







每CPU变量(per-cpu-variable)是内核中一种重要的同步机制。顾名思义,每CPU变量就是为每个CPU构造一个变量的副本,这样多个CPU相互操作各自的副本,互不干涉。比如我们标识当前进程的变量current_task就被声明为每CPU变量。
每CPU变量的特点:
1、用于多个CPU之间的同步,如果是单核结构,每CPU变量没有任何用处。
2、每CPU变量不能用于多个CPU相互协作的场景。(每个CPU的副本都是独立的)
3、每CPU变量不能解决由中断或延迟函数导致的同步问题
4、访问每CPU变量的时候,一定要确保关闭进程抢占,否则一个进程被抢占后可能会更换CPU运行,这会导致每CPU变量的引用错误。
我们可以用数组来实现每CPU变量吗?比如,我们要保护变量var,我们可以声明int var[NR_CPUS],CPU num就访问var[num]不就可以了吗?
显然,每CPU变量的实现不会这么简单。理由:我们知道为了加快内存访问,处理器中设计了硬件高速缓存(也就是CPU的cache),每个处理器都会有一个硬件高速缓存。如果每CPU变量用数组来实现,那么任何一个CPU修改了其中的内容,都会导致其他CPU的高速缓存中对应的块失效。而频繁的失效会导致性能急剧的下降。
每CPU变量分为静态和动态两种,静态的每CPU变量使用DEFINE_PER_CPU声明,在编译的时候分配空间;而动态的使用alloc_percpu和free_percpu来分配回收存储空间。下面我们来看看Linux中的具体实现:
DECLARE_PER_CPU(type, name) 静态分配一个每CPU数组,数组名为name,结构类型为type
per_cpu(name, cpu) 为CPU选择一个每CPU数组元素,CPU由参数CPU指定,数组名为name
_get_per_cpu(name) 选择每CPU数组name的本地CPU元素
per_cpu_var(name) 先禁用内核抢占,然后在每CPU数组name中,为本地CPU选择元素
put_cpu_var(name) 启用内核抢占
alloc_percpu(type) 动态分配type类型数据结构的每CPU数组,并返回它的地址
free_percpu(pointer) 释放被动态分配的每CPU数组
per_cpu_ptr(pointer, cpu) 返回每CPU数组中与参数cpu对应的cpu元素地址
通常情况下,静态声明的每CPU变量都会被编译在ELF文件中的以“.data..percpu”开头的段中(默认情况就是.data.percpu,也可以使用DEFINE_PER_CPU_SECTION(type,name,sec)来指定段的后缀)
#ifdef CONFIG_SMP
#define PER_CPU_BASE_SECTION ".data..percpu"
#else
#define PER_CPU_BASE_SECTION ".data"
#endif
#define __PCPU_ATTRS(sec) \
__percpu __attribute__((section(PER_CPU_BASE_SECTION sec))) \
PER_CPU_ATTRIBUTES
#define DEFINE_PER_CPU_SECTION(type, name, sec) \
__PCPU_ATTRS(sec) PER_CPU_DEF_ATTRIBUTES \
__typeof__(type) name
#define DEFINE_PER_CPU(type, name) \
DEFINE_PER_CPU_SECTION(type, name, "")看到这里有一个问题:如果我们只是声明了一个变量,那么如何有多个副本的呢?奥妙在于内核加载的过程。
一般情况下,ELF文件中的每一个段在内存中只会有一个副本,而.data.percpu段再加载后,又被复制了NR_CPUS次,一个每CPU变量的多个副本在内存中是不会相邻。示意图如下:
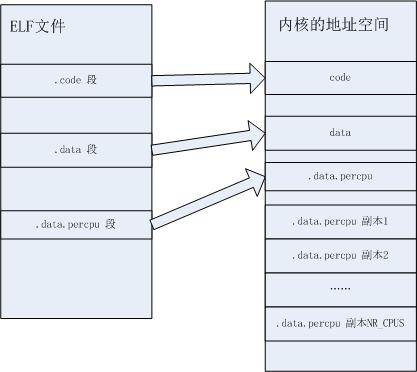
/arch/i386/kernel/vmlinux.lds.S根据指明的section属性,我们知道在内核启动过程中该节所占的存储空间被释放了
SECTIONS
{
...
__per_cpu_start = .;
.data.percpu : { *(.data.percpu) }
__per_cpu_end = .;
...
}
具体的代码参加start_kernel中调用的setup_per_cpu_areas函数。代码如下:
static void __init setup_per_cpu_areas(void)
{
unsigned long size, i;
char *ptr;
/* Created by linker magic */
extern char __per_cpu_start[], __per_cpu_end[];
/* Copy section for each CPU (we discard the original) */
size = ALIGN(__per_cpu_end - __per_cpu_start, SMP_CACHE_BYTES);
#ifdef CONFIG_MODULES
if (size < PERCPU_ENOUGH_ROOM)
size = PERCPU_ENOUGH_ROOM;
#endif
ptr = alloc_bootmem(size * NR_CPUS);
for (i = 0; i < NR_CPUS; i++, ptr += size) {
__per_cpu_offset[i] = ptr - __per_cpu_start;
memcpy(ptr, __per_cpu_start, __per_cpu_end - __per_cpu_start);
}
}
备注:__per_cpu_offset数组中记录了每个CPU的percpu区域的开始地址。我们访问每CPU变量就要依靠__per_cpu_offset中的地址。
动态每CPU变量
了解了静态的每CPU变量的实现机制后,就很容易想到动态的每CPU变量的实现方法了。实际上,在setup_per_cpu_areas的时候,我们会为每个CPU都多申请一部分空间留作动态分配每CPU变量之用(一个场景就是内核模块中的每CPU变量)。相对于静态的每CPU变量,我们需要额外管理内存的分配和回收。
每CPU变量的访问
#define RELOC_HIDE(ptr, off) \
({ unsigned long __ptr; \
__ptr = (unsigned long) (ptr); \
(typeof(ptr)) (__ptr + (off)); })
#define DEFINE_PER_CPU(type, name) \
__attribute__((__section__(".data.percpu"))) __typeof__(type) per_cpu__##name
/* var is in discarded region: offset to particular copy we want */
#define per_cpu(var, cpu) (*RELOC_HIDE(&per_cpu__##var, __per_cpu_offset[cpu]))
#define __get_cpu_var(var) per_cpu(var, smp_processor_id())















 465
465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









