64,1,1]
2-gram:Rank: 4,Offset: 0
Order: c Shape: [1,100,64,1], stride: [64,64,1,1]
out:Rank: 2,Offset: 0
Order: c Shape: [1,2], stride: [1,1]我们先单独看2-gram、3-gram、4-gram这几层的输出数据结构。可以看到,都是1x100x64x1的4维张量。第一个1代表的是mini-batch,因为我取的是1条数据,所以这里就是1,否则会随着batch的数量变化。这里的100代表的是Channel的数量,实际上也就是feature map的数量。64代表的是该条语料中有64 + 1 = 65 个词。最后一个1则是代表在经过卷积操作后,feature map的Width等于1,原因上面已经有过分析。接下来我们来看下merge这层的输出。这是一个1x300x64x1的4维张量。很显然,这是将上面三个卷积层输出也就是3个1x100x64x1的张量合成为一个1x300x64x1的张量。在globalPool之后,输出是一个1x300的向量。最后在输出层就是基于这个300维的向量进行分类。
我们来看下训练20轮后的指标。
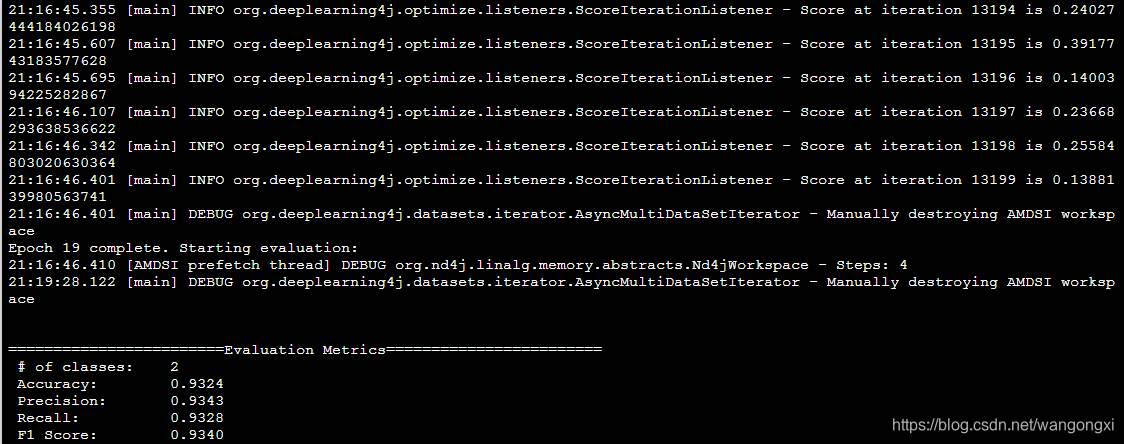
从截图中我们可以看到20轮训练后达到了相对不错的指标。这个指标和之前基于LSTM的模型在20轮后结果比较起来相差不大。当然这样的比较没有太大的意义,毕竟两种网络结构并没有在一个相对等价的条件下进行比较的,仅供大家参考。
最后总结下这次的工作。在这篇文章中,我们给出了基于CNN的文本分类的解决方案。应当说,TextCNN是基于N-gram语言模型与神经网络结合的一种文本分类工具。对于传统2D-CNN结构的神经网络来说,时序的信息是比较难抽取的。因此,在TextCNN的论文中,作者其实是想通过语言模型来弥补这个缺陷。当然需要指出的是,这样的做法其实是比较有效的,尤其是针对文本分类的任务来说。文本分类的任务其实很多时候就是局部的两三个词的信息就可以决定了这条语料的类别,因此基于语言模型来做确实是一种较好的思路。需要指出的是,我们这里用的词向量是预先用Word2Vec训练好的,而不是直接随着建模的时候自动训练出来的。理论上,在训练的时候加入Embedding会使得最后的分类结果进一步提升,这在论文的结论中也有所提及,有兴趣的朋友可以自行尝试。

















 393
393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











