







一、前言
Linux收发包是操作系统内核和驱动常规事务,本文是基于4.19内核和对应的ixgbe驱动进行的收包流程梳理。ixgbe是intel一款标准驱动,其中82599系列万兆网卡就是使用该驱动。
二、总体介绍
NIC (network interface card) 在系统启动过程中会通过ixgbe_open函数向系统注册自己的各种信息,系统会根据queue的size和number等信息分配 Ring Buffer 队列和驱动的内存资源,其中DMA的内存资源就是在该函数中通过ixgbe_setup_all_rx_resources和ixgbe_setup_all_tx_resources分配,再通过ixgbe_request_irq中断给网卡。
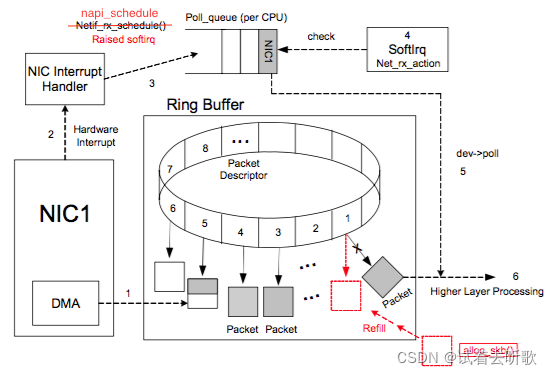
Ring Buffer 队列内存放的是一个个 Packet Descriptor ,其有两种状态: ready 和 used 。初始时 Descriptor 是空的,指向一个空的 skb,处在 ready 状态。
当有数据时,DMA 负责从 NIC 取数据放到 Ring Buffer 中,当 DMA 读完数据之后,NIC 会触发一个 IRQ 让 CPU 去处理收到的数据。因为每次触发 IRQ 后 CPU 都要花费时间去处理 Interrupt Handler,如果 NIC 每收到一个 Packet 都触发一个 IRQ 会导致 CPU 花费大量的时间在处理 Interrupt Handler,处理完后又只能从 Ring Buffer 中拿出一个 Packet,虽然 Interrupt Handler 执行时间很短,但这么做也非常低效,并会给 CPU 带去很多负担。所以目前都是采用一个叫做 New API(NAPI) 的机制,去对 IRQ 做合并以减少 IRQ 次数。
IRQ软中断在 Ring Buffer 上按顺序找到下一个 ready 的 Descriptor,**将数据存入该 Descriptor 指向的 sk_buff 中,并标记槽为 used。**因为是按顺序找 ready 的槽,所以 Ring Buffer 是个 FIFO 的队列。
Ring Buffer 相关的收消息过程大致如下:
图片来自参考1,对 raise softirq 的函数名做了修改,改为了 napi_schedule
三、代码解析
接下来介绍一下 NAPI 是怎么做到 IRQ 合并的。它主要是让 NIC 的 driver 能注册一个 poll 函数,之后 NAPI 的 subsystem 能通过 poll 函数去从 Ring Buffer 中批量拉取收到的数据。主要事件及其顺序如下:
1、NIC driver 初始化时向 Kernel 注册 poll 函数,用于后续从 Ring Buffer 拉取收到的数据
2、driver 注册开启 NAPI,这个机制默认是关闭的,只有支持 NAPI 的 driver 才会去开启
3、收到数据后 NIC 通过 DMA 将数据存到内存
4、NIC 触发一个 IRQ,并触发 CPU 开始执行 driver 注册的 Interrupt Handler
5、driver 的 Interrupt Handler 通过 napi_schedule 函数触发 softirq (NET_RX_SOFTIRQ) 来唤醒 NAPI 6、subsystem,NET_RX_SOFTIRQ 的 handler 是 net_rx_action 会在另一个线程中被执行,在其中会7、调用 driver 注册的 poll 函数获取收到的 Packet
8、driver 会禁用当前 NIC 的 IRQ,从而能在 poll 完所有数据之前不会再有新的 IRQ
当所有事情做完之后,NAPI subsystem 会被禁用,并且会重新启用 NIC 的 IRQ
回到第三步
下面重点介绍pool函数,该函数通过netif_napi_add注册,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









