









目录
3.1 硬件中断入口 ixgbe_msix_clean_rings/ixgbe_intr
3.3.1 收包队列处理函数 ixgbe_clean_rx_irq
3.3.2 发包队列处理函数 ixgbe_clean_tx_irq
1 网卡队列收包流程概述
Ring Buffer 相关的接收报文过程大致如下:
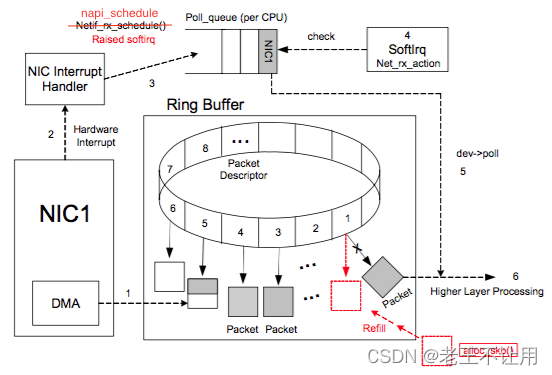
NIC (network interface card) 在系统启动过程中会向系统注册自己的各种信息,系统会分配 Ring Buffer 队列 也 会分配一块专门的内核内存区域给 NIC 用于存放传输上来的数据包。struct sk_buff 是专门存放各种网络传输数据包的内存接口,在收到数据存放到 NIC 专用内核内存区域后,sk_buff 内有个 data 指针会指向这块内存。Ring Buffer 队列内存放的是一个个 Packet Descriptor ,其有两种状态: ready 和 used 。初始时 Descriptor 是空的,指向一个空的 sk_buff,处在 ready 状态。当有数据时,DMA 负责从 NIC 取数据,并在 Ring Buffer 上按顺序找到下一个 ready 的 Descriptor,将数据存入该 Descriptor 指向的 sk_buff 中,并标记槽为 used。因为是按顺序找 ready 的槽,所以 Ring Buffer 是个 FIFO 的队列。
当 DMA 读完数据之后,NIC 会触发一个 IRQ 让 CPU 去处理收到的数据。因为每次触发 IRQ 后 CPU 都要花费时间去处理 Interrupt Handler,如果 NIC 每收到一个 Packet 都触发一个 IRQ 会导致 CPU 花费大量的时间在处理 Interrupt Handler,处理完后又只能从 Ring Buffer 中拿出一个 Packet,虽然 Interrupt Handler 执行时间很短,但这么做也非常低效,并会给 CPU 带去很多负担。所以目前都是采用一个叫做 New API(NAPI) 的机制,去对 IRQ 做合并以减少 IRQ 次数。
接下来介绍一下 NAPI 是怎么做到 IRQ 合并的。它主要是让 NIC 的 driver 能注册一个 poll 函数,之后 NAPI 的 subsystem 能通过 poll 函数去从 Ring Buffer 中批量拉取收到的数据。主要事件及其顺序如下:
- NIC driver 初始化时向 Kernel 注册
poll函数,用于后续从 Ring Buffer 拉取收到的数据 - driver 注册开启 NAPI,这个机制默认是关闭的,只有支持 NAPI 的 driver 才会去开启
- 收到数据后 NIC 通过 DMA 将数据存到内存
- NIC 触发一个 IRQ,并触发 CPU 开始执行 driver 注册的 Interrupt Handler
- driver 的 Interrupt Handler 通过 napi_schedule 函数触发 softirq (NET_RX_SOFTIRQ) 来唤醒 NAPI subsystem,NET_RX_SOFTIRQ 的 handler 是 net_rx_action 会在另一个线程中被执行,在其中会调用 driver 注册的 poll 函数获取收到的 Packet
- driver 会禁用当前 NIC 的 IRQ,从而能在
poll完所有数据之前不会再有新的 IRQ - 当所有事情做完之后,NAPI subsystem 会被禁用,并且会重新启用 NIC 的 IRQ
- 回到第三步
从上面的描述可以看出来还缺一些东西,Ring Buffer 上的数据被 poll 走之后是怎么交付上层网络栈继续处理的呢?以及被消耗掉的 sk_buff 是怎么被重新分配重新放入 Ring Buffer 的呢?这两个工作都在 poll 中完成,详解见下文中的 ixgbe_poll 分析。以上参见《Linux 网络协议栈收消息过程-Ring Buffer》
关于NIC上数据包内存 sk_buff 的分配形式,这里多说两句,上图显示 sk_buff 通过直接调接口 alloc_skb() 从内核中分配,然后调用 dma_map_single() 将 skb->data 的指针映射出 DMA 地址 以便 NIC的DMA引擎直接将收到的数据包存入sk->data内存中,poll 函数取走 Packet Descriptor 中的sk_buff 交给是上层协议栈,同时为已经读取过的 Packet Descriptor 分配新的sk_buff。
除此之外在 ixgbe_poll 驱动代码中可知 Ring Buffer 中 Descriptor(ixgbe_rx_buffer、igb_rx_buffer) 的数据包存储区域是是通过分配物理页page,并建立通过 dma_map_page_attrs() 建立dma映射,NIC的DMA引擎直接将收到的数据包存入page中,poll通过新申请一个sk_buff 将page中存放的网络数据拷贝出来,然后将sk_buff丢给协议栈处理 。详解见 ixgbe_alloc_rx_buffers() / igb_alloc_rx_buffers() 代码分析。
2 ixgbe_ring 结构
struct ixgbe_ring {
struct ixgbe_ring *next; /* pointer to next ring in q_vector */
struct ixgbe_q_vector *q_vector; /* backpointer to host q_vector */
struct net_device *netdev; /* netdev ring belongs to */
struct bpf_prog *xdp_prog;
struct device *dev; /* device for DMA mapping */
struct ixgbe_fwd_adapter *l2_accel_priv;
void *desc; /* descriptor ring memory */
union {
struct ixgbe_tx_buffer *tx_buffer_info;
struct ixgbe_rx_buffer *rx_buffer_info;
};
unsigned long state;
u8 __iomem *tail;
dma_addr_t dma; /* phys. address of descriptor ring */
unsigned int size; /* length in bytes */
u16 count; /* amount of descriptors */
u8 queue_index; /* needed for multiqueue queue management */
u8 reg_idx; /* holds the special value that gets
* the hardware register offset
* associated with this ring, which is
* different for DCB and RSS modes
*/
u16 next_to_use;
u16 next_to_clean;
unsigned long last_rx_timestamp;
union {
u16 next_to_alloc;
struct {
u8 atr_sample_rate;
u8 atr_count;
};
};
u8 dcb_tc;
struct ixgbe_queue_stats stats;
struct u64_stats_sync syncp;
union {
struct ixgbe_tx_queue_stats tx_stats;
struct ixgbe_rx_queue_stats rx_stats;
};
} ____cacheline_internodealigned_in_smp;
struct ixgbe_rx_buffer {
struct sk_buff *skb;
dma_addr_t dma;
struct page *page;
#if (BITS_PER_LONG > 32) || (PAGE_SIZE >= 65536)
__u32 page_offset;
#else
__u16 page_offset;
#endif
__u16 pagecnt_bias;
};
结构框图

3 ixgbe 驱动收包流程
3.1 硬件中断入口 ixgbe_msix_clean_rings/ixgbe_intr
ixgbe_msix_clean_rings()/ixgbe_intr()
--napi_schedule_irqoff()
--__napi_schedule_irqoff()
--____napi_schedule
-- __raise_softirq_irqoff(NET_RX_SOFTIRQ);
static irqreturn_t ixgbe_msix_clean_rings(int irq, void *data)
{
struct ixgbe_q_vector *q_vector = data;
/* EIAM disabled interrupts (on this vector) for us */
if (q_vector->rx.ring || q_vector->tx.ring)
napi_schedule_irqoff(&q_vector->napi);
return IRQ_HANDLED;
}
/**
* ixgbe_intr - legacy mode Interrupt Handler
* @irq: interrupt number
* @data: pointer to a network interface device structure
**/
static irqreturn_t ixgbe_intr(int irq, void *data)
{
struct ixgbe_adapter *adapter = data;
struct ixgbe_hw *hw = &adapter->hw;
struct ixgbe_q_vector *q_vector = adapter->q_vector[0];
u32 eicr;
/*
* Workaround for silicon errata #26 on 82598. Mask the interrupt
* before the read of EICR.
*/
IXGBE_WRITE_REG(hw, IXGBE_EIMC, IXGBE_IRQ_CLEAR_MASK);
/* for NAPI, using EIAM to auto-mask tx/rx interrupt bits on read
* therefore no explicit interrupt disable is necessary */
eicr = IXGBE_READ_REG(hw, IXGBE_EICR);
if (!eicr) {
/*
* shared interrupt alert!
* make sure interrupts are enabled because the read will
* have disabled interrupts due to EIAM
* finish the workaround of silicon errata on 82598. Unmask
* the interrupt that we masked before the EICR read.
*/
if (!test_bit(__IXGBE_DOWN, &adapter->state))
ixgbe_irq_enable(adapter, true, true);
return IRQ_NONE; /* Not our interrupt */
}
if (eicr & IXGBE_EICR_LSC)
ixgbe_check_lsc(adapter);
switch (hw->mac.type) {
case ixgbe_mac_82599EB:
ixgbe_check_sfp_event(adapter, eicr);
/* Fall through */
case ixgbe_mac_X540:
case ixgbe_mac_X550:
case ixgbe_mac_X550EM_x:
case ixgbe_mac_x550em_a:
if (eicr & IXGBE_EICR_ECC) {
e_info(link, "Received ECC Err, initiating reset\n");
set_bit(__IXGBE_RESET_REQUESTED, &adapter->state);
ixgbe_service_event_schedule(adapter);
IXGBE_WRITE_REG(hw, IXGBE_EICR, IXGBE_EICR_ECC);
}
ixgbe_check_overtemp_event(adapter, eicr);
break;
default:
break;
}
ixgbe_check_fan_failure(adapter, eicr);
if (unlikely(eicr & IXGBE_EICR_TIMESYNC))
ixgbe_ptp_check_pps_event(adapter);
/* would disable interrupts here but EIAM disabled it */
napi_schedule_irqoff(&q_vector->napi);
/*
* re-enable link(maybe) and non-queue interrupts, no flush.
* ixgbe_poll will re-enable the queue interrupts
*/
if (!test_bit(__IXGBE_DOWN, &adapter->state))
ixgbe_irq_enable(adapter, false, false);
return IRQ_HANDLED;
}
3.2 软中断入口 net_rx_action
在软中断函数中调用注册的 poll 函数:
net_rx_action()
--napi_poll()
--ixgbe_poll()
--ixgbe_clean_tx_irq()
--ixgbe_clean_rx_irq()
static __latent_entropy void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
unsigned long time_limit = jiffies +
usecs_to_jiffies(netdev_budget_usecs);
int budget = netdev_budget;
LIST_HEAD(list);
LIST_HEAD(repoll);
local_irq_disable();
list_splice_init(&sd->poll_list, &list);
local_irq_enable();
for (;;) {
struct napi_struct *n;
if (list_empty(&list)) {
if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll))
goto out;
break;
}
n = list_first_entry(&list, struct napi_struct, poll_list);
budget -= napi_poll(n, &repoll);
/* If softirq window is exhausted then punt.
* Allow this to run for 2 jiffies since which will allow
* an average latency of 1.5/HZ.
*/
if (unlikely(budget <= 0 ||
time_after_eq(jiffies, time_limit))) {
sd->time_squeeze++;
break;
}
}
local_irq_disable();
list_splice_tail_init(&sd->poll_list, &list);
list_splice_tail(&repoll, &list);
list_splice(&list, &sd->poll_list);
if (!list_empty(&sd->poll_list))
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
net_rps_action_and_irq_enable(sd);
out:
__kfree_skb_flush();
}3.2.1 调用 poll
poll 函数通过netif_napi_add注册,以回调函数形式被调用。读取buffer中到skb以及buffer内存的循环分配,以及XDP的作用位置,以及交由协议栈处理的动作都在本函数中。 该函数是个 driver 实现的函数,该所以每个 driver 实现可能都不相同。但流程基本是一致的:
- 从 Ring Buffer 中将收到的 sk_buff 读取出来
- 对 sk_buff 做一些基本检查,可能会涉及到将几个 sk_buff 合并因为可能同一个 Frame 被分散放在多个 sk_buff 中
- 将 sk_buff 交付上层网络栈处理
- 清理 sk_buff,清理 Ring Buffer 上的 Descriptor 将其指向新分配的 sk_buff 并将状态设置为 ready
- 更新一些统计数据,比如收到了多少 packet,一共多少字节等
下一小节以 ixgbe_poll 为例,详解说明 poll 流程。
static int napi_poll(struct napi_struct *n, struct list_head *repoll)
{
void *have;
int work, weight;
list_del_init(&n->poll_list);
have = netpoll_poll_lock(n);
weight = n->weight;//获取单次读取最大报文个数
/* This NAPI_STATE_SCHED test is for avoiding a race
* with netpoll's poll_napi(). Only the entity which
* obtains the lock and sees NAPI_STATE_SCHED set will
* actually make the ->poll() call. Therefore we avoid
* accidentally calling ->poll() when NAPI is not scheduled.
*/
work = 0;
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight); // 调用驱动注册函数ixgbe_poll
trace_napi_poll(n, work, weight);
}
WARN_ON_ONCE(work > weight);
if (likely(work < weight))
goto out_unlock;
/* Drivers must not modify the NAPI state if they
* consume the entire weight. In such cases this code
* still "owns" the NAPI instance and therefore can
* move the instance around on the list at-will.
*/
if (unlikely(napi_disable_pending(n))) {
napi_complete(n);
goto out_unlock;
}
if (n->gro_list) {
/* flush too old packets
* If HZ < 1000, flush all packets.
*/
napi_gro_flush(n, HZ >= 1000);
}
/* Some drivers may have called napi_schedule
* prior to exhausting their budget.
*/
if (unlikely(!list_empty(&n->poll_list))) {
pr_warn_once("%s: Budget exhausted after napi rescheduled\n",
n->dev ? n->dev->name : "backlog");
goto out_unlock;
}
list_add_tail(&n->poll_list, repoll);
out_unlock:
netpoll_poll_unlock(have);
return work;
}3.3 注册poll函数 ixgbe_poll
其中处理TX的函数是ixgbe_clean_tx_irq,处理首包RX的函数是ixgbe_clean_tx_irq。发消息先不管,先看收消息,收消息走的是ixgbe_clean_rx_irq。收完消息后执行 napi_complete_done 退出 polling 模式,并开启 NIC 的 IRQ。
/**
* ixgbe_poll - NAPI Rx polling callback
* @napi: structure for representing this polling device
* @budget: how many packets driver is allowed to clean
*
* This function is used for legacy and MSI, NAPI mode
**/
int ixgbe_poll(struct napi_struct *napi, int budget)
{
struct ixgbe_q_vector *q_vector =
container_of(napi, struct ixgbe_q_vector, napi);
struct ixgbe_adapter *adapter = q_vector->adapter;
struct ixgbe_ring *ring;
int per_ring_budget, work_done = 0;
bool clean_complete = true;
#ifdef CONFIG_IXGBE_DCA
if (adapter->flags & IXGBE_FLAG_DCA_ENABLED)
ixgbe_update_dca(q_vector);
#endif
ixgbe_for_each_ring(ring, q_vector->tx) {//依次处理发送队列
if (!ixgbe_clean_tx_irq(q_vector, ring, budget))
clean_complete = false;
}
/* Exit if we are called by netpoll */
if (budget <= 0)
return budget;
/* attempt to distribute budget to each queue fairly, but don't allow
* the budget to go below 1 because we'll exit polling */
if (q_vector->rx.count > 1)
per_ring_budget = max(budget/q_vector->rx.count, 1);
else
per_ring_budget = budget;
ixgbe_for_each_ring(ring, q_vector->rx) {//依次处理接收队列
int cleaned = ixgbe_clean_rx_irq(q_vector, ring,
per_ring_budget);
work_done += cleaned;
if (cleaned >= per_ring_budget)
clean_complete = false;
}
/* If all work not completed, return budget and keep polling */
if (!clean_complete)
return budget;
/* all work done, exit the polling mode */
if (likely(napi_complete_done(napi, work_done))) {
if (adapter->rx_itr_setting & 1)
ixgbe_set_itr(q_vector);
if (!test_bit(__IXGBE_DOWN, &adapter->state))
ixgbe_irq_enable_queues(adapter,
BIT_ULL(q_vector->v_idx));
}
return min(work_done, budget - 1);
}
3.3.1 收包队列处理函数 ixgbe_clean_rx_irq
从而我们知道大部分工作是在 ixgbe_clean_rx_irq 中完成的,其实现大致上还是比较清晰的,就是上面描述的几步。里面有个 while 循环通过 buget 控制,从而在 Packet 特别多的时候不要让 CPU 在这里无穷循环下去,要让别的事情也能够被执行。循环内做的事情如下:
- 先清理已经读取过的rx_buffer,并以此分配一批新的的rx_buffer(①分配物理页;② 建立dma映射),从而避免每次读一个 sk_buff 就清理一个,很低效。
- 通过next_to_clean在IXGBE_RX_DESC宏中找到 Ring Buffer 中下一个需要被读取的 Descriptor ,并检查描述符状态是否正常
- 根据 Descriptor 找到rx_buffer读出来
- 根据bfp携带的act,通过xdp对数据进行处理
- 根据不同情况,通过ixgbe_build_skb或者ixgbe_construct_skb创建skb,保存rx_buffer->page内的数据。前者的创建函数build_skb,后者的创建函数是napi_alloc_skb,(skb)向上层提交数据以后,这段内存将始终被这个skb占用(直到上层处理完以后才会调用__kfree_skb释放,但已经跟这里没有关系了)。
- 通过ixgbe_put_rx_buffer函数将本次处理的buffer内存释放
- 检查是否是 End of packet,是的话说明skb内有 Frame 的全部内容,不是的话说明 Frame 数据比skb大,将该skb放入到下一次待处理的的buffer中进行处理
- 通过 Frame 的 Header 检查 Frame 数据完整性,是否正确之类的
- 记录skb的长度,读了多少数据
- 设置 Hash、checksum、timestamp、VLAN id 等信息,这些信息是硬件提供的。
- 通过ixgbe_rx_skb函数中的napi_gro_receive将 skb 交付上层网络栈
- 更新一堆统计数据
- 回到 1,如果没数据或者 budget 不够就退出循环
budget 会影响到 CPU 执行 poll 的时间,budget 越大当数据包特别多的时候,可以提高 CPU 利用率并减少数据包的延迟。但是 CPU 时间都花在这里会影响别的任务的执行。
budget 默认 300,可以调整sysctl -w net.core.netdev_budget=600
napi_gro_receive会涉及到 GRO 机制,稍后再说,大致上就是会对多个数据包做聚合,napi_gro_receive 最终是将处理好的 sk_buff 通过调用 netif_receive_skb,将数据包送至上层网络栈。执行完 GRO 之后,基本可以认为数据包正式离开 Ring Buffer,进入下一个阶段了。在记录下一阶段的处理之前,补充一下收消息阶段 Ring Buffer 相关的更多细节。
/**
* ixgbe_clean_rx_irq - Clean completed descriptors from Rx ring - bounce buf
* @q_vector: structure containing interrupt and ring information
* @rx_ring: rx descriptor ring to transact packets on
* @budget: Total limit on number of packets to process
*
* This function provides a "bounce buffer" approach to Rx interrupt
* processing. The advantage to this is that on systems that have
* expensive overhead for IOMMU access this provides a means of avoiding
* it by maintaining the mapping of the page to the syste.
*
* Returns amount of work completed
**/
static int ixgbe_clean_rx_irq(struct ixgbe_q_vector *q_vector,
struct ixgbe_ring *rx_ring,
const int budget)
{
unsigned int total_rx_bytes = 0, total_rx_packets = 0;
struct ixgbe_adapter *adapter = q_vector->adapter;
#ifdef IXGBE_FCOE
int ddp_bytes;
unsigned int mss = 0;
#endif /* IXGBE_FCOE */
//ring中剩余的size
u16 cleaned_count = ixgbe_desc_unused(rx_ring);
unsigned int xdp_xmit = 0;
struct xdp_buff xdp;
xdp.rxq = &rx_ring->xdp_rxq;
while (likely(total_rx_packets < budget)) {
union ixgbe_adv_rx_desc *rx_desc;
struct ixgbe_rx_buffer *rx_buffer;
struct sk_buff *skb;
unsigned int size;
/* return some buffers to hardware, one at a time is too slow */
if (cleaned_count >= IXGBE_RX_BUFFER_WRITE) {
//一次性为ring中分配新的rx buffer内存空间,用以接受rx_ring中skb数据,避免每释放1个,就申请1个。
//结构体是struct ixgbe_rx_buffer,并将地址放在rx_desc中。
ixgbe_alloc_rx_buffers(rx_ring, cleaned_count);
cleaned_count = 0;
}
//找到 Ring Buffer 上下一个需要被读取的 Descriptor ,并检查描述符状态是否正常
rx_desc = IXGBE_RX_DESC(rx_ring, rx_ring->next_to_clean);
size = le16_to_cpu(rx_desc->wb.upper.length);
if (!size)
break;
/* This memory barrier is needed to keep us from reading
* any other fields out of the rx_desc until we know the
* descriptor has been written back
*/
dma_rmb();
//获取ring中的rx_buffer,以及buffer中的skb
//正常情况下,buffer中应该是没有skb的,如果存在,说明该skb不是最后一个packet(eop)或者被分片的数据,导致没有被上一次buffer处理
//而被放到本次流程中处理。涉及的函数是ixgbe_add_rx_frag和ixgbe_is_non_eop
rx_buffer = ixgbe_get_rx_buffer(rx_ring, rx_desc, &skb, size);
/* retrieve a buffer from the ring */
if (!skb) {
xdp.data = page_address(rx_buffer->page) +
rx_buffer->page_offset;
xdp.data_meta = xdp.data;
xdp.data_hard_start = xdp.data -
ixgbe_rx_offset(rx_ring);
xdp.data_end = xdp.data + size;
//根据bfp携带的act,通过xdp对数据进行处理
skb = ixgbe_run_xdp(adapter, rx_ring, &xdp);
}
if (IS_ERR(skb)) {
unsigned int xdp_res = -PTR_ERR(skb);
if (xdp_res & (IXGBE_XDP_TX | IXGBE_XDP_REDIR)) {
xdp_xmit |= xdp_res;
ixgbe_rx_buffer_flip(rx_ring, rx_buffer, size);
} else {
rx_buffer->pagecnt_bias++;
}
total_rx_packets++;
total_rx_bytes += size;
} else if (skb) {
//该函数是将rx_buffer->page加到skb中,当buffer的size小于skb的头,就将rx_buffer->page拷贝加到skb中。
//否则仅会将rx_buffer->page作为一个分片frag放到skb中,待下个frag来之后再处理。
//不过为什么当size大于skb头的时候,会将该page以frag方式加入到skb中?这里应该有分片的逻辑,没有看懂。
ixgbe_add_rx_frag(rx_ring, rx_buffer, skb, size);
} else if (ring_uses_build_skb(rx_ring)) {
//通过ixgbe_build_skb或者ixgbe_construct_skb创建skb,保存rx_buffer->page内的数据。
//前者的创建函数build_skb,后者的创建函数是napi_alloc_skb
skb = ixgbe_build_skb(rx_ring, rx_buffer,
&xdp, rx_desc);
} else {
skb = ixgbe_construct_skb(rx_ring, rx_buffer,
&xdp, rx_desc);
}
/* exit if we failed to retrieve a buffer */
if (!skb) {
rx_ring->rx_stats.alloc_rx_buff_failed++;
rx_buffer->pagecnt_bias++;
break;
}
//rx_buffer回收,在这里清空rx_buffer
ixgbe_put_rx_buffer(rx_ring, rx_buffer, skb);
cleaned_count++;
/* place incomplete frames back on ring for completion */
//确认当前的buffer是否是是该数据帧的最后一个packet(eop,end of packet)
//如果不是的话,则继续并将两个skb合并起来,并将该skb放到下一次buffer中进行处理,结构体为rx_buffer_info[ntc].skb。
if (ixgbe_is_non_eop(rx_ring, rx_desc, skb))
continue;
/* verify the packet layout is correct */
//检查完整性
if (ixgbe_cleanup_headers(rx_ring, rx_desc, skb))
continue;
/* probably a little skewed due to removing CRC */
total_rx_bytes += skb->len;
/* populate checksum, timestamp, VLAN, and protocol */
//设置 Hash、checksum、timestamp、VLAN id 等信息,这些信息是硬件提供的。
ixgbe_process_skb_fields(rx_ring, rx_desc, skb);
#ifdef IXGBE_FCOE
/* if ddp, not passing to ULD unless for FCP_RSP or error */
if (ixgbe_rx_is_fcoe(rx_ring, rx_desc)) {
ddp_bytes = ixgbe_fcoe_ddp(adapter, rx_desc, skb);
/* include DDPed FCoE data */
if (ddp_bytes > 0) {
if (!mss) {
mss = rx_ring->netdev->mtu -
sizeof(struct fcoe_hdr) -
sizeof(struct fc_frame_header) -
sizeof(struct fcoe_crc_eof);
if (mss > 512)
mss &= ~511;
}
total_rx_bytes += ddp_bytes;
total_rx_packets += DIV_ROUND_UP(ddp_bytes,
mss);
}
if (!ddp_bytes) {
dev_kfree_skb_any(skb);
continue;
}
}
#endif /* IXGBE_FCOE */
//通过该函数将skb交由上层网络协议栈处理
ixgbe_rx_skb(q_vector, skb);
/* update budget accounting */
total_rx_packets++;
}
if (xdp_xmit & IXGBE_XDP_REDIR)
xdp_do_flush_map();
if (xdp_xmit & IXGBE_XDP_TX) {
struct ixgbe_ring *ring = adapter->xdp_ring[smp_processor_id()];
/* Force memory writes to complete before letting h/w
* know there are new descriptors to fetch.
*/
wmb();
writel(ring->next_to_use, ring->tail);
}
u64_stats_update_begin(&rx_ring->syncp);
rx_ring->stats.packets += total_rx_packets;
rx_ring->stats.bytes += total_rx_bytes;
u64_stats_update_end(&rx_ring->syncp);
q_vector->rx.total_packets += total_rx_packets;
q_vector->rx.total_bytes += total_rx_bytes;
return total_rx_packets;
}

















 3119
3119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









