







半导体存储器有
- RAM:随机访问、可读可写、易失的存储器
- ROM;非易失性存储器
随机访问存储器RAM,断点信息会丢失。分为两类:
- 静态SRAM,更快,用作高速缓存存储器cache
- 动态DRAM,用作主存及图形系统的帧缓冲区。
1、静态RAM:SRAM
将每个位存储在双稳态(0与1)存储单元里
2、动态RAM:DRAM
3、增强的DRAM
同步动态存储器SDRAM
双倍速率同步动态存储器DDR SDRAM
非易失性存储器
只读存储器(read only memory)ROM
- PROM:可编程ROM,只能编程一次,可以从0写成1,1写成0
- EPROM:可擦写可编程ROM
- EEPROM:电子可擦除PROM
访问主存
可寻址范围为0~2^36-1,即主存地址空间为64GB,主存地址空间地址不等于主存容量。
- 取址
- 取数
- 存数
总线
用来传输地址、数据和控制信号的一组平行的电线。
- 数据线
- 地址线
- 控制线
磁盘存储器
- 每面有一个磁头,寻道过程中所有磁头同时移动
- 磁盘上各磁道长度不同,每圈磁道容量相同
- 磁盘容量=字节数*平均扇区数*磁道数*表面数*盘片数
- 磁盘最小访问单元为扇区,所以磁盘采用成批数据交换方式进行读写,为直接访问存取(DMA)

数据总的访问时间=寻址时间+旋转延迟+传输时间
- 寻址时间:由物理因素限制,一般是3~9ms
- 旋转延迟:由转盘转速决定,一般是7200RPM
- 传输速度:需要读取的扇区数目。

例:假定每个扇区512字节, 磁盘转速为5400 RPM(每分钟多少转),声称寻道时间(最大寻道时间的一半)为12 ms, 数据传输率为4 MB/s, 磁盘控制器开销为1 ms,不考虑排队时间,则磁盘响应时间为多少?
磁盘响应时间= 排队时间 + 磁盘控制器开销 +寻道时间 + 旋转延迟( =磁盘转一圈的时间/2(因为不知道在哪,所以取平均半圈计算)) + 传输时间
= 0+ 1 ms + 12 ms + 0.5 / 5400 RPM + 0.5 KB / 4 MB/s
= 0 + 1 ms + 12 ms + 0.5 / 90 RPS + 0.125 / 1024 s
= 1 ms + 12 ms + 5.5 ms + 0.1 ms
= 18.6 ms
局部性
局部性保证了层次化存储结构的有效性。分为:
- 时间局部性:变量被访问多次
- 空间局部性:访问相邻元素
固态硬盘SSD
不是磁表面存储器,有闪存组成的外存系统,与U盘没区别,但容量更大,存储性能更好。
闪存是非易失性存储器。
读的操作比写快很多。最小存取单元为页。

高速缓存存储器cache
位于cpu芯片,由SRAM组成。在cpu与主存之间设置一个cache,存放经常使用的程序和数据。
cpu执行指令时产生访存要求。若cache命中,则无需访问内存读取数据。否则在cache中找一块空闲块,将AD地址处值送到cpu并复制到cache。
Cache映射
- 将内存分为大小相等内存块
- 将cache分为相等的cache行。(cache行数一般<主存块数)
- 使用分块技术能提高时间局限性
- 映射方式有3种
- 直接相连:每个主存块映射到固定cache行。cache行号=主存块号%cache行数。命中率低(当连续访问mod值相同的块时很不理想)。即E=1的组相连
- 全相连:每个主存块可映射到任一行
- 组相连:每个主存块可映射到固定组的任一行
[m,s,b,t,e]

- 若高速缓存存储器共M字节,即地址表示需m位:M=2^m
- 若分为S组则需s位表示:S=2^s
- e表示每个组分为几行。
- 每个块存储字节数为B,则偏置需要b位表示:B=2^b。(某次不命中从内存中加载时会将这个元素及其后连续的一些元素一起加载至填满一个块)
- t=m-s-b表示标志位
-
缓存中存放数据的空间大小为:C=S×E×B
cache容量
- 需要明确的是每行的数据区大小和主存块大小一样
- 将主存地址位划分为标记位+行索引+偏移
- 别忘了cache中有标记位1字节
- 注意K、M、G、T的换算依赖上下文。对于DRAM、SRAM容量相关单位是以2^10倍,而磁盘、网络这样的IO设备是以10^3
例:主存地址位数为32,块大小为16B,Cache的数据区容量为64KB,求cache容量
1、求标志位位数
行数=数据区容量64KB / 块大小16B = 2^12 , 则行索引位数为12,又块大小为16B,则偏移位数为4,所以标记位为32-12-12=16位
2、cache容量
V=2^12 * (1+16) /8B + 64 KB
平均访问时间T
设H是命中率,则平均访问时间T = HTC+ (1 - H)(TC+ TM)
= TC+ (1 - H)TM
Tc为cache访问时间,Tm为主存
读取

具体在从缓存中读取一个地址时,首先我们通过 set index 确定要在哪个 set 中寻找,确定后利用 tag 和同一个 set 中的每个 line 进行比对,找到 tag 相同的那个 line,最后再根据 block offset 确定要从 line 的哪个位置读起(这里的而 line 和 block 是一个意思)。如果 tag 不匹配的话,这行会被扔掉并放新的数据进来。
全相连高速缓存
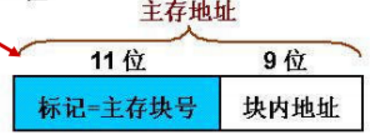
直接映射高速缓存
即E=1

一个tips:定义数组大小时不要用2的幂,应该多加B字节。以防对两个这样的数组按下标一次访问如乘时每次放完xi到高速缓存存储器就要再在这个位置放yi
N-路组相连高速缓存(每组N行)
- 将Cache所有行分组,把主存块映射到Cache固定组的任一行中。
- Cache组号=主存块号 mod Cache组数
- 使用分块技术能提高时间局限性

写入
在整个存储层级中,不同的层级可能会存放同一个数据的不同拷贝(如 L1, L2, L3, 主内存, 硬盘)。如果发生写入命中的时候(也就是要写入的地址在缓存中有),有两种策略:
- Write-through: 命中后更新缓存,同时写入到内存中
- Write-back: 直到这个缓存需要被置换出去,才写入到内存中(需要额外的 dirty bit 来表示缓存中的数据是否和内存中相同,因为可能在其他的时候内存中对应地址的数据已经更新,那么重复写入就会导致原有数据丢失)
在写入 miss 的时候,同样有两种方式:
- Write-allocate: 载入到缓存中,并更新缓存(如果之后还需要对其操作,这个方式就比较好)
- No-write-allocate: 直接写入到内存中,不载入到缓存
这四种策略通常的搭配是:
- Write-through + No-write-allocate
- Write-back + Write-allocate
其中第一种可以保证绝对的数据一致性,第二种效率会比较高(通常情况下)。















 1410
1410











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









